对抗知识焦虑,从看懂这条开始
App 下载
放弃完美序列,换来了每秒5万次的高效生成
零停机迁移|唯一ID生成|DynamoDB|双层缓存|序列生成|软件工程|前沿科技
对抗知识焦虑,从看懂这条开始
App 下载零停机迁移|唯一ID生成|DynamoDB|双层缓存|序列生成|软件工程|前沿科技
想象一下:当你运营着一个拥有上百个服务的平台,突然要把所有数据库从关系型换成NoSQL——这就像给高速行驶的飞机换引擎。而最棘手的不是数据迁移,而是那个平时没人在意的小功能:序列生成。它是数据库里的隐形计数器,每次插入数据时自动吐出唯一递增的数字,是无数服务的主键来源。但NoSQL偏偏不支持这个功能,UUID会打乱排序,雪花算法又太复杂。有人却用一个反直觉的办法解决了:主动放弃无间隙的完美序列,用双层缓存加DynamoDB,把数据库写入量降到了原来的千分之一,每秒能生成5万个唯一ID,还实现了零停机迁移。这到底是怎么做到的?
你可以把这个架构想象成一个三级供水系统:DynamoDB是城市水库,服务端缓存是小区蓄水池,客户端缓存就是你家的饮水机。平时你喝水直接接饮水机的水,根本不用跑水库——99%的请求都是这样,完全在应用进程内完成,延迟低到亚毫秒级。
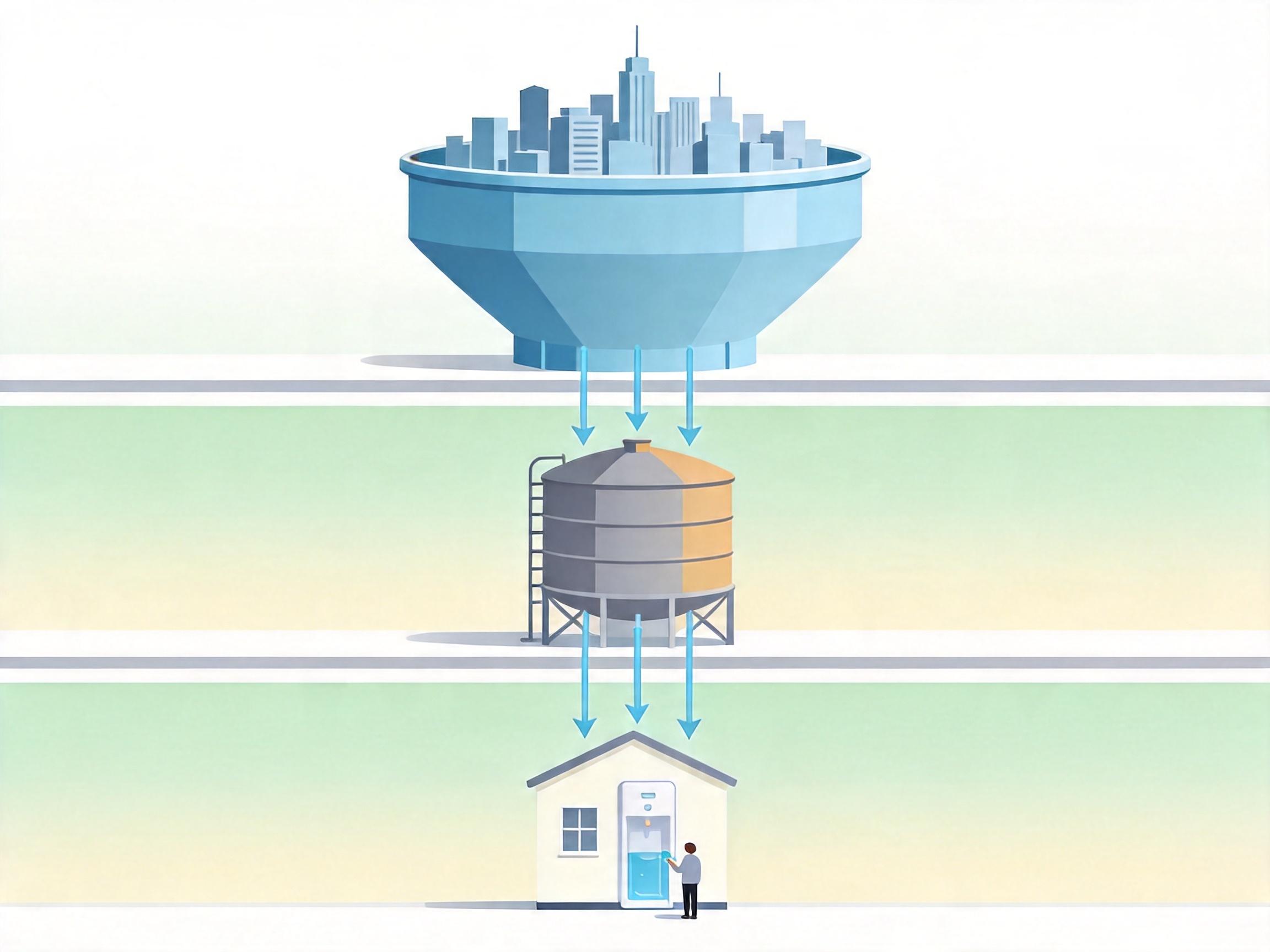
当你家饮水机快空了,会自动给小区蓄水池发信号补满;蓄水池快空了,才会从水库批量抽水。这里的关键是“批量”:服务端每次从DynamoDB取500到1000个序列号,客户端每次从服务端取50到500个。就像一次拉一卡车水,够喝好几个月,不用天天跑水库。
这种设计的代价是会产生“间隙”——如果服务器崩溃,缓存里没用到的序列号就浪费了。但对于绝大多数业务来说,订单号、用户ID有没有间隙根本不重要,唯一且单调递增才是核心需求。接受这一点,就绕开了分布式锁、共识协议这些复杂的坑。
光有缓存还不够,你得知道什么时候该补仓。这就用到了滑动窗口算法——它像一个智能管家,盯着你家的用水量,提前算好什么时候该叫水。
具体来说,系统会在60秒的滚动窗口里记录序列号的消耗速度,然后算出一个动态阈值:比如你每秒用10个ID,就提前存够500个(50秒的量)当缓存低于这个阈值,就自动在后台补仓。而且补仓是异步的,不会影响正在用的水——用户请求全程不会被阻塞。
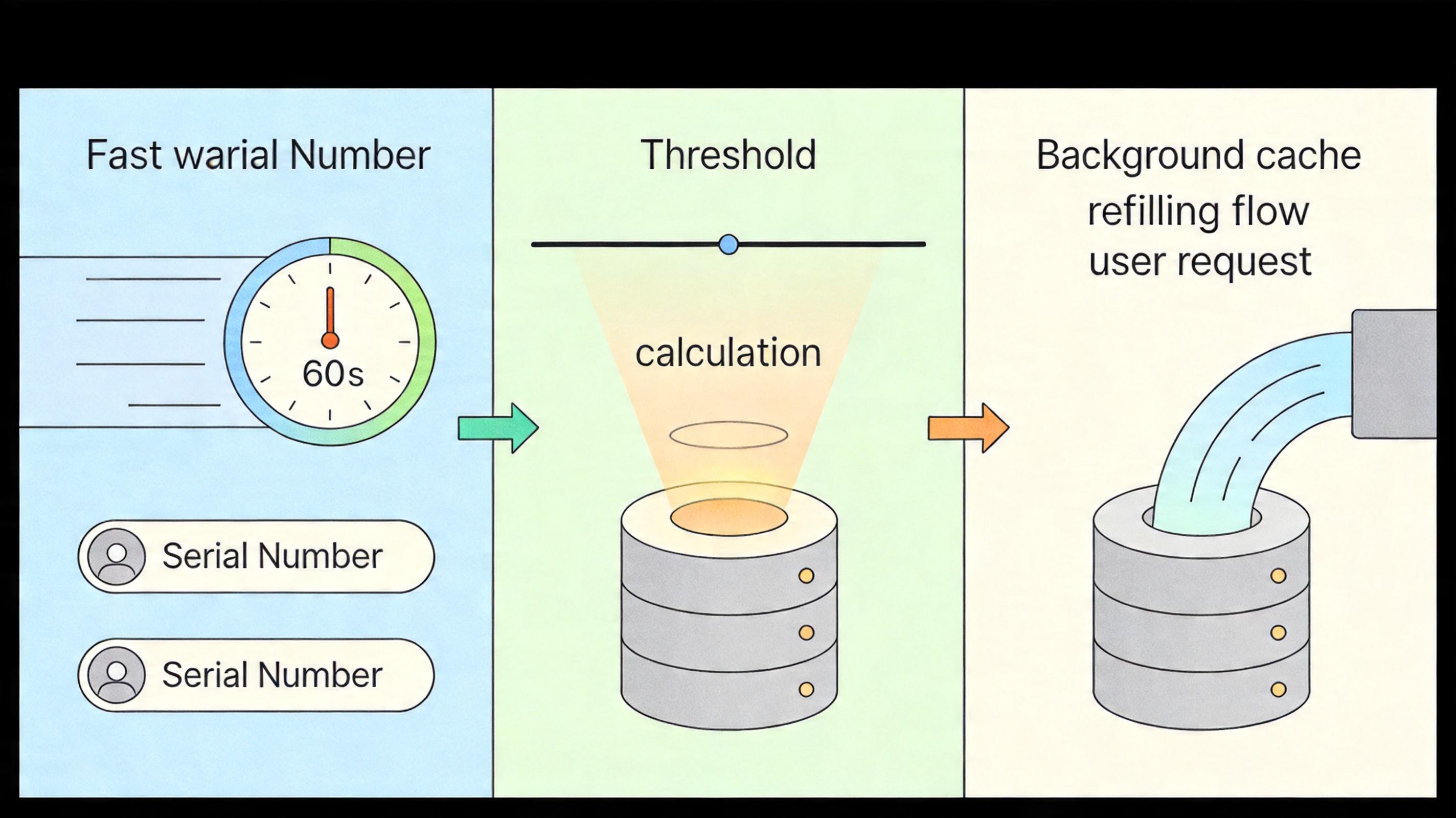
这个算法还能自适应流量变化:如果突然来了一波高峰,消耗速度飙升,阈值也会自动提高,提前多存点水;流量降下来,阈值也会跟着降,避免浪费。就连配置错了的客户端,也能在几分钟内自动调整到最优状态。
这个方案最厉害的地方不是技术有多复杂,而是它的易用性。客户端API极其简单,只需要传入序列名:sequenceClient.next("orders_seq"),和原来调用数据库序列的代码几乎一模一样。订单团队迁移12个服务,只改了不到50行代码,三周就完成了零停机迁移,峰值每秒生成8000个ID。
所有复杂的配置都在服务端:起始值、步长、升降序,甚至缓存大小、批量数量,都可以动态调整,不用重启服务。比如某个序列突然流量暴增,运维人员在后台把批量大小从500改成1000,几秒钟就生效,客户端完全没感觉。
当然,这个方案也有局限性:跨客户端的ID不是严格全局递增的,只能保证单个客户端内的单调递增。但经过沟通,绝大多数团队发现他们根本不需要全局严格有序——原来大家都被“完美序列”的执念绑住了。
这个故事最有意思的地方,不是技术本身,而是背后的思维转变:在分布式系统里,有时候放弃一些看似必要的“完美”,反而能得到更简单、更可靠的解决方案。
缓存从来都不是什么新鲜技术,但这里它不只是性能优化的工具,而是整个架构的基础——用分层缓存实现了高弹性,用接受间隙换来了低复杂度,用异步预填保证了低延迟。这恰恰是分布式系统的核心智慧:在一致性、可用性和性能之间找到最适合业务的平衡点。
接受不完美,才是完美的开始。 当我们放下对“无间隙序列”的执念,突然发现原来复杂的问题,可以用如此简洁的方式解决。这或许比任何技术细节都更值得我们记住。