对抗知识焦虑,从看懂这条开始
App 下载
AI读懂模糊记忆,帮失散家庭找回家
家庭团聚|模糊记忆匹配|寻亲平台|EverOS语义记忆引擎|认知决策|AI产业应用|心理认知|人工智能
对抗知识焦虑,从看懂这条开始
App 下载家庭团聚|模糊记忆匹配|寻亲平台|EverOS语义记忆引擎|认知决策|AI产业应用|心理认知|人工智能
当一位父亲在寻亲平台写下“女儿三岁走失,爱趴在裁缝铺阳台看火车,左手腕有疤”,另一边的陌生女人模糊记得“小时候家里总有缝纫机响,窗外好像有铁轨,手上曾有个印记”——这两段看似无关的文字,却被AI揪出了藏在缝隙里的关联。全球有数百万家庭困在失散的等待里,传统寻亲卡在DNA样本的门槛、照片比对的误差,还有那些被时间揉碎的记忆里。而这套能在模糊、矛盾甚至错误的描述里找真相的AI,靠的不是关键词匹配,而是一套能“读懂记忆”的语义引擎。
EverOS语义记忆引擎,就是这套系统的核心——你可以把它理解成一个模仿人类大脑的“记忆收纳箱”,只不过它会把每段描述拆成一个个带意义的“小格子”。父亲的文字会被拆解成“人物关系:父女”“身体特征:左手腕疤痕”“日常场景:裁缝铺阳台看火车”等语义单元,每个单元都被转换成一串能代表其深层含义的数字向量,就像给每个记忆碎片贴了一张精准的“语义条形码”。

这和我们平时用的关键词搜索完全不同。当女人提到“缝纫机的声音”,系统不会死磕“裁缝铺”这三个字,而是能理解“缝纫机声”和“裁缝铺”指向的是同一个生活场景;“窗外的铁轨”和“阳台看火车”在语义向量空间里,本来就是挨在一起的邻居。它要找的不是字面上的重合,而是藏在文字背后的、属于同一个家庭的生活逻辑。
系统会在父母和寻亲者的两个记忆库之间双向搜索,结合语义相似度和关键词匹配加权排序,给出最可能的匹配候选。更关键的是,它能容忍错误:父亲记错了疤痕的位置,女人把铁轨记成了公路,这些偏差都不会直接阻断匹配——它要找的是记忆里的“家族特质”,而非精确的标准答案。
很多时候,寻亲者不是没有记忆,而是不知道自己还记得什么。一个3岁走失的孩子,成年后可能只模糊记得“家里有个总是转的东西”,却想不起那是缝纫机。这时候,平台内置的AI记忆引导助手就会上线——它不是瞎提问,而是会悄悄参考潜在匹配对象的信息,用温和的对话一点点撬开记忆的缝隙。
如果系统发现某个候选匹配的父亲是木匠,它会不经意问一句:“你小时候家里有没有木头的味道?”如果用户给出肯定回答,这段新记忆会立刻被补充进他的语义档案,匹配的权重也会随之提升。它会从感官、空间、人际关系等六个维度引导,比如问“你记得小时候常玩的地方有什么声音吗?”“有没有什么身体上的小印记你后来找不到了?”
这是一个双向生长的过程:用户想起的细节越多,AI的匹配就越精准;AI的提问越精准,用户想起的细节就越多。有位寻亲者原本只记得“小时候总吃一种甜饼”,在AI引导下,他慢慢想起甜饼是母亲用一种带花纹的铁模做的,而这个细节,刚好和另一个寻亲家庭的描述完全吻合——那是只有他们家才有的传家宝模具。
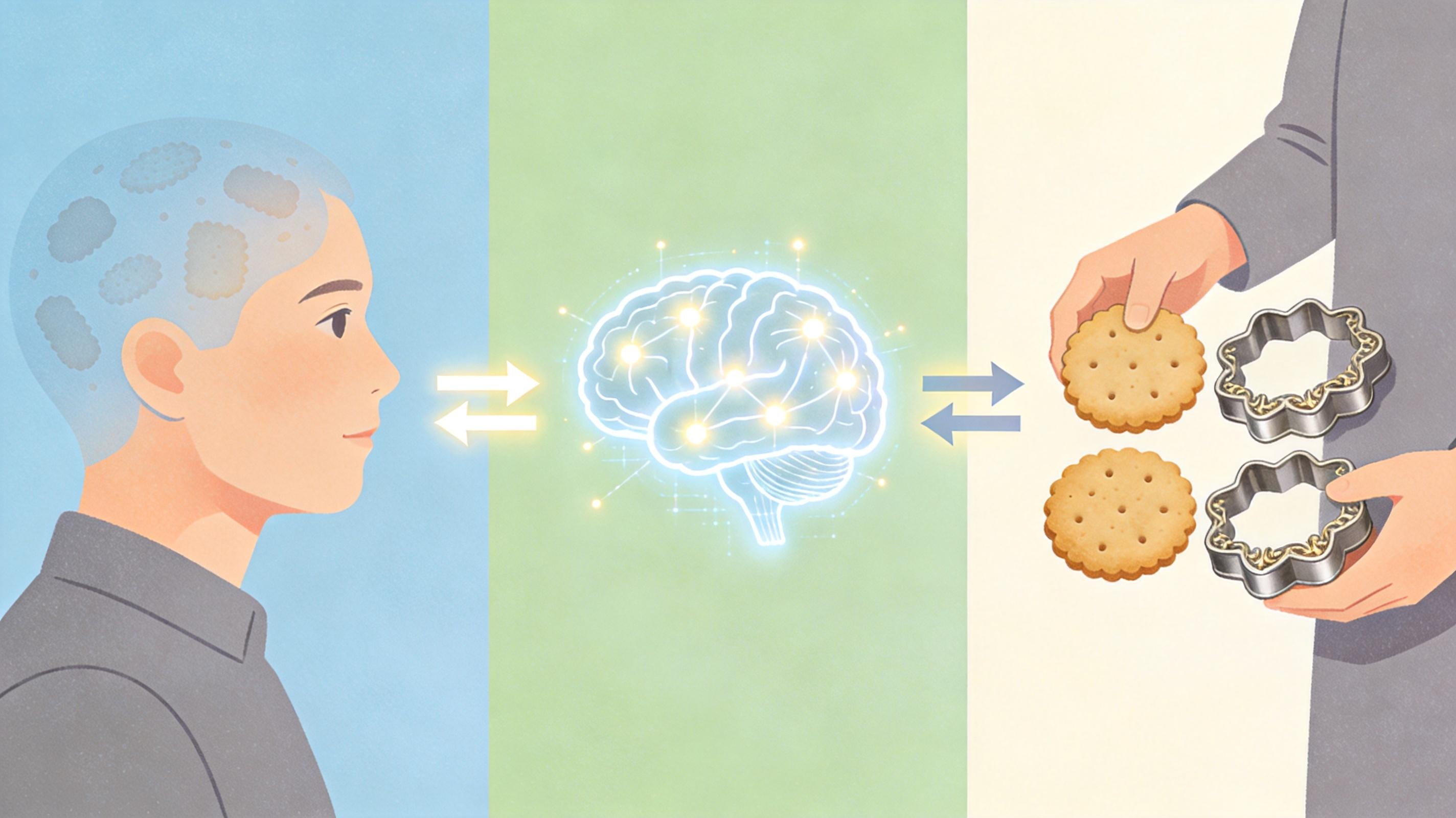
当然,这套系统也不是万能的。它目前最大的挑战,是如何区分“错误记忆”和“真实记忆”。比如有些寻亲者会把道听途说的细节当成自己的记忆,或者因为过度思念脑补出不存在的场景,这些“伪记忆”会干扰AI的判断。
数据隐私也是绕不开的坎。寻亲者的记忆里包含大量个人敏感信息,比如家庭地址、身体特征,一旦泄露可能带来安全风险。平台采用了多级权限控制和数据加密,但如何在开放数据提升匹配效率和保护隐私之间找到平衡,仍是需要持续打磨的问题。
更重要的是,AI只能提供匹配线索,最终的确认还需要DNA比对等传统手段。它不是要取代传统寻亲方式,而是要成为一个“线索挖掘机”——在那些被传统方法忽略的模糊地带,挖出可能的团聚希望。
在全球数百万失散家庭的等待里,时间是最残酷的变量——它会模糊记忆,扭曲细节,甚至让亲人变成陌生人。但AI语义记忆引擎做的,就是和时间对抗:它把那些被揉碎的记忆重新拼起来,把那些被遗忘的细节重新唤醒,让两个隔着十几年甚至几十年的人,能通过记忆的碎片认出彼此。
记忆不是冰冷的文字,是藏在细节里的温度——是缝纫机的嗡鸣,是阳台外的火车汽笛,是手腕上那道淡淡的疤。科技能做的,就是帮这些温度找到彼此。