对抗知识焦虑,从看懂这条开始
App 下载
算力卡脖子时,中国AI找到了新破局点
流水线推理|代码生成|推理成本|工程重构|AI算力|人工智能
对抗知识焦虑,从看懂这条开始
App 下载流水线推理|代码生成|推理成本|工程重构|AI算力|人工智能
当海外开发者为了跑通一款AI模型,把Mac Studio和Mac Mini抢至全线断货时,没人会把这场硬件抢购潮,和“算力封锁”四个字联系起来。但事实是,这款能对标GPT-5.2的模型,恰恰是中国团队在算力受限的夹缝里,用极致的工程重构砸出来的缺口——它的推理成本只有国际顶级闭源模型的1/6,却能在代码生成、长任务执行上追平甚至超越对手。更重要的是,它不再依赖单一高端GPU,普通办公电脑就能扛下核心计算。这不是某款模型的胜利,而是一场关于“如何用最少算力,做最多事”的革命。
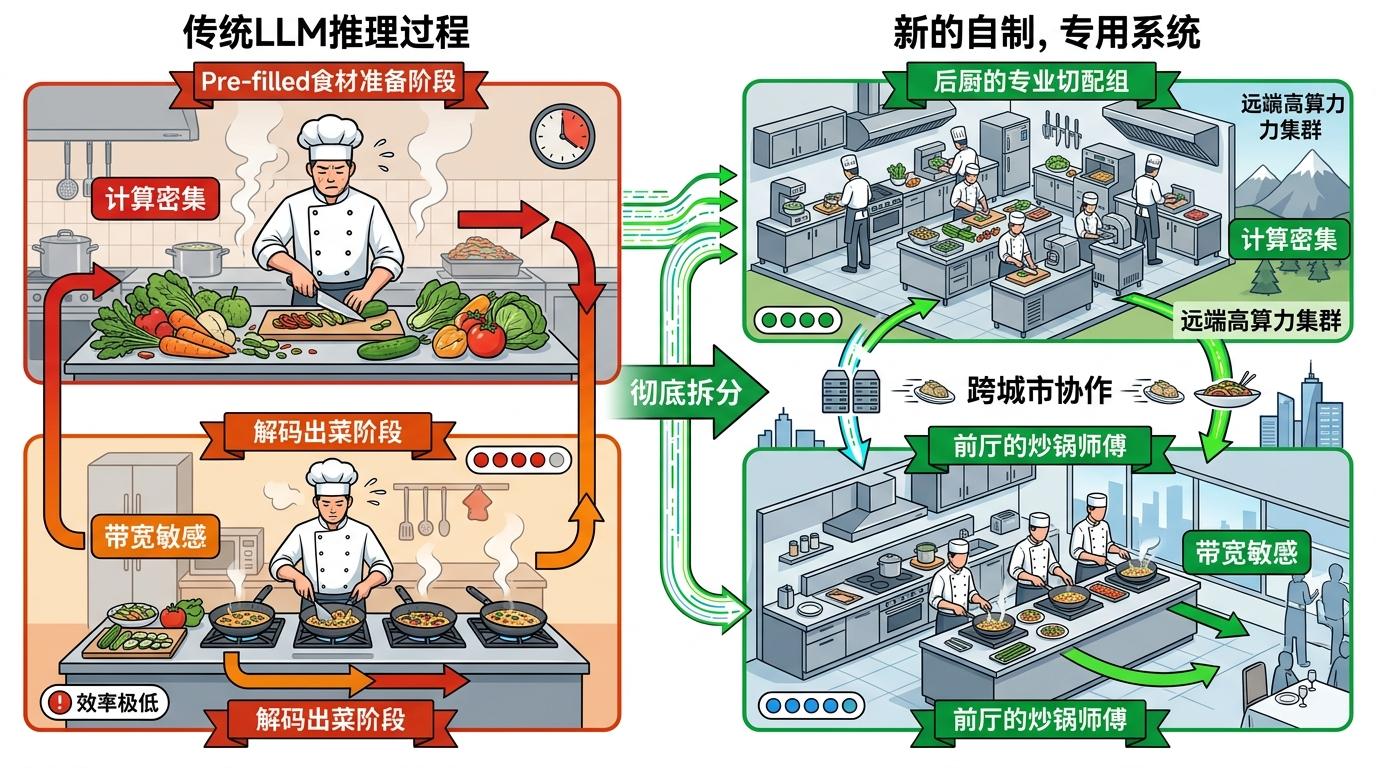
你可以把传统大模型推理想象成一个厨师:既要先把所有食材切好备齐(预填充Prefill阶段,计算密集),又要下锅翻炒慢慢出菜(解码Decode阶段,带宽敏感),全程守在灶台前,忙得脚不沾地却效率极低。现在,中国团队把这个流程彻底拆了——备菜交给后厨的专业切配组(远端高算力集群),炒菜交给前厅的炒锅师傅(近端高带宽硬件),两者不用挤在同一个厨房,甚至可以跨城市协作。
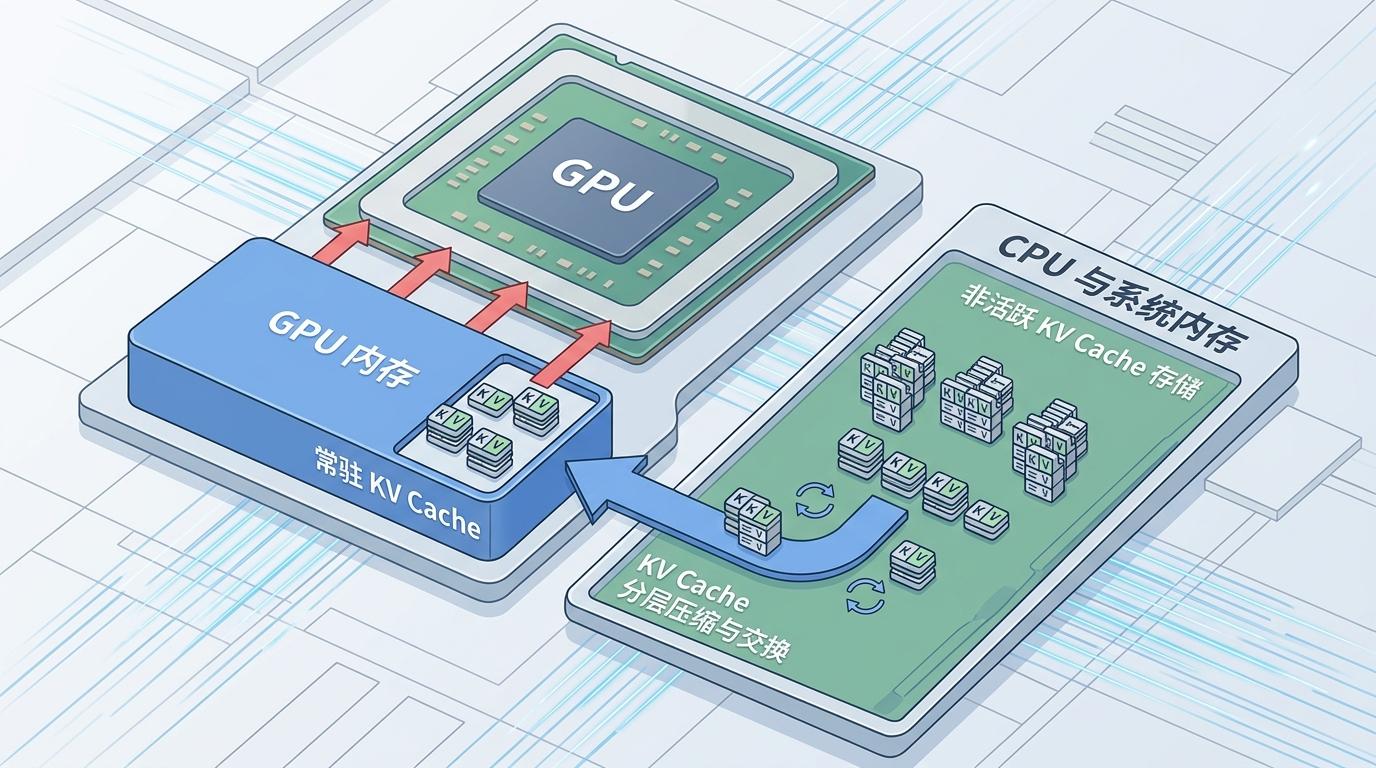
关键的突破,在于KV Cache的压缩技术。这个缓存就像厨师记在脑子里的菜谱,传统做法是把整本菜谱都塞在GPU里,占内存还拖速度。现在团队用分层压缩,只把最常用的几页留在GPU,剩下的存在CPU里,需要时再快速调取。就像厨师只把当天要用到的菜谱页贴在灶台边,整本菜谱收在柜子里,既省空间又不耽误事。
这套“预填充-解码”分离的架构,直接打破了大模型必须绑定高端GPU的铁律。高算力芯片负责集中“备菜”,国产的高带宽芯片就能接手“炒菜”环节——不是作为替代品,而是成为系统里不可缺少的一环。
当模型不再被算力卡脖子,真正的质变发生了:它从“回答问题的聊天工具”,变成了“能连续上班12小时的生产系统”。
你可以把这个系统想象成一个小型创业公司:以前只有一个全能员工,什么活都自己干,干久了就累垮;现在有300个专业员工(子Agent),有人擅长写代码,有人擅长整理文档,有人擅长协调进度,系统会自动把复杂任务拆成小活,分给合适的人干,还能盯着大家按时交工。比如处理一份10万字的技术文档,它会先派3个员工分头读文档,再派2个员工整理核心观点,最后派1个员工输出总结报告,全程不用人插手。
但这种“团队协作”也带来了新问题:300个员工的沟通成本、出错风险,比一个人干活高多了。比如某个员工写错了数据,其他人可能跟着出错;或者两个员工抢同一个任务,导致重复劳动。为了应对这些问题,团队给系统加了“三层验证”:每一步工作要自己检查,跨员工的交接要互相核对,最终输出要经过“质检员工”的审核。
有意思的是,这种多Agent系统的失败率,居然有50%以上不是因为模型“不够聪明”,而是因为任务分工模糊、员工职责不清——就像现实中的创业公司一样。
这场变革的本质,是重构了大模型的“推理经济学”。以前大家比的是“谁的模型参数更多、更聪明”,现在比的是“谁能用一块钱的算力,干十块钱的活”。
举个直观的例子:国际顶级闭源模型推理100万个Token,可能要花10美元;而这款国产模型只需要1.7美元。为什么能差这么多?除了架构优化,还有一个关键——稀疏激活的MoE架构。就像一个有1000个座位的电影院,以前每场都要坐满人才开场,现在只需要坐32个人就能开演,成本直接砍到原来的1/30,但电影的精彩程度丝毫不减。
但便宜不等于牺牲性能。在代码生成测试中,它的通过率比GPT-4.1还高9个百分点;在长文本处理上,它能一口气读25.6万个Token,相当于把一整本《红楼梦》喂进去,还能准确回答细节问题。这种“性价比碾压”,让全球开发者疯抢能本地部署它的硬件——毕竟,谁不想花最少的钱,把一个超级智能搬回自己的办公桌?
当然,它也不是完美的。比如处理复杂任务时,它的Token消耗量是普通模型的2倍以上,虽然单Token成本低,但总开销不一定更少;而且多Agent协作时,偶尔会出现“员工摸鱼”“沟通不畅”的问题,需要不断优化系统设计。
当我们还在纠结“中国AI能不能追上国际水平”时,中国团队已经用行动给出了答案:与其在别人制定的规则里比拼算力堆料,不如自己重新制定游戏规则。
算力封锁不是绝境,反而成了倒逼创新的催化剂。从拆分推理流程到多Agent协作,从压缩缓存到异构硬件协同,每一步都是在“有限资源”里挖“无限潜力”。这不仅是技术的胜利,更是一种思路的转变——AI的未来,从来不是“谁的算力更多”,而是“谁能把算力用得更聪明”。
当开发者们抱着断货的Mac Mini,在自己的办公桌上跑通超级智能时,我们看到的不是某款模型的成功,而是一个自主可控AI生态的雏形。算力卡不住创新,就像潮水挡不住礁石——只要找对了方向,缝隙里也能长出大树。