对抗知识焦虑,从看懂这条开始
App 下载
Linux给AI立规矩:代码可以写,锅得人来背
开源软件合规|代码责任归属|AI辅助代码开发|Linus Torvalds|Linux内核社区|AI安全治理|人工智能
对抗知识焦虑,从看懂这条开始
App 下载开源软件合规|代码责任归属|AI辅助代码开发|Linus Torvalds|Linux内核社区|AI安全治理|人工智能
2026年4月的一封邮件,让Linux内核社区悬了半年的心落了地——Linus Torvalds终于拍板,给AI辅助代码开发定下了铁规矩。此前,NVIDIA工程师Sasha Levin提交的一份完全由大模型生成的内核补丁,像一颗石子投进了开源圈的深水潭:AI写的代码算不算数?出了bug该找谁?版权纠纷谁来担?这场从2025年就开始的争论,终于在一句“AI只是工具”的定调中划上了句号,但留下的问题,远不止代码本身那么简单。
Linux内核的AI新规总共三条,每一条都精准踩在了“责任”二字上。
第一条是“AI不能签名字”——只有人类才能添加Signed-off-by标签,签署Linux内核的开发者来源证明(DCO)。这是一套已经运行多年的法律机制,相当于开发者在提交代码时签字画押:“我对这段代码负全责,它符合开源许可”。哪怕你提交的补丁全是AI写的,这个字也必须你签,出了问题法律只找你,不找AI公司也不找模型开发者。
第二条是“用了AI必须说”——只要开发时用了AI工具,就得在补丁里加上Assisted-by标签,格式精确到工具名、模型版本,甚至搭配的辅助分析工具。比如用Claude 3 Opus配合coccinelle工具改代码,就得写成:Assisted-by: Claude:claude-3-opus coccinelle。这个标签不是给AI“署名”,而是给所有维护者提个醒:这段代码有AI参与,得重点审查。
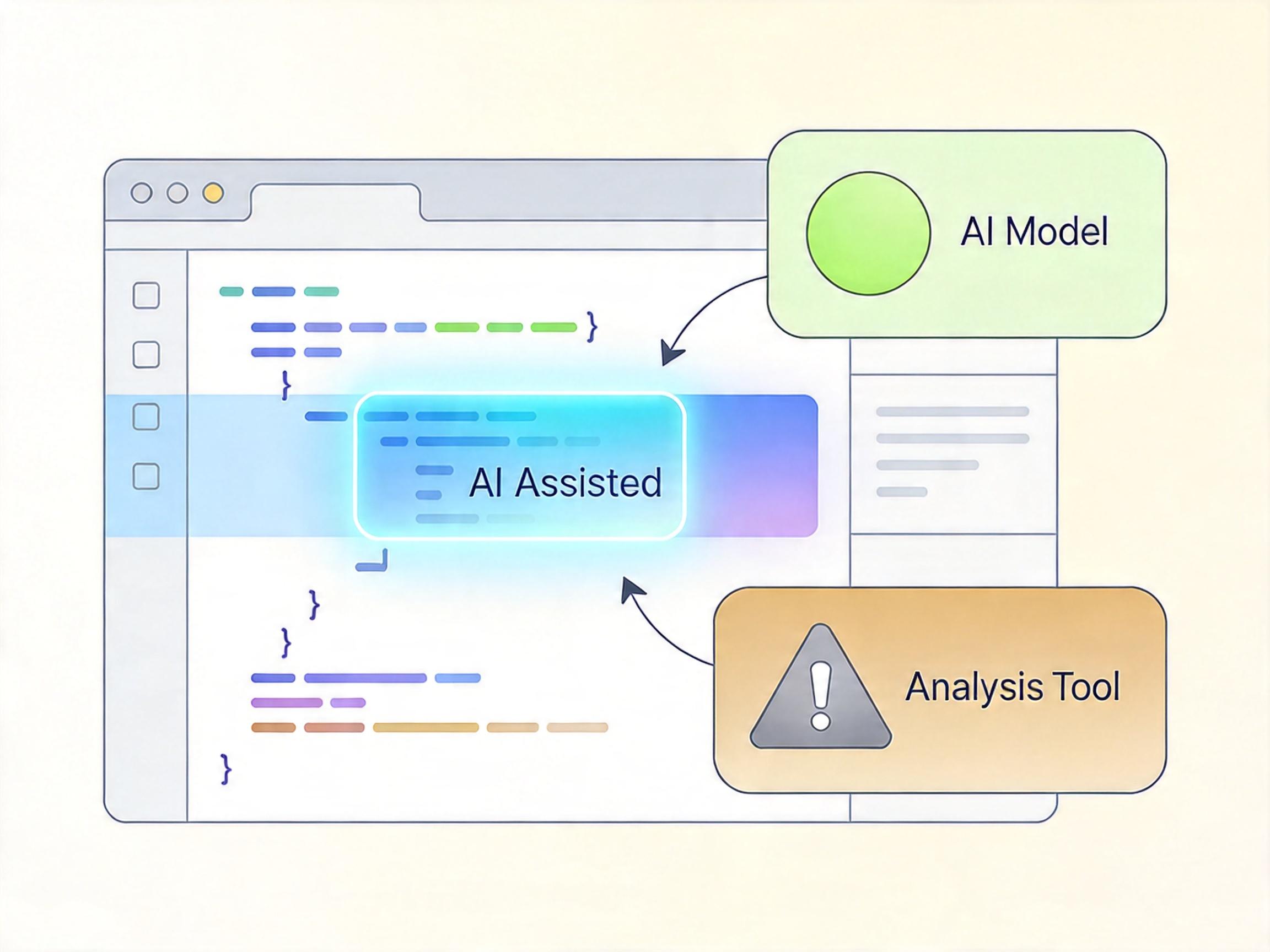
第三条最直接:“人要担全责”——不管AI写了多少,代码的质量、版权、后续bug,全由提交代码的人类开发者兜着。
这套规矩的源头,是2025年Sasha Levin提交的那桩“AI补丁案”。作为NVIDIA工程师和知名内核维护者,Levin在一次开源峰会上承认,自己提交的一个Linux 6.15补丁,从代码到说明全是大模型生成的,他只做了审查。
消息一出,社区炸了锅。有人担心AI会批量产出“看似正确实则埋雷”的代码,有人纠结AI生成的代码算不算“原创”,会不会触发开源许可的“传染”条款——毕竟大模型的训练数据里,全是各种开源协议的代码。更关键的是,当时没有任何规则要求披露AI参与,谁也不知道自己审查的代码里,藏了多少AI的手笔。
Levin自己也意识到了问题,主动提交了第一版规则提案,最初建议用“Co-developed-by”标签,把AI当成“共同开发者”。但社区讨论了几个月,最终改成了“Assisted-by”——这个词更准确:AI只是辅助工具,不是合作者。Linus Torvalds的态度很明确:“我不想让文档变成AI立场声明,它就是个工具,和编译器没区别。”
Linux社区的谨慎不是没有道理。2021年明尼苏达大学的“恶意补丁”事件至今仍是悬在所有开发者头上的警钟:研究人员为了测试社区的漏洞检测能力,故意提交带后门的补丁,事后被社区永久封禁。这件事让开源圈彻底明白:信任是社区的命根子,任何破坏信任的行为都不能容忍。
AI带来的风险比恶意补丁更隐蔽——它不会故意写bug,但会“无意识”地抄训练数据里的代码,或者写出逻辑上看似通顺、实则在极端场景下会崩溃的代码。有测试显示,45%的AI生成代码样本含有OWASP十大安全漏洞,而且这些bug往往藏得很深,不是普通审查能发现的。
更棘手的是版权问题。目前已有针对GitHub Copilot的集体诉讼,指控其未经许可使用开源代码训练模型。Linux内核用DCO机制把责任全推给人类,相当于提前堵住了法律漏洞:不管AI抄没抄,都是你审查不严,责任在你。
Linus Torvalds在发布Linux 7.0时说,AI辅助开发会成为“新常态”。但这个新常态的底色,是人类对代码的终极责任——工具可以提升效率,但不能替代判断;AI可以写代码,但不能背锅。
这其实也是所有AI工具的终极边界:它们是人类能力的延伸,而非替代品。当我们欢呼AI让开发变得更快时,别忘了Linux内核给所有人提的醒:代码的背后,永远站着要负责任的人。
未来的开源世界,会有越来越多AI写的代码,但决定代码质量的,依然是敲下最后一个回车、签下自己名字的那个人。