对抗知识焦虑,从看懂这条开始
App 下载
何恺明改了扩散模型:不猜噪声直接画图
流形假设|去噪方法|CVPR 2026|扩散模型|何恺明团队|大语言模型|人工智能
对抗知识焦虑,从看懂这条开始
App 下载流形假设|去噪方法|CVPR 2026|扩散模型|何恺明团队|大语言模型|人工智能
当所有人都在给扩散模型叠buff——加VAE、堆tokenizer、对齐预训练特征时,何恺明团队把这些全拆了。他们最新的CVPR 2026论文,直接推翻了扩散模型火了五年的主流玩法:不让模型猜噪声,而是让它直接画干净的图。
这不是何恺明第一次“返璞归真”。从ResNet解决深层网络退化,到MAE用一半数据训练,他的创新永远是把问题拆回最开始的样子。现在,他又对着扩散模型问出了那个被忽略的问题:既然叫去噪模型,为什么不直接去噪?
你可以把高维像素空间想象成一个无边无际的3D展厅,而所有真实存在的自然图像,其实都挤在展厅一面贴满照片的墙上——这就是流形假设:看似高维的数据,其实只分布在一个低维的“曲面”上。
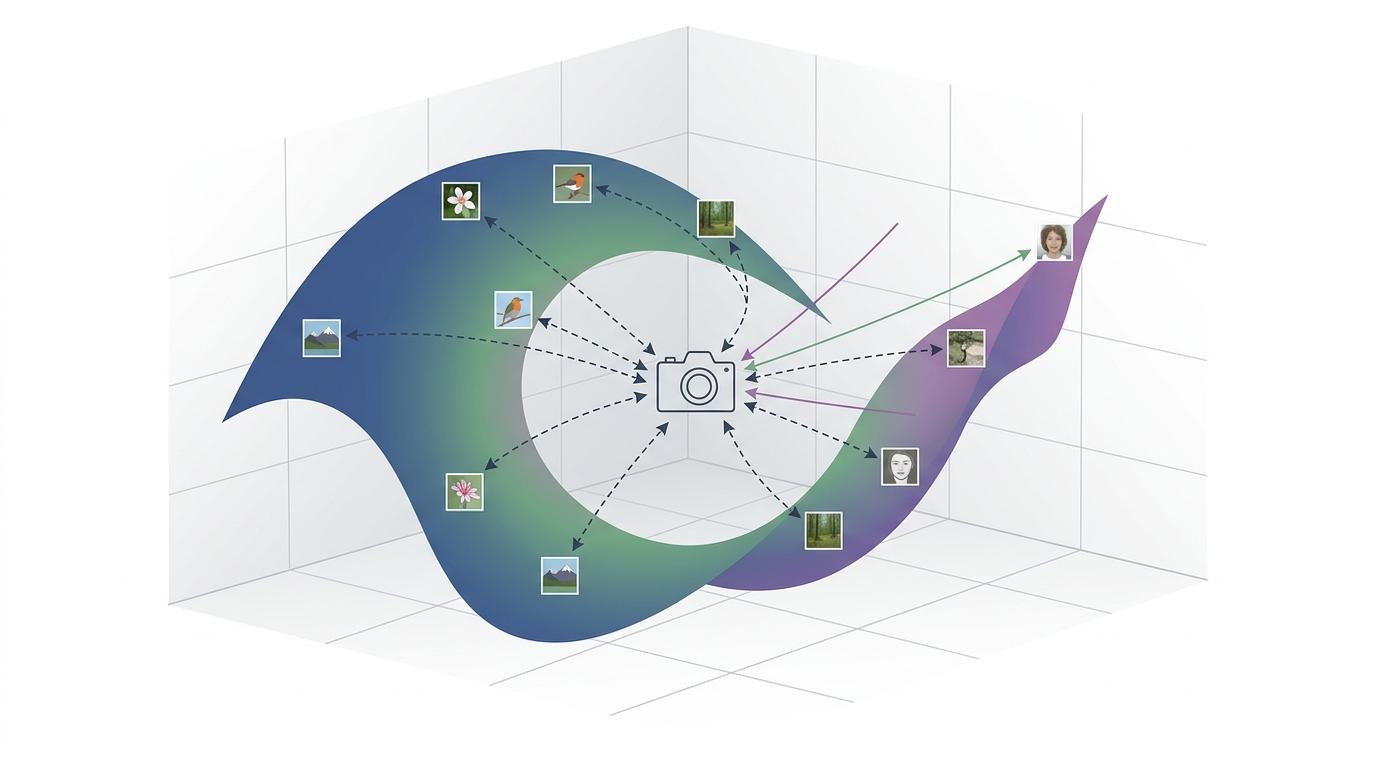
但过去的扩散模型,偏要让神经网络去拟合展厅里漫天飞舞的“雪花点”——也就是噪声。噪声是均匀填满整个3D空间的,没有任何规律可言,要让模型学会预测这些无意义的随机信号,需要的算力和模型容量呈指数级增长。尤其是当处理256×256甚至512×512的高分辨率图像时,模型很可能直接“崩溃”:生成的图像模糊、扭曲,FID指标(衡量生成图像与真实图像差异的数值,越低越好)会像坐火箭一样飙升。
何恺明团队做的,就是把模型的注意力重新拉回那面“照片墙”。他们提出的JiT架构,是一个纯粹的Transformer,没有任何额外组件:直接把原始图像切成大Patch喂进去,让模型的输出目标就是干净的图像块。
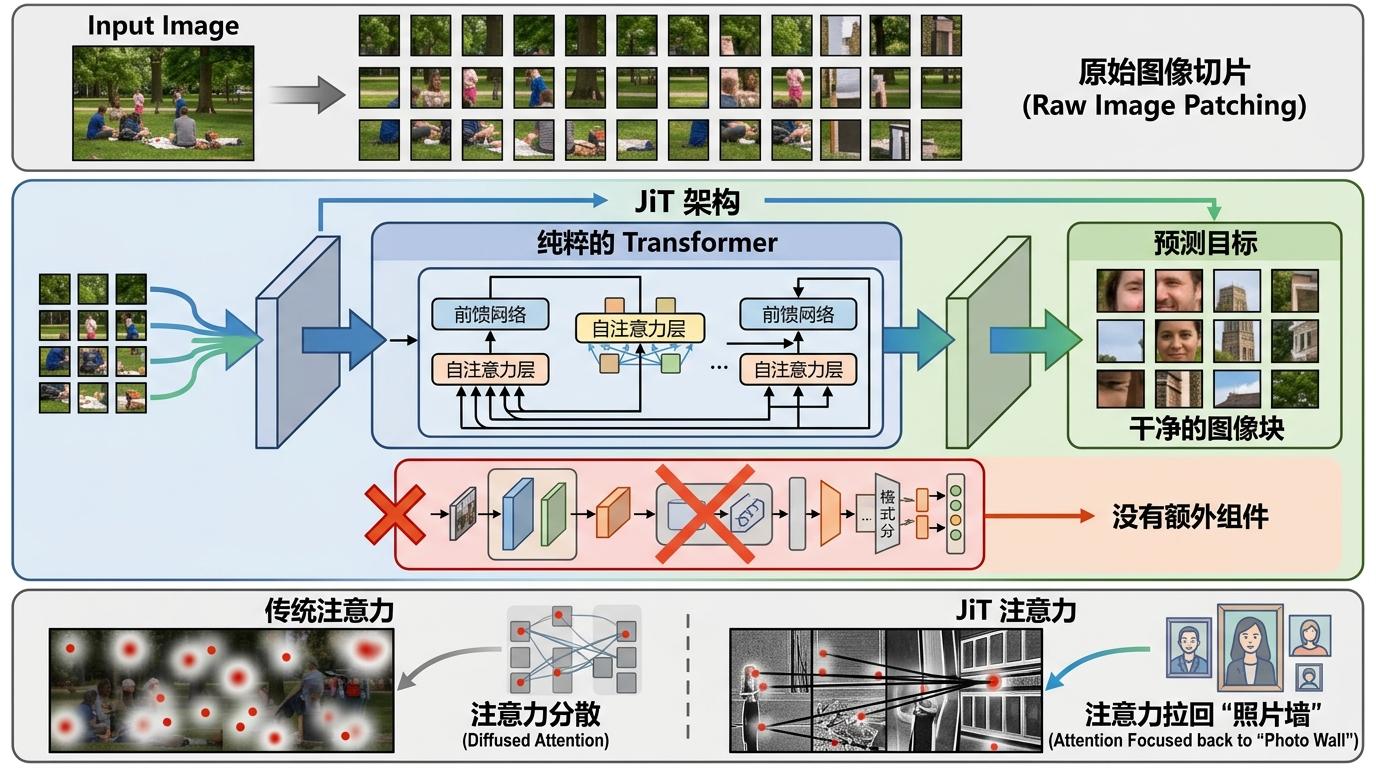
实验结果让很多人意外:在低分辨率的小图上,猜噪声和直接画图的效果差不太多;但一旦进入高维空间,传统模型的FID指数级飙升,而JiT的FID却能稳定保持在1.8左右——在ImageNet 256×256和512×512的测试中,这个成绩已经是当前的顶尖水平。
更反常识的是,当研究者给JiT人为加上一个“降维瓶颈”时,模型的生成质量反而更高了。这就像是给模型加了一个“放大镜”,让它更聚焦于那面低维的“照片墙”,而不是被展厅里的噪声干扰。
JiT的训练过程也异常简洁:不需要预训练的CLIP或DINO特征对齐,不需要复杂的感知损失函数,甚至连VAE压缩都省了——它直接在像素空间工作,让神经网络做它最擅长的事:过滤噪声,保留信号。
这几年扩散模型的发展,像极了一场“军备竞赛”:为了提升一点点生成质量,研究者们不断给模型加新模块,从预测噪声到预测速度场,从latent空间对齐到堆更多的tokenizer。但很少有人停下来问:我们是不是把问题搞复杂了?
何恺明团队的研究,其实是在给这场竞赛踩刹车。他们用实验证明,扩散模型的本质就是去噪模型,不需要让它去做猜噪声这种“无用功”。直接预测干净图像,不仅训练更稳定,需要的算力更少,生成的图像质量还更高。
这种“大道至简”的思路,已经成为何恺明团队的标志性风格。从ResNet用残差连接解决深层网络的退化问题,到MAE用一半数据训练出顶尖的视觉模型,他们的创新永远不是做加法,而是做减法——把问题拆回最本质的样子,让模型做它最擅长的事。
当AI领域的很多人都在追求“更大、更复杂”时,何恺明团队的研究像是一种提醒:真正的创新,往往不是在现有框架上叠砖加瓦,而是回到问题的起点,重新思考“我们到底要做什么”。
JiT架构的成功,不仅给扩散模型的发展指了一条新的方向,更验证了一个朴素的道理:最有效的解决方案,往往是最简单的。未来的生成模型,或许会从这场“军备竞赛”中抽身,重新回归“去噪”的本质——毕竟,让模型直接画图,才是对“去噪模型”最朴素的尊重。