对抗知识焦虑,从看懂这条开始
App 下载
Mamba-3让GPU不摸鱼,比Transformer快7倍
长文本处理|GPU推理效率|Transformer架构|Mamba-3|大语言模型|人工智能
当你用AI写一篇万字长文时,Transformer架构的模型正像个翻档案柜的老职员——每写一个字,都要把前面几万字的文档重新翻一遍,越往后越慢。而今天发布的Mamba-3,就像个随身带着智能笔记本的高效助理:它把所有历史信息压缩成一个固定大小的「快照」,每写一个字只需要更新快照,不用回头翻旧账。在16384个token的长任务里,它的推理延迟只有Transformer的七分之一,15亿参数模型的准确率还比Transformer高4%。这一切,都源于它对「GPU带薪休假」这个行业痛点的精准打击。
从「翻档案柜」到「随身笔记本」的革命
你可以把Transformer的自注意力机制想象成一个无限扩容的档案柜:每来一份新文件(新token),它都要和之前所有文件做一次关联比对,档案柜越大,找东西的时间就越长——这就是它计算复杂度随序列长度平方增长的根源。而Mamba-3基于的状态空间模型(SSM),是个大小固定的随身笔记本:它会把所有历史信息实时压缩成一个固定维度的「内部状态快照」,每新增一条信息,只需要更新快照内容,不用把整本笔记重新读一遍。
这个「快照」的大小是SSM的核心权衡点:快照越大,能装的信息越多,但推理时搬运数据的开销也越大。Mamba-3的第一个突破,就是用仅为Mamba-2一半的快照大小,实现了同等的语言建模性能——相当于把笔记本变薄了一半,却没漏掉任何关键信息。
三大杀招:让GPU从摸鱼到满负荷
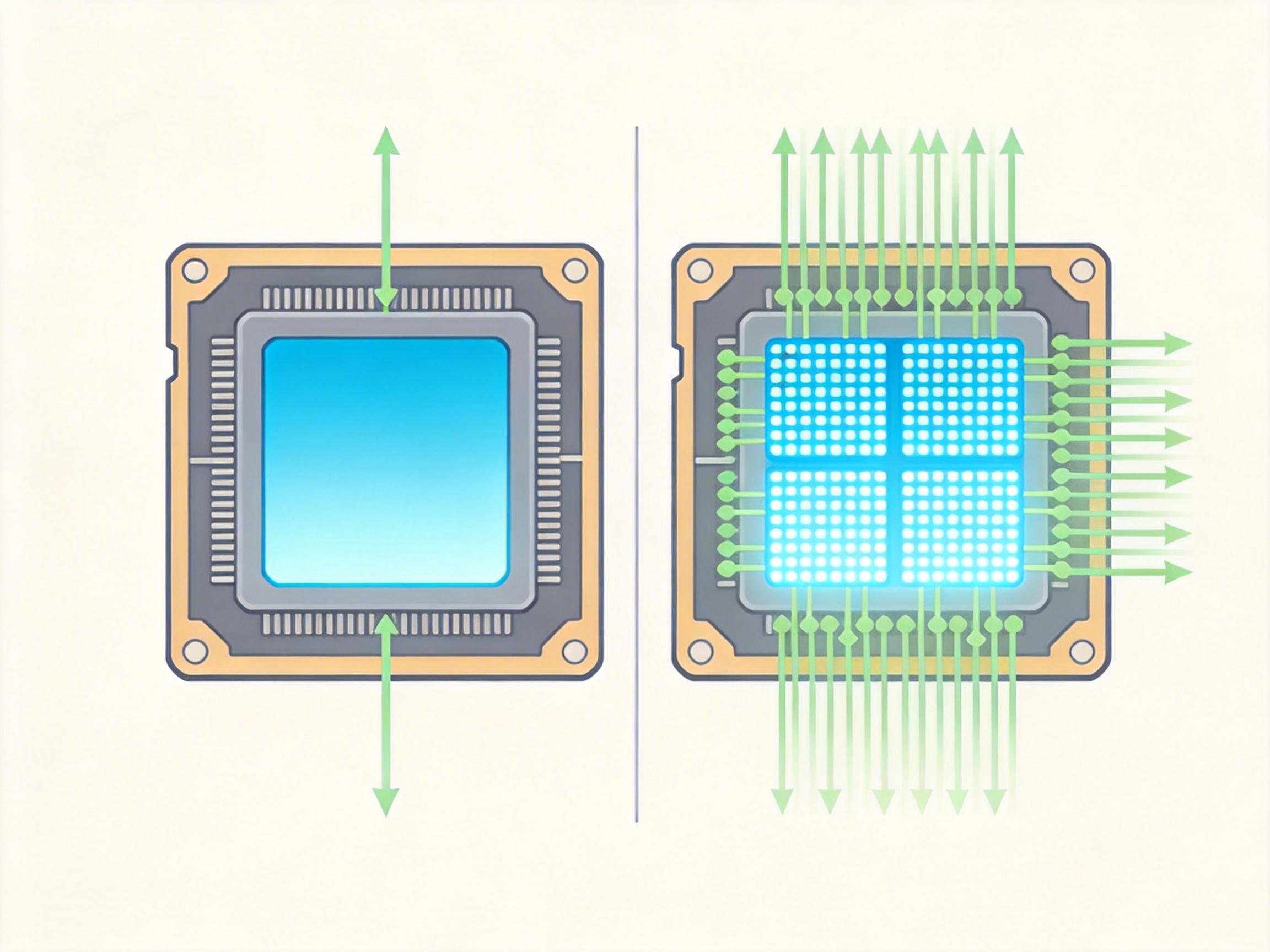
Mamba-3的核心目标,是把GPU里那些闲置的计算核心彻底激活。过去SSM模型的解码算术强度只有约2.5 ops/byte,而NVIDIA H100的张量核心能力是295 ops/byte——相当于GPU有99%的时间在干等数据。Mamba-3用三个技术创新解决了这个问题:
首先是**指数梯形离散化**:把之前的一阶近似升级为二阶精度,相当于估算曲线下的面积时,从只看左端点变成取左右端点的加权平均。这不仅提升了状态更新的精度,还在SSM里隐式实现了宽度为2的卷积,直接淘汰了之前必须单独加的短卷积模块。
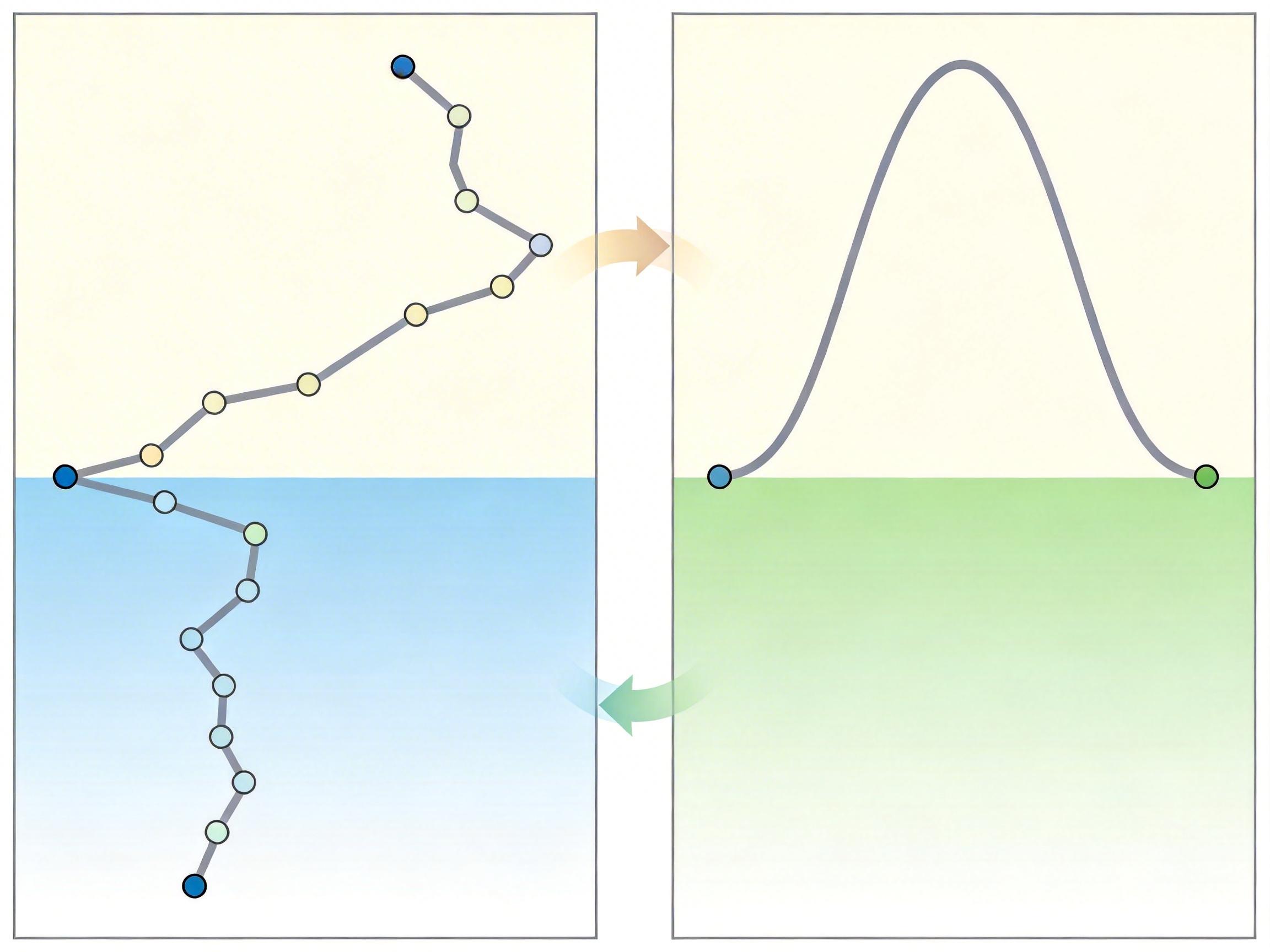
其次是复数值状态空间:传统SSM用实数状态转移矩阵,没法表达「旋转」这种动态,导致在奇偶校验这类需要状态翻转的任务上表现和随机猜测差不多。Mamba-3把状态转移搬到复数域,相当于给模型装了个「内部指南针」,能精准追踪状态变化——在奇偶校验任务上,准确率直接从0.9%跳到了100%。
最后是**MIMO多输入多输出架构**:把原来的单输入单输出状态更新改成矩阵乘法,让每一步的计算量直接翻4倍,刚好填满GPU闲置的张量核心。测试显示,MIMO版本的推理延迟几乎没增加,模型准确率却又上了一个台阶。
不是取代,而是混合:AI架构的终局
Mamba-3团队没有回避一个现实:纯SSM模型在精确检索任务上,还是不如Transformer。毕竟固定大小的笔记本,没法像无限扩容的档案柜那样,精准定位到「第三段第二句话」。他们给出的解法是混合架构:把Mamba-3层和无位置编码的自注意力层按5:1的比例交替堆叠。
实验显示,这种混合模型在检索任务上超过了纯Transformer,同时还保持了SSM的高效推理能力。这也符合当前行业的趋势——Nemotron-H、Kimi Linear、HunyuanTurboS都在走混合路线。未来的AI架构,不会是Transformer和SSM二选一,而是像瑞士军刀一样,把不同工具的优势组合起来:用SSM处理长序列的高效推理,用Transformer完成精准的信息检索。
从2017年Transformer横空出世,到今天Mamba-3把推理效率推上新高度,AI架构的进化一直围绕着一个核心:如何用更少的资源,做更多的事。Mamba-3的意义,不只是比Transformer快7倍、准4%,更在于它标志着AI行业的重心从「训练优先」转向了「推理优先」——毕竟,真正决定AI用户体验的,不是训练模型花了多少钱,而是用的时候快不快、顺不顺。
高效,才是AI落地的终极密码。 当更多模型开始把「不浪费每一分GPU算力」作为设计目标,我们离AI真正走进每一个日常场景,就又近了一步。