
2 天前
2 天前
当你盯着一段“有人从瀑布跳下”的短视频,脑子里刚闪过画面,旁边的AI就敲出了准确的句子——不是关键词,是完整的描述:“一个人从山脊上的深瀑布跳下”。这不是科幻片里的桥段,是日本NTT团队2025年11月发布的真实实验结果。他们靠非侵入式的脑成像技术,把大脑里的视觉画面和回忆,直接翻译成了通顺的文字。更让人惊讶的是,这套系统甚至不需要依赖大脑里负责语言的区域。我们总说“人心隔肚皮”,现在,科技正在悄悄掀开这层“肚皮”的一角。
你可以把整个过程想象成“脑信号翻译局”的流水线:首先用功能性磁共振成像(fMRI)——一种靠测量脑区血氧变化间接捕捉神经活动的非侵入技术——记录下你看视频或回忆画面时的大脑信号,这就像是拿到了一份写满外星文字的密电。
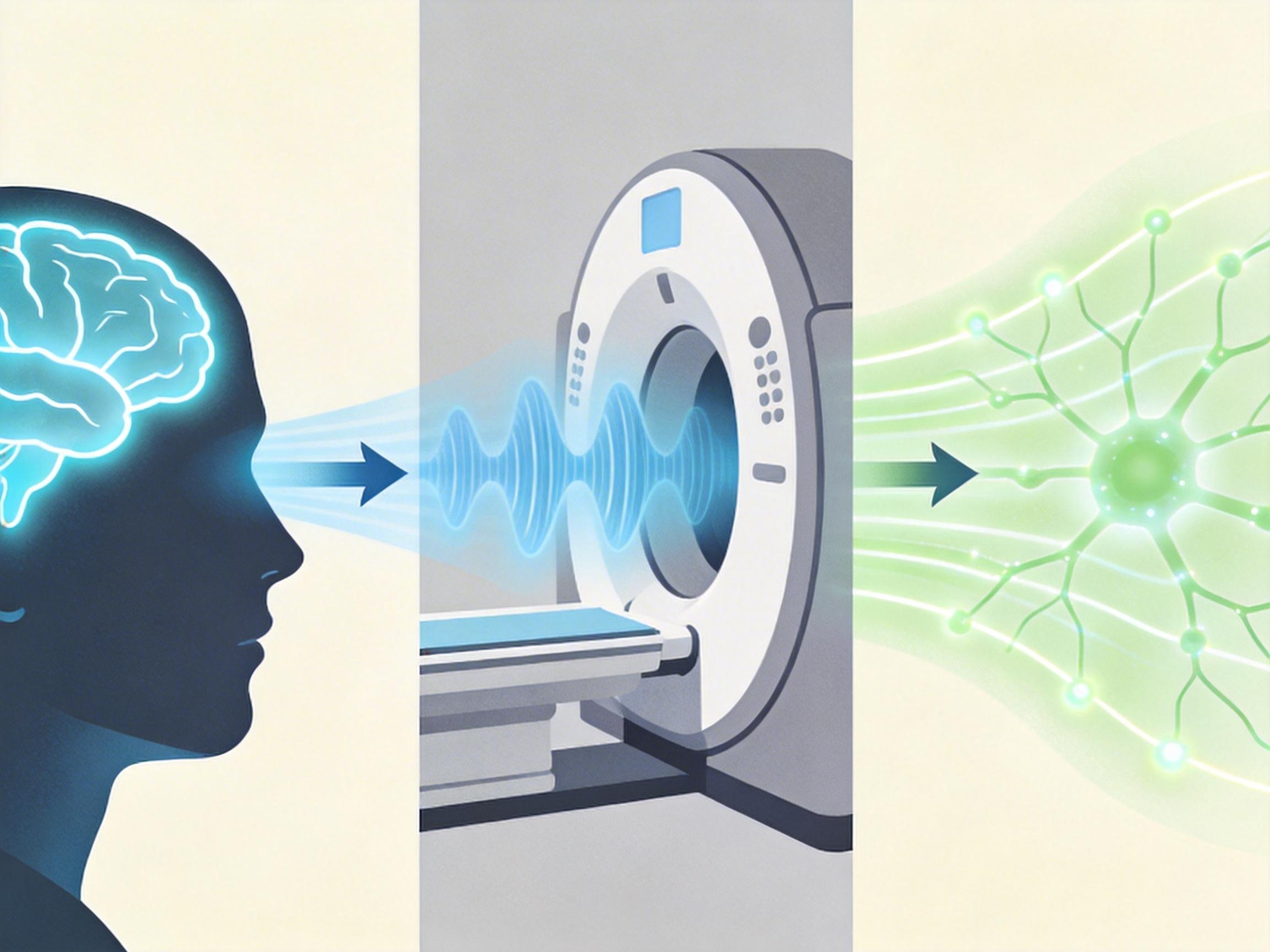
接下来是关键的两步:第一步,用深度语言模型把人类语言转换成一套统一的“语义密码”,比如“瀑布”“跳下”这些词,会对应成一串能被机器识别的特征向量;第二步,训练一个线性模型,把fMRI捕捉到的脑信号,映射到这套“语义密码”上。
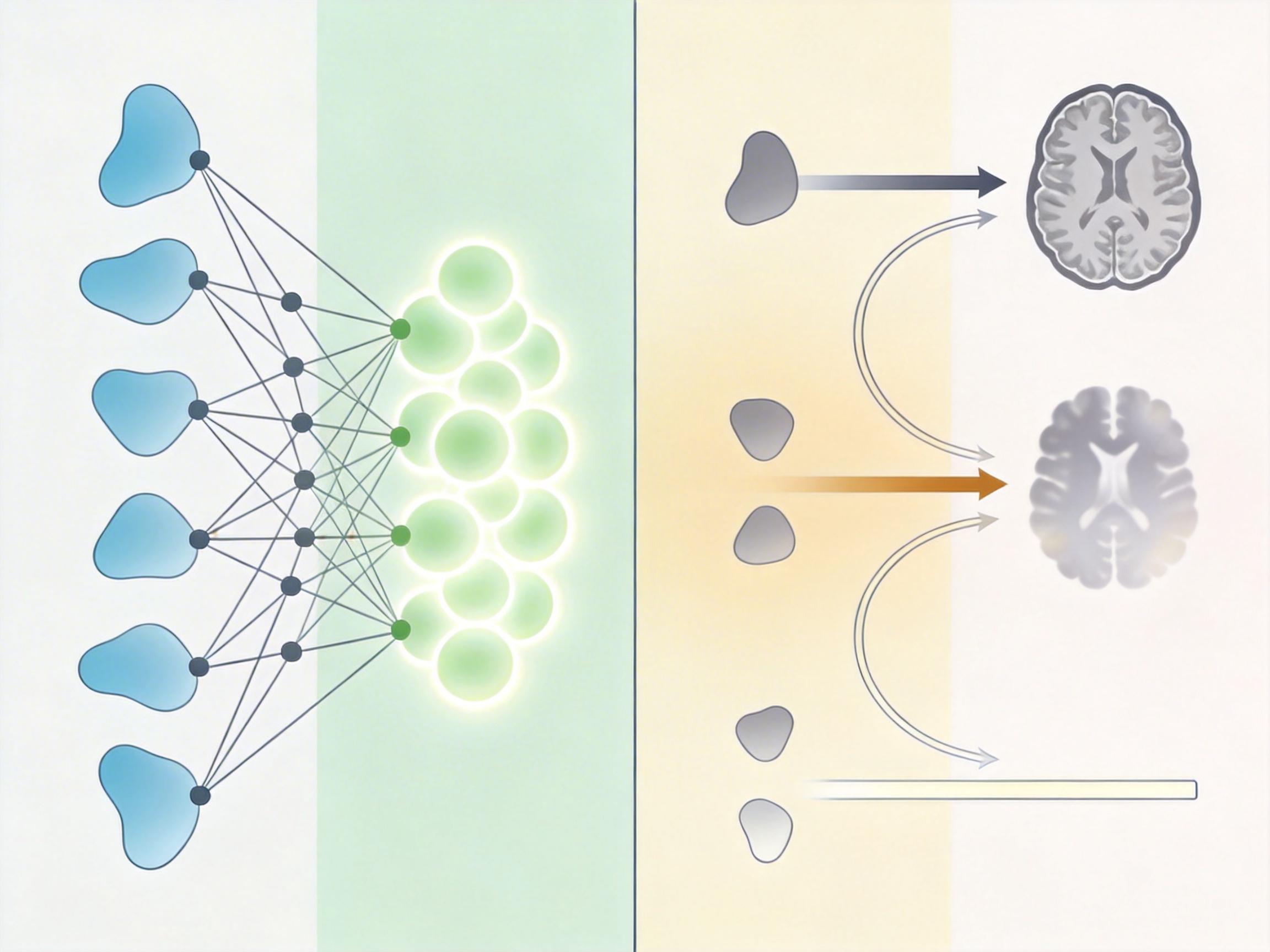
最后,再用蒙版语言模型反复优化:先给一句模糊的初始描述,然后像猜字谜一样,不断替换、插入词语,直到这句描述的“语义密码”和脑信号解码出的密码完全对齐。就像实验里的瀑布视频,AI从“泉水流动”开始猜,经过100次迭代,终于精准命中了画面核心。
但真实的机制比这个类比更精确:线性模型避免了过拟合,让解码过程更稳定;预训练的深度语言模型自带人类语言的语义逻辑,不用从零开始学怎么组词造句。
这项研究最耐人寻味的发现,是它居然绕开了大脑的语言网络。过去科学家默认,要解码和语言相关的内容,必须依赖大脑里负责说话、理解语言的区域,但NTT团队的实验显示,就算排除这些区域的信号,AI依然能生成准确的描述。
这说明,我们大脑里的视觉画面、回忆场景,本身就带着结构化的语义——比如“人”“瀑布”“跳下”之间的关系,不是等我们要说话时才临时组合的,而是在感知和记忆的瞬间,就已经以某种形式存在于非语言脑区里了。这就像是我们脑子里先有了一幅画,语言只是给这幅画配的字幕,而不是画本身。
更重要的是,这套系统不仅能解码正在看的内容,还能解码回忆。当参与者在脑子里回想看过的视频时,AI生成的描述准确率依然能达到30%以上——远高于随机猜测的概率。这证明,我们看东西和记东西时,大脑用的是相似的神经表征,相当于找到了“感知”和“记忆”之间的共用密码本。
当我们为“失语症患者能重新沟通”的前景兴奋时,更该冷静下来看看技术的另一面。目前这套系统还需要参与者配合完成大量训练,跨个体解码的准确率极低,暂时没法“偷偷读心”,但技术的迭代速度永远快于我们的想象。
现在的问题已经不是“能不能读心”,而是“谁有权读”。你的回忆、你的想象,这些连自己都未必能说清的私密内容,会不会在未来某天变成可以被捕捉、被分析的数据?当脑信号和你的身份、行为数据结合,会不会生成比你自己更了解你的“神经画像”?
更现实的是,当前的法律还没跟上技术的脚步。现有的数据保护法规,大多针对文字、图像这类传统数据,却没考虑脑信号这种直接映射思维的敏感信息——它比你的聊天记录、浏览记录更接近“真实的你”。一旦数据泄露,后果可能比普通的隐私泄露严重得多。
我们总在说“科技向善”,但善与恶的边界,从来都不在技术本身,而在我们给技术画的红线里。NTT团队的研究,像是给我们打开了一扇通往大脑内部的门——门后有帮助失语者重新发声的希望,也有窥探思维隐私的风险。
技术会不断向前走,但我们不能只跟着技术跑。思维的隐私,是人类最后的私密领地。在让技术帮我们“表达”之前,我们得先学会怎么守护自己“不被表达”的权利。毕竟,不是所有脑子里的东西,都需要被翻译成文字。
点击充电,成为大圆镜下一个视频选题!