对抗知识焦虑,从看懂这条开始
App 下载
AI视觉修复大变天:CVPR挑战赛揭示从像素级P图到意图对齐的范式革命
恶劣天气感知|意图对齐|自动驾驶场景|视觉修复技术|CVPR挑战赛|多模态视觉|人工智能
对抗知识焦虑,从看懂这条开始
App 下载恶劣天气感知|意图对齐|自动驾驶场景|视觉修复技术|CVPR挑战赛|多模态视觉|人工智能
想象一辆自动驾驶汽车在高速公路上飞驰,一场突如其来的暴雨倾盆而下。雨水在摄像头镜头上划出无数道扭曲的水痕,雾气模糊了远方的路牌。对于这辆车的AI系统而言,这不仅是恶劣天气,更是攸关生死的“视觉灾难”。如果它的“眼睛”只能看到一堆模糊、抖动的像素,它如何能做出万无一失的判断?
过去,我们让AI修复这类画面的方式,就像一个耐心的修复师,一帧一帧地擦除雨滴、填补像素。这种方法虽然精细,却往往忽略了一个核心问题:视频是流动的,是一个连贯的“故事”。逐帧修复很容易产生闪烁、抖动等“穿帮镜头”,更无法恢复被雨雾完全遮挡的场景细节。我们需要的,不是一个像素级的“清洁工”,而是一个能理解整个场景、懂得物理规律、甚至能领会人类意图的“导演”。一场深刻的范式革命,正在AI底层视觉领域悄然上演。
这场革命的集结号,在世界顶级计算机视觉会议CVPR 2026上吹响。一个名为“LoViF”(生成式AI、偏好优化与智能体系统驱动的低层视觉前沿)的研讨会,发起了一项极具针对性的挑战赛——“真实世界视频天气去除挑战”。
这并非一次寻常的技术竞赛。它的目标明确且激进:推动底层视觉从“逐帧修复”向“视频级感知恢复”的范式演进。 比赛不再仅仅考核传统的PSNR(峰值信噪比)等像素级精度指标,而是将重点放在了更接近人类主观感受的三个维度:
LoViF研讨会的组织者明确指出,底层视觉正经历一场由生成式AI和智能体系统驱动的深刻变革。评价标准正在从冰冷的像素误差,转向与人类感知和意图的对齐。这不仅关乎技术,更关乎AI如何以更“人性化”的方式理解和重构我们眼中的世界。
长期以来,AI视觉修复领域被PSNR、SSIM等客观指标所“统治”。这些指标通过计算修复后图像与原始无损图像之间的像素差异来打分。分数越高,意味着像素层面的失真越小。
然而,这种“像素暴政”存在巨大缺陷。一个PSNR高分的修复结果,在人眼看来可能模糊不清、缺乏细节,因为它倾向于产生“安全”的平均化结果,抹掉了锐利的边缘和真实的纹理。这就像一篇逐字翻译精准但毫无文采的译文,虽然没有语法错误,却丢失了原作的灵魂。更有甚者,研究人员发现,一些算法可以通过特定手段“欺骗”评价指标(即“VMAF Hacking”),在分数上表现优异,但视觉质量却很差。
真正的视觉质量,关乎感知和理解。我们评价一幅画面,不仅仅是看像素值,更是看其中的结构、光影、纹理以及它们所构成的整体意义。这正是新范式的核心:让AI从“计算像素”转向“理解内容”。 这需要AI具备“想象力”,能够根据上下文合理推断出被遮挡部分应有的样貌,而这正是生成式AI的拿手好戏。
推动这场视觉革命的,是两大强大的技术引擎:生成式AI和智能体系统。
1. 生成式AI:从“擦除”到“创生”
以扩散模型(Diffusion Model)为代表的生成式AI,彻底改变了图像修复的逻辑。它不像传统方法那样试图“擦掉”雨滴,而是学习了海量真实世界图像的规律后,能够“想象”并“重新生成”一个没有雨的、符合物理和场景逻辑的全新画面。
字节跳动等团队推出的SeedVR-7B等模型,已经展示了这种“创生式”修复的惊人能力,它们能够处理全分辨率视频,生成以往技术难以企及的真实细节。
2. 智能体系统:从“工具”到“自主决策者”
如果说生成式AI是强大的画笔,那么智能体(Agent)就是手握画笔、拥有自主思想的艺术家。智能体系统将大型语言模型(LLM)的推理规划能力与视觉工具相结合,能够自主处理复杂的修复任务。
这种“感知-思考-行动”的闭环,让AI视觉修复不再是一个被动的、机械化的过程,而是一个主动的、智能化的决策过程,真正实现了与人类意图的对齐。
从图像修复迈向视频修复,最大的挑战在于“时间”。视频的每一帧都不是孤立的,它们之间存在着紧密的时序关联。逐帧处理的“割裂感”是旧范式难以逾越的鸿沟。
新一代的视频恢复技术,正全力攻克时序一致性难题:
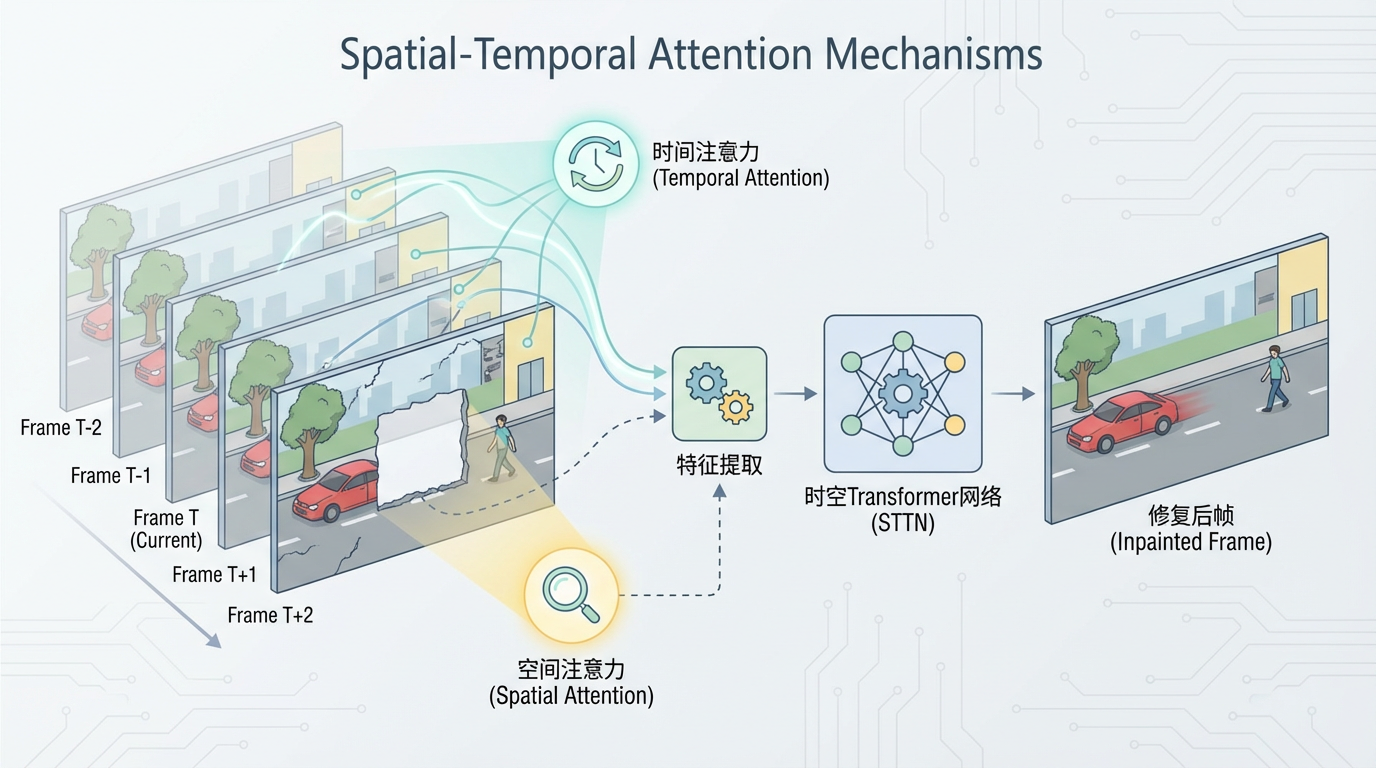
这些技术的突破,使得“视频级感知恢复”成为可能。AI不再是处理24张/秒的静态图片,而是在处理一个连续、动态的四维时空事件,确保修复后的世界流畅、真实、可信。
这场视觉范式的革命远未结束,它的终极目标是让AI拥有一个“世界模型”(World Model)。这意味着AI不仅能修复画面,更能深刻理解画面背后的物理规律和因果关系。
一个拥有世界模型的AI在处理雨天视频时,它知道雨水会顺着物体重力方向下落,知道积水会反射环境,知道雨滴打在不同物体表面会产生不同的效果。基于这种深层理解,它的修复将达到前所未有的逼真程度。
英伟达的DreamZero等前沿研究,已经展示了构建这种世界模型的可能性。它们通过联合预测视频和动作,让AI学习物理世界的动态规律。当这种能力应用于底层视觉时,AI将不再仅仅是模仿现实,而是在某种意义上“理解”现实。
从像素精度到感知对齐,从被动修复到主动创造,从处理图像到理解世界。LoViF挑战赛所揭示的,不仅仅是一场技术的迭代,更是一次AI认知能力的跃迁。未来,无论是穿行于风雨中的自动驾驶汽车,还是在博物馆里被精心修复的百年影像,亦或是家庭服务机器人眼中的清晰世界,都将受益于这场深刻的视觉革命。AI正在被授予一双更敏锐、更智能的“眼睛”,去观察、理解并重塑我们的世界。