对抗知识焦虑,从看懂这条开始
App 下载
本地AI智能体落地,知识管理变主动伙伴
隐私保护|语义标签|知识管理系统|本地化部署|AI智能体|人工智能
对抗知识焦虑,从看懂这条开始
App 下载隐私保护|语义标签|知识管理系统|本地化部署|AI智能体|人工智能
当你打开电脑想写一篇行业稿,不用再从十几个文件夹里翻旧文、找风格参考——一个本地AI智能体已经把你过往的文章拆解成语义标签,能直接模仿你的文风生成初稿,还能自动关联最新的行业数据。这不是科幻场景,2026年的PC已经能实现这种本地化的智能知识管理。它不用上传你的私人文档到云端,断网时也能正常工作,甚至比云端AI更懂你的个人习惯。这种从被动存储到主动协作的转变,正在重新定义我们和知识的关系。
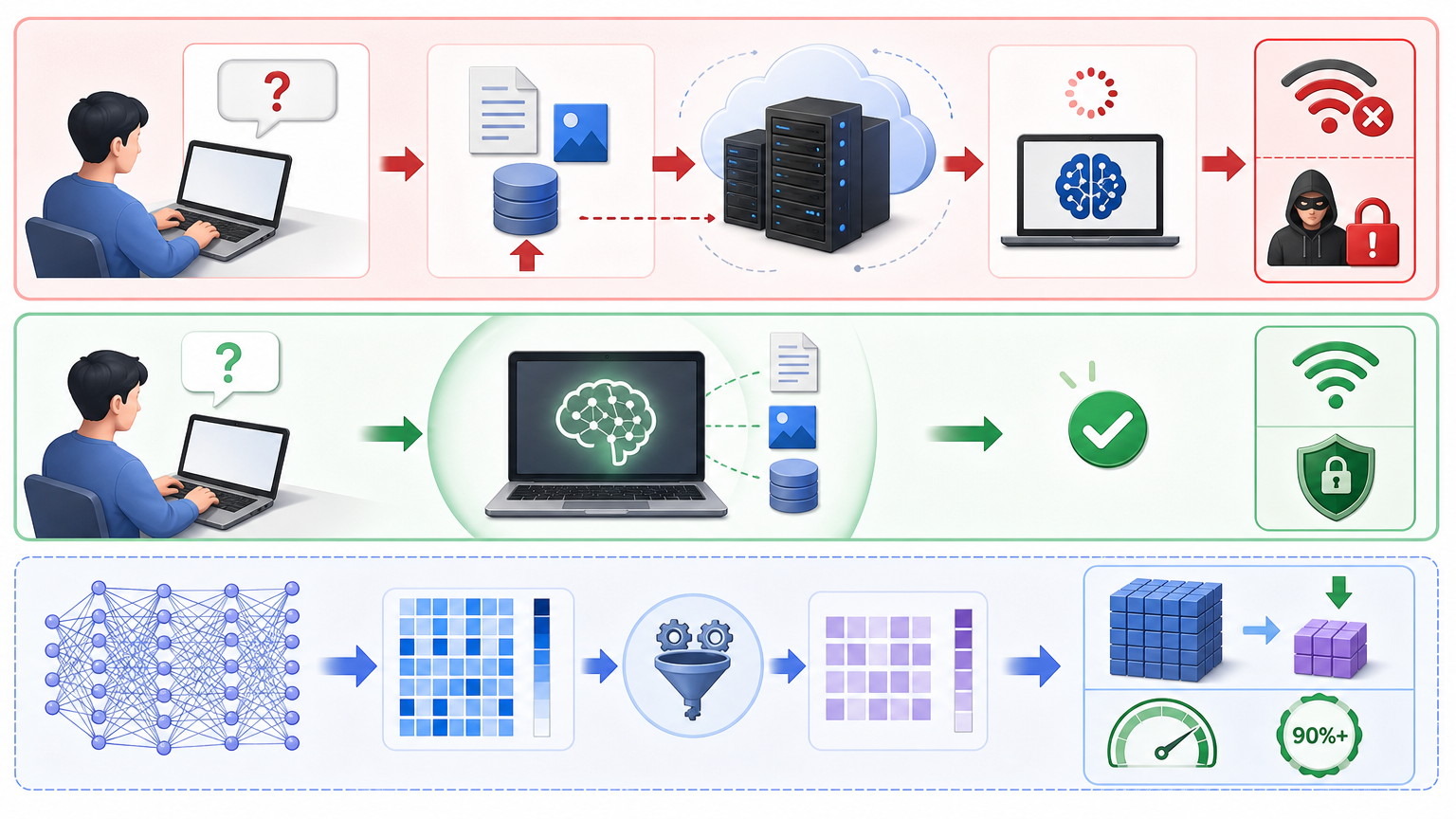
过去我们用AI处理知识,得依赖云端服务器:输入问题、上传数据、等待返回结果,不仅受网络限制,还得担心隐私泄露。而本地AI智能体的核心,是把大语言模型「搬」到你的电脑里——当然不是直接塞下几十GB的原始模型,而是通过量化、蒸馏等技术把模型「缩水」:比如把32位的参数压缩成4位,体积能缩小8倍,却能保留90%以上的推理能力。
这背后需要硬件的配合:现在的PC开始标配神经处理单元(NPU),这种专门为AI设计的芯片,能以很低的功耗完成模型推理,比用CPU跑快10倍以上。再搭配16GB以上的内存和高速NVMe硬盘,就能支撑起本地智能体的运行:它能读取你的本地文档、记住你的对话上下文,甚至能调用电脑里的工具自动完成任务,比如整理文件夹、生成数据报表。
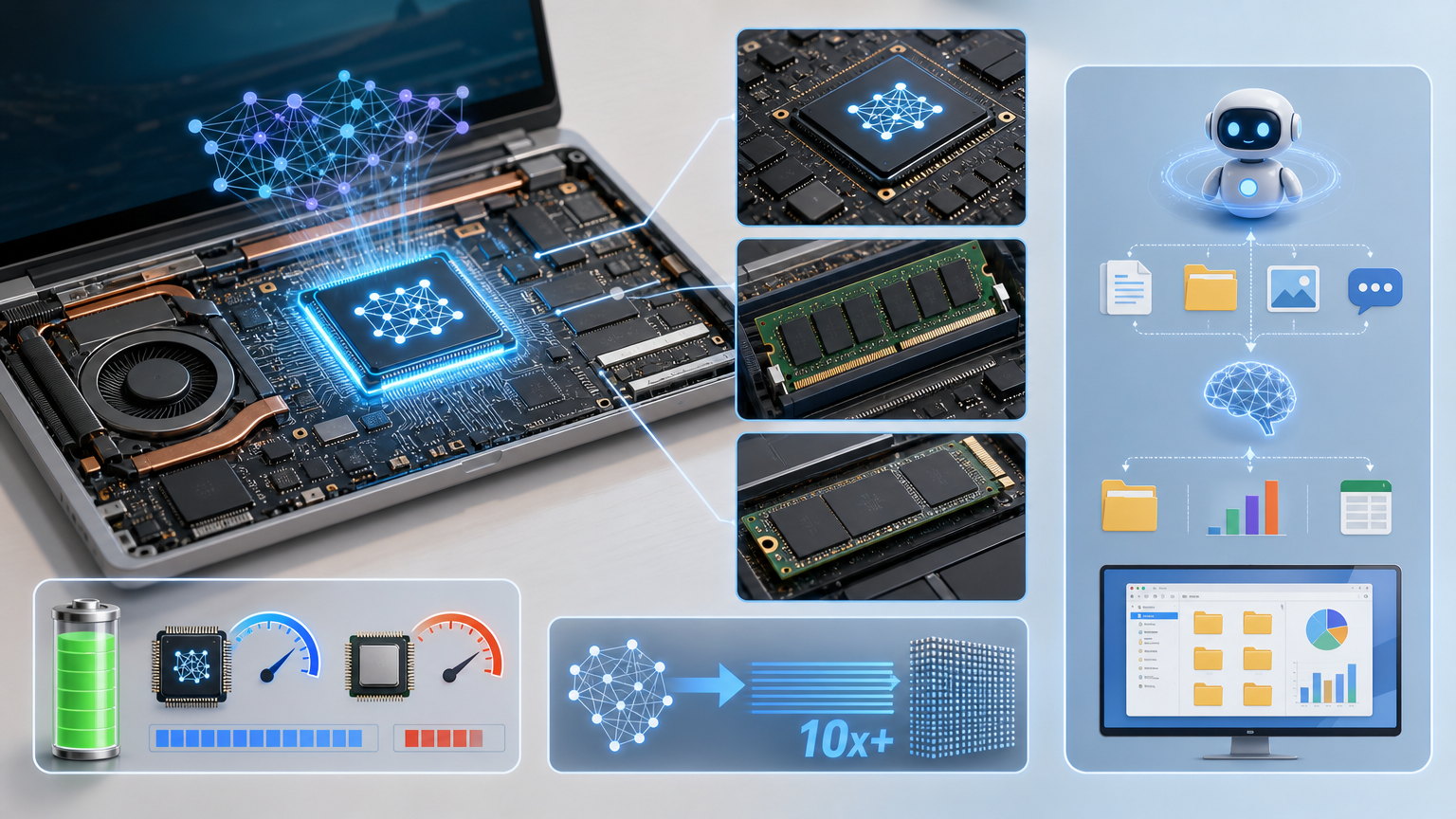
简单说,本地AI智能体就像你电脑里的「专属秘书」:它只服务你一个人,所有数据都存在你的设备里,响应速度比云端快几倍,还不用担心隐私问题。
传统的个人知识管理,本质是「信息堆积」:我们把文档、笔记、资料存在硬盘或云端,用关键词搜索找东西,效率低不说,还经常找不到真正需要的内容。而本地AI智能体带来的是「智能联想」——它能理解知识之间的语义关系,把零散的信息织成一张网。
比如你导入了100篇行业报告,它会自动提取每篇的核心观点,生成知识图谱,当你问「今年的行业趋势」时,它不仅能列出结论,还能关联3年前的相似趋势,甚至告诉你某篇报告里的数据存在矛盾。写文章时,它能根据你输入的标题,自动从你的知识库中调取相关案例和数据,还能模仿你的写作风格生成初稿。
这背后的关键技术是向量嵌入:它把每一段文字转换成一串能代表语义的数字,当你搜索时,不是找字面匹配的关键词,而是找语义相似的内容。比如你搜「用户增长」,它会把包含「拉新策略」「留存方法」「转化提升」的内容都找出来,准确率比传统搜索高得多。
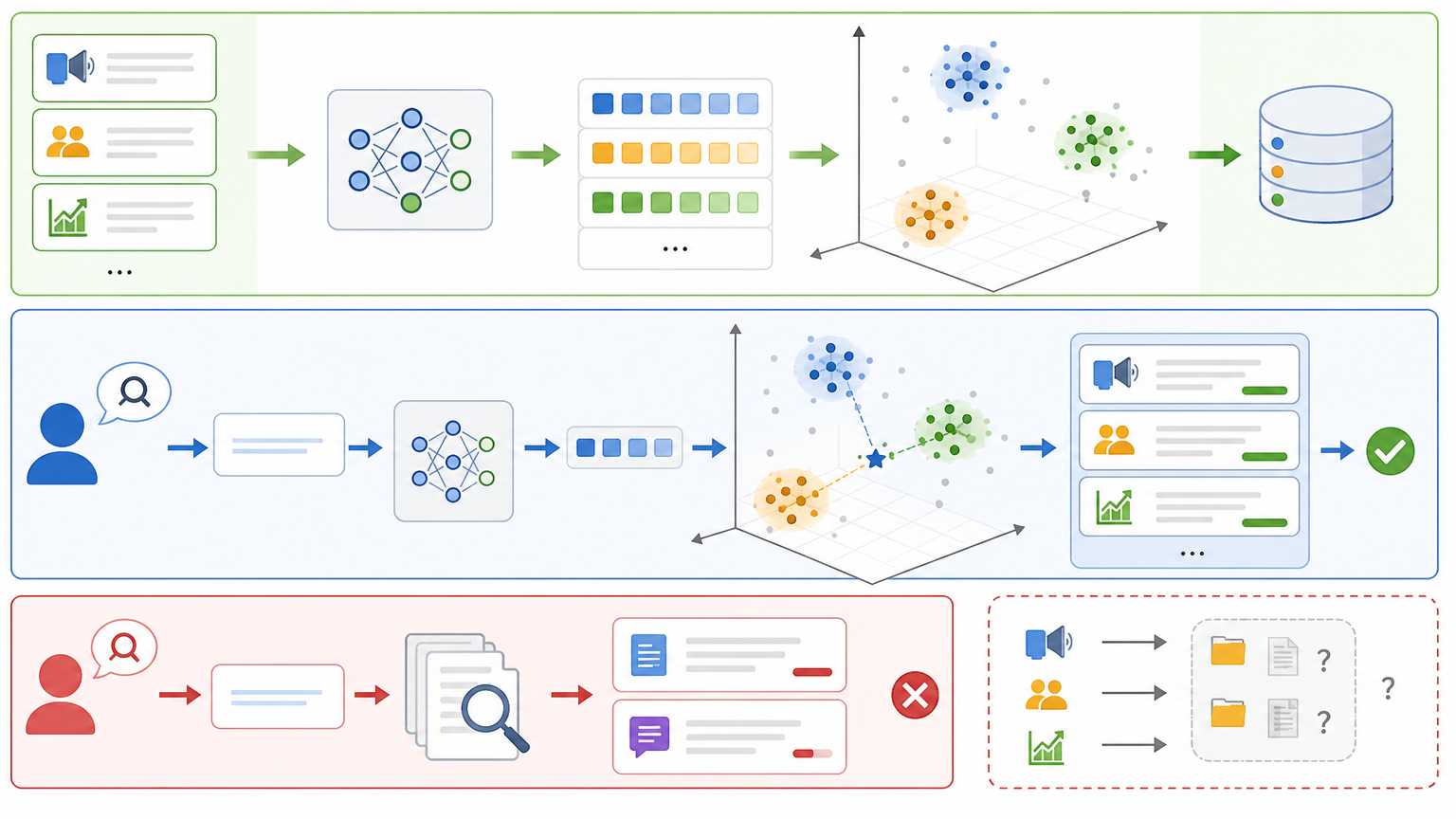
当然,这一切都还有待完善:比如智能体偶尔会生成错误的关联,或者处理大文件时速度变慢,知识库的更新也需要人工干预。但不可否认的是,它已经把知识管理从「找东西」变成了「用知识」。
本地AI智能体的普及,还面临着几道坎。首先是硬件门槛:虽然现在的PC大多能运行小型模型,但要流畅处理复杂任务,比如同时调用多个工具、处理多模态数据,还是需要高性能的GPU和大内存——这意味着你可能得花更多钱升级设备。
其次是安全问题:智能体需要读取你的本地文件、调用系统工具,一旦被黑客攻击,后果不堪设想。现在的解决方案是「最小权限原则」:只给智能体完成任务必需的权限,比如写文章时只让它访问文档文件夹,不让它修改系统设置。同时用沙箱技术把智能体隔离在独立环境里,就算它出了问题,也不会影响整个系统。
最后是用户体验:现在的智能体还不够「聪明」,经常会误解用户的指令,或者生成错误的结果。要解决这个问题,一方面需要优化模型,另一方面需要让用户更方便地训练智能体——比如通过标注错误结果、导入更多私人数据,让它更懂你的需求。
这些挑战不是不能解决,只是需要时间:硬件会越来越便宜,安全技术会越来越成熟,模型也会越来越智能。
当本地AI智能体成为PC的标配,我们的知识管理将进入一个全新的阶段:不再是我们追着信息跑,而是信息主动来找我们。它会记住我们的知识结构、工作习惯甚至思维方式,成为我们的「第二大脑」。
当然,这并不意味着我们可以放弃思考——智能体只是工具,真正的价值在于我们如何用它整合知识、激发创意。未来,人与知识的关系会变成协作:我们提供方向和判断,智能体负责处理琐碎的信息和重复的任务。
知识不再是静态的存储,而是动态的协作伙伴。