对抗知识焦虑,从看懂这条开始
App 下载
AI视频以假乱真后,终于要学“懂物理”了
Veo|Sora|机器人操作|物理世界模型|AI视频生成|多模态视觉|人工智能
对抗知识焦虑,从看懂这条开始
App 下载Veo|Sora|机器人操作|物理世界模型|AI视频生成|多模态视觉|人工智能
当你刷到AI生成的机器人叠杯子视频,流畅的动作、逼真的光影足以以假乱真——直到你看见夹爪穿过杯壁,空无一物的桌面突然冒出杯子。过去两年,Sora、Veo们把“视觉逼真”卷到了极致,但在机器人操作这类需要真刀真枪干活的场景里,物理违规的bug像幽灵一样挥之不去。
这不是简单的视觉瑕疵,而是AI世界模型的核心困境:它能“看见”世界,却根本“不懂”世界的运行规则。现在,一场针对这个困境的全球竞赛已经打响,它要把AI从“画饼选手”逼成“实干家”。
过去评判AI视频生成模型,就像选美——看谁的画面更清晰、光影更细腻,最多再挑挑帧与帧之间有没有卡顿。但在机器人操作、自动驾驶这些场景里,“好看”毫无意义:夹爪穿模意味着抓不住东西,物体凭空消失意味着任务彻底失败,时序错乱意味着机器人会做出致命的错误动作。
CVPR 2026的WorldArena挑战赛,第一次把“物理合规性”拉到了评测的C位。它的评测体系拆成了16项核心指标,从视觉质量、动作流畅度,到物体会不会穿模、轨迹符不符合力学规律,甚至连3D空间的透视准不准都要算分。最终所有指标会拧成一个EWMScore——不是比谁的视频最漂亮,而是比谁的视频最“讲理”。
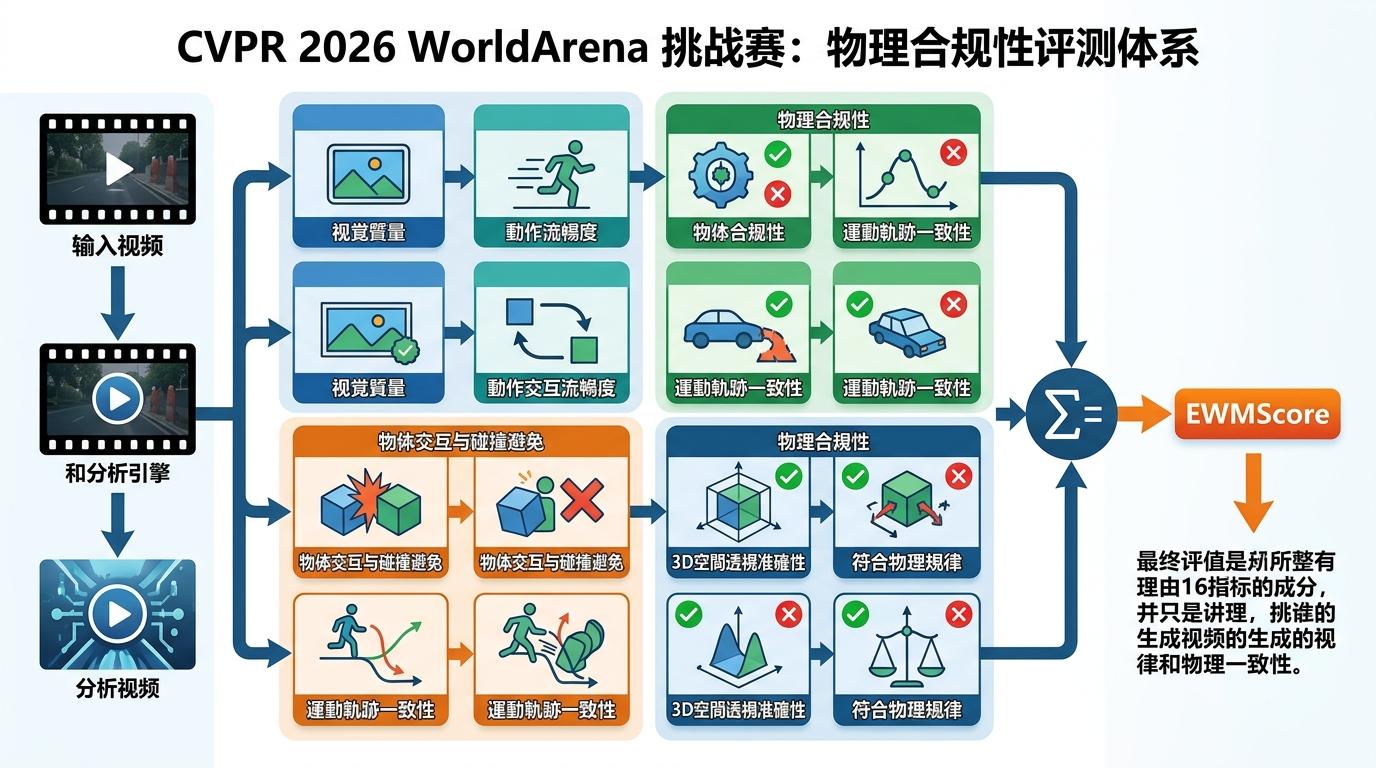
更狠的是第二赛道:直接把AI模型扔去干真活。测试它能不能生成靠谱的训练数据喂给机器人策略模型,能不能代替物理仿真器判断动作对不对,甚至能不能直接规划出机器人能执行的动作序列。这相当于让AI从“拍科幻片”直接转行“当工程师”。
要让AI生成符合物理规律的内容,核心不是优化渲染算法,而是给它植入“物理常识”。高德团队开源的ABot-PhysWorld模型,走通了一条可行的路径——它没有在“视觉逼真”上死磕,而是把训练重点放在了“物理真实性”上。
你可以把这个过程想象成教小孩玩积木:首先得给他看足够多正确的玩法——团队从300万条原始数据里淘出30万条符合物理规则的机器人操作视频,覆盖不同机器人、不同任务、不同场景,确保AI不会偏科。然后要告诉他什么是错的——用视觉语言模型当“裁判”,造出1万组“物理正确vs物理错误”的视频对,再用DPO偏好对齐技术训练AI:让它在“夹爪抓住杯子”和“夹爪穿过杯子”之间,坚定地选前者。
这套方法的效果是实打实的:在PAI-Bench基准测试里,它的物理合规性得分拿到了0.9306,把Sora 2、Veo 3.1这些视觉高手甩在了后面。更关键的是,它第一次打破了“视觉好看”和“物理合理”的跷跷板——在物理得分领先的同时,视觉质量依然能打。
但这套方案远不是终点。目前最棘手的问题,依然是“模拟世界”和“真实世界”的差距——AI在仿真数据集里学的物理规则,放到真实场景里可能会失灵。比如机器人抓杯子,仿真里的杯子重量、摩擦力都是精确设定的,但真实世界里的杯子可能沾了水,或者桌面有细沙,这些变量AI没见过,就容易出错。
另一个隐忧是“因果推理”的缺失。现在的AI能记住“夹爪向下会碰到杯子”,但它不一定理解“因为夹爪有力量,所以能抓住杯子”。这种“知其然不知其所以然”的认知,会让它在面对新场景时手足无措:比如从来没见过的异形杯子,它可能就不知道该怎么发力。
更值得警惕的是,目前的物理合规性评测还主要集中在刚体操作上,像布料折叠、液体倾倒这类涉及柔性物体、流体力学的场景,AI的表现依然一塌糊涂——这些场景里的物理规则复杂多变,连人类都很难用公式完全定义,更别说教给AI了。

从“看见世界”到“理解世界”,AI世界模型终于踩中了从“炫技”到“实用”的转折点。这场全球竞赛的意义,从来不是选出一个得分最高的模型,而是给整个行业立下了新的标尺:AI不能再只当“虚拟画家”,它要成为能改造真实世界的“工程师”。
看见是基础,理解才是门槛。 当AI终于开始学物理,我们离真正能干活的机器人、能放心上路的自动驾驶,才又近了一步。而这背后,是人类对“智能”的重新定义:真正的智能,从来不是模仿表象,而是掌握规律。