对抗知识焦虑,从看懂这条开始
App 下载
3B开源模型碾压GPT-5.4,靠的是这件事
推理准确率|token预算|长度控制技术|GPT-5.4|3B参数开源模型|大语言模型|人工智能
对抗知识焦虑,从看懂这条开始
App 下载推理准确率|token预算|长度控制技术|GPT-5.4|3B参数开源模型|大语言模型|人工智能
当你让AI写一段200字的摘要,它要么写了120字就草草收尾,要么絮絮叨叨扯到300字开外——这几乎是每个用过大语言模型的人都遇到过的尴尬。更头疼的是,为了凑够思考空间给的长token预算,往往一半都是没用的废话,算力和时间像泼出去的水。
但现在有个3B参数的开源模型,在精确长度控制上直接干翻了GPT-5.4、Claude这些顶级闭源模型。它能把长度偏差从135%压到56%,在固定token预算下,推理准确率更是从6%飙升到63%——整整10倍。这不是靠堆参数,而是靠把AI的生成长度,拆成了每一个字的精细算计。
之前的长度控制,说穿了都是「祈求」:要么在prompt里写「请控制在200字」,把希望寄托在AI的「听话程度」上;要么训练时加个序列级惩罚,模型生成到一半早就忘了自己该写多长。这些方法全是在「序列层面」操作,可AI生成是一个字一个字蹦出来的——就像你给司机说「开20公里」,却不告诉他现在离终点还有多远。
来自UC Santa Barbara和Apple的团队,把这个问题给倒过来了:他们给每个生成的token都标上「成本」——每写一个字,就扣掉固定的「负奖励」。通过强化学习里的价值函数,AI能在每一步都算出「还剩多少字要写」,这个值被牢牢锁在(-1,0)的区间里,写得越接近目标,数值就越靠近0。
这相当于给AI装了个实时更新的进度条,不是写完才看有没有超标,而是每写一个字都在调整方向。
更狠的是这个叫LenVM的模型,连训练数据都不用额外标注。传统的长度控制模型,得人工给成千上万的文本标上「符合长度要求」「不符合」,成本高得离谱。但LenVM的训练信号是自动生成的:它让AI自己生成文本,然后根据实际长度反推每一步的「剩余长度价值」,整个过程完全自监督。
而且它的能力会跟着算力和数据同步涨——模型参数从0.5B加到32B,训练数据从10k涨到100k,甚至每个prompt多采样几次,它的长度控制精度都会稳步提升,完全看不到饱和的迹象。这就像你给一个会自己刷题的学生,只要给他更多练习题,他就能一直进步,不用老师额外改作业。
在LIFEBench基准测试里,3B的开源模型加了LenVM之后,长度得分从25.6跳到62.6,直接把GPT-5.4的37.4甩在身后。不是闭源模型不够强,而是它们从根上就没在每个token的粒度上做长度控制。
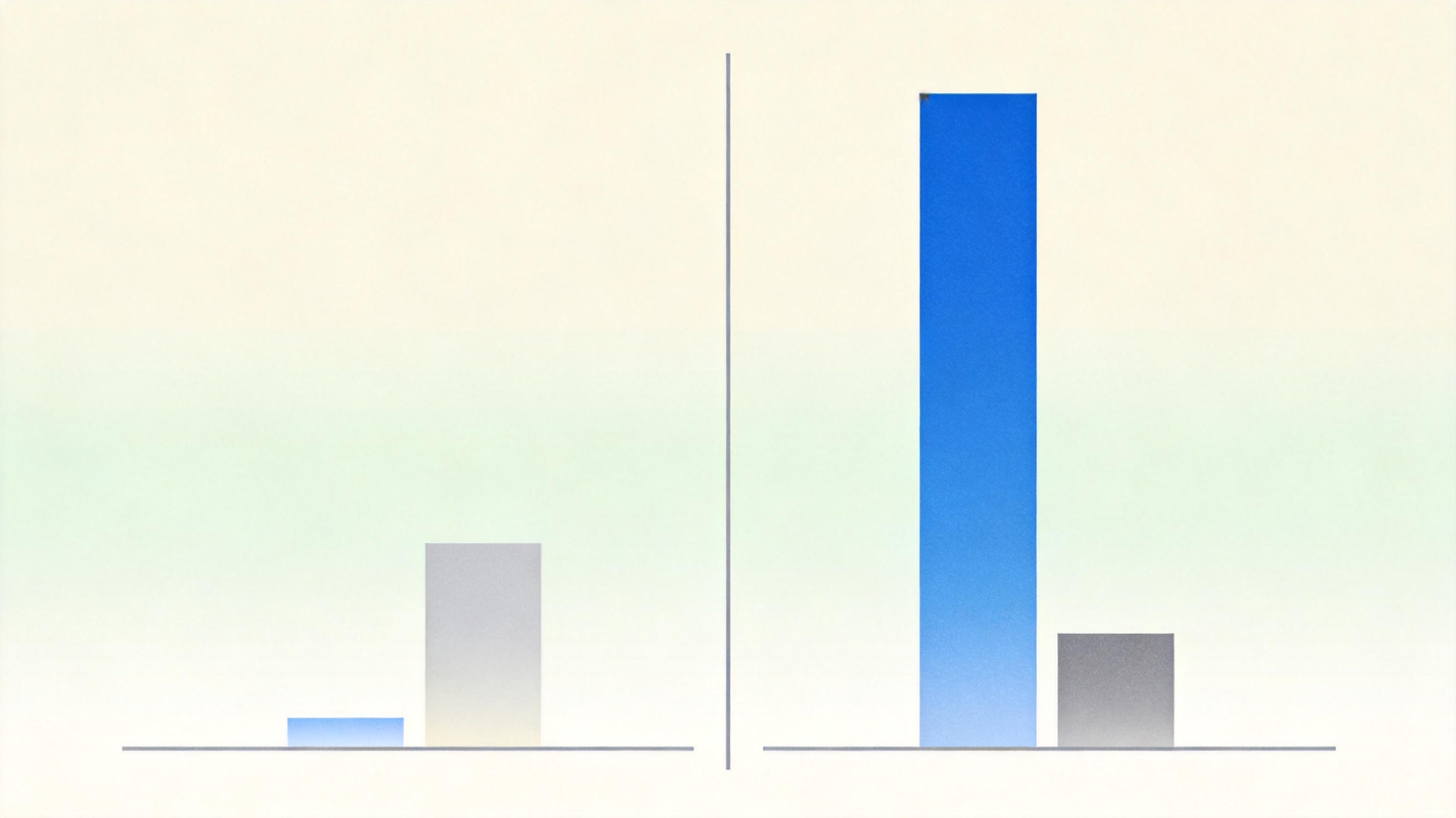
LenVM最让人意外的地方,是它不止能控制长度,还能把AI本来就有的能力给「挖」出来。在GSM8K数学推理任务里,硬截断到200token的话,AI的准确率只有6%——就像让你用10个字解一道几何题,根本施展不开。但用LenVM引导生成,同样是200token,准确率直接冲到63%。
这说明AI本身就有能力用更短的路径解题,只是平时会随机选到那些绕远路的思路。LenVM通过给「短路径」的token加权,把这些高效的解题思路给捞了上来。它甚至能告诉你哪些字是在「拖时间」——比如「think」「but」这些词一出现,AI大概率要展开新的思考;而「therefore」「✅」一出来,就是要收尾了。
当然它也不是万能的:目前只在文本生成上验证了效果,多模态场景还没经过测试;而且模型越小,长度预测的误差还是会比大模型高一些。但它至少给了我们一个新方向:AI的可控性,从来都不是靠「命令」,而是靠「理解每一步的代价」。
我们总在说AI要更「智能」,但很多时候,智能的第一步是「可控」——是让AI写200字就绝不写201字,是让它在有限的资源里把该做的事做好。LenVM没有发明新的模型架构,也没有堆更多的参数,它只是把「长度」这件事,从一个模糊的要求,变成了AI每一步都能感知的价值。
好的AI,懂得在该停的时候停。
未来的生成式AI,或许不会再是那个只会滔滔不绝的话痨,而是能精准拿捏分寸的合作者——知道什么时候该展开思考,什么时候该给出答案,就像一个靠谱的同事,永远能在deadline前交出刚好符合要求的工作。