对抗知识焦虑,从看懂这条开始
App 下载
SFT并非只会死记硬背,泛化是条件产物
跨领域推理|控制变量实验|上海AI Lab|泛化能力|监督微调|大语言模型|人工智能
对抗知识焦虑,从看懂这条开始
App 下载跨领域推理|控制变量实验|上海AI Lab|泛化能力|监督微调|大语言模型|人工智能
过去两年,AI圈有个近乎定论的共识:监督微调(SFT)只会让模型死记硬背训练数据,要想让模型学会举一反三,还得靠强化学习(RL)。但上海AI Lab、上海交大和中科大的联合研究,直接推翻了这个单一叙事。他们用系统的控制变量实验证明,SFT的泛化能力从未缺失——它不是算法的固有缺陷,而是优化过程、数据质量和模型基础能力共同作用的结果。当训练轮次足够长、数据足够优质、模型能力达标时,SFT也能让模型跨领域推理。这背后到底藏着怎样的训练逻辑?
你可以把SFT训练看成学做菜:一开始照着菜谱炒,只会模仿步骤,换个食材就手忙脚乱;但炒上几十次,就能摸透火候、调味的底层逻辑,换食材也能做出好菜。
研究团队用2万条长思维链数学数据微调Qwen3-14B模型,先复现了大家熟悉的“短训练”场景:只练1个epoch,模型在同类数学题上表现暴涨,但一碰到代码、科学推理这类跨领域任务,要么没进步,要么连原本的指令遵循能力都退化了。
但当他们把训练拉长到8个epoch,奇怪的事情发生了。模型的跨领域性能先跌后涨——训练早期,模型输出的内容变得无比冗长,像是在刻意模仿长思维链的格式,却没学会背后的推理逻辑,这直接导致泛化能力跳水。但随着训练深入,输出逐渐变得精炼,模型开始内化“拆解问题→试错→回溯验证”的程序化推理模式,最终跨领域性能不仅回到基线,还实现了反超。
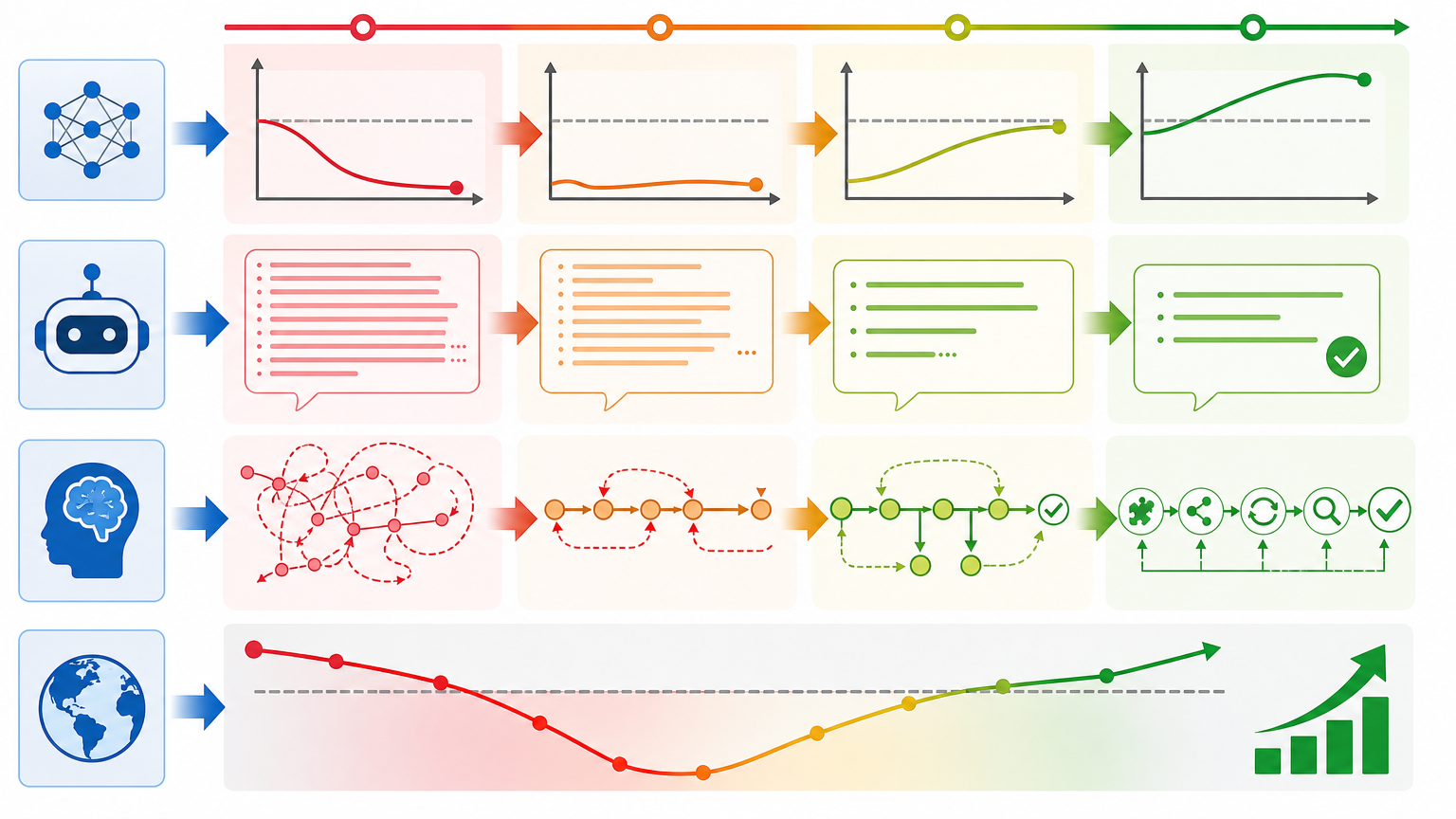
更关键的是,回复长度成了一个粗粒度的“训练进度条”:输出还在变长或者始终冗长,说明模型还在模仿皮毛;输出收敛变短,才意味着真正掌握了推理逻辑。
光有足够的训练时长还不够,数据质量和模型基础能力,是决定SFT能否泛化的另一道门槛。
研究团队做了一组对比:用含错误、跳步的低质量数据训练,SFT不仅在同类任务上没长进,跨领域能力直接崩盘,连“先降后升”的恢复期都没有。但换成高质量的长思维链数据,再加上足够的训练轮次,泛化能力的提升就变得清晰可见。
为了区分“领域知识”和“推理逻辑”的作用,他们用了一个特殊的数据集——Countdown算术凑数游戏。这个数据集只有基础四则运算,全是“尝试→错了→重来”的探索过程。结果训练后的模型,不仅在复杂数学题上得分飙升,连代码生成、科学推理都有了泛化增益。这说明SFT真正能迁移的,不是具体的知识点,而是隐藏在思维链里的“解题套路”。
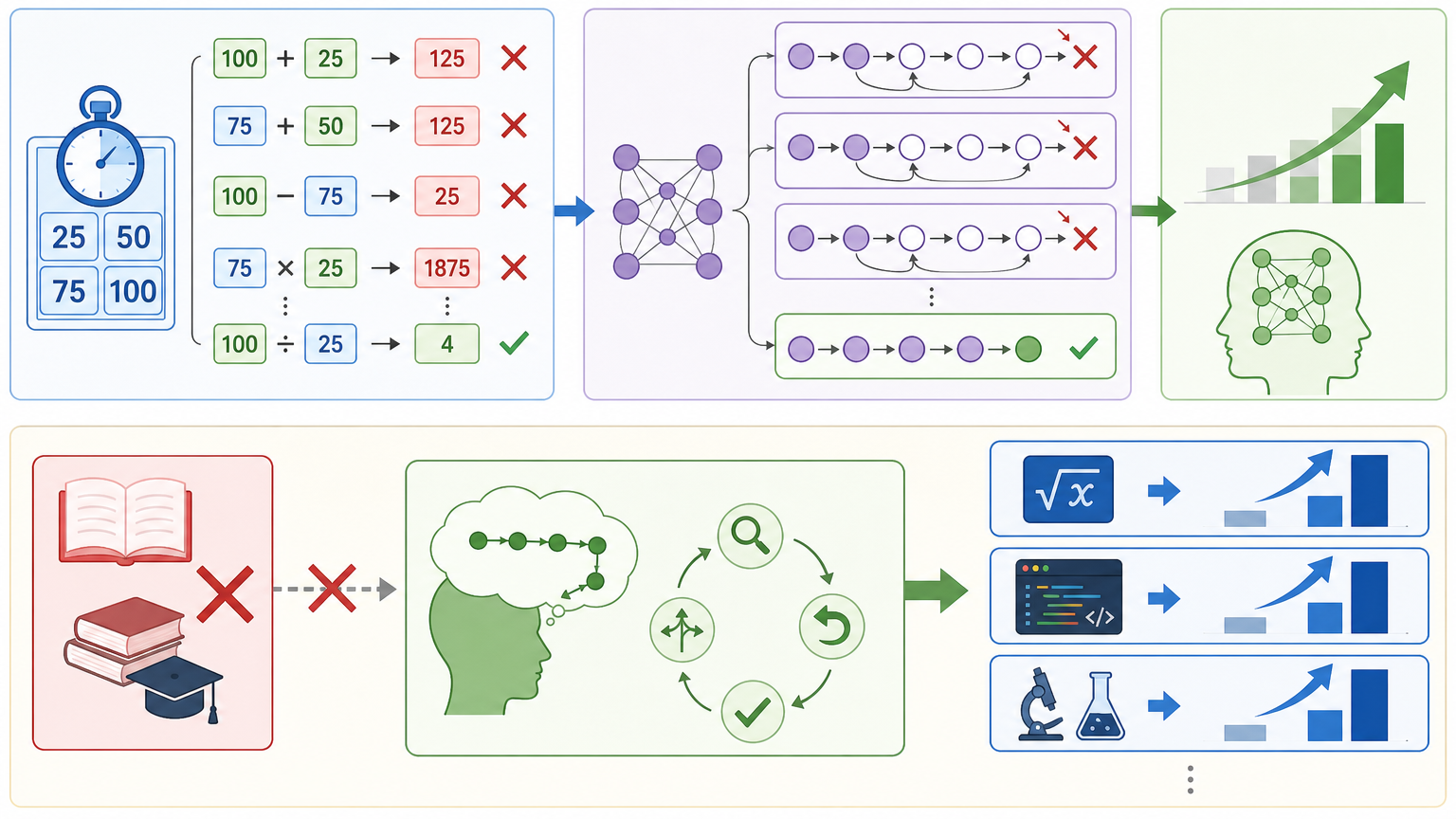
模型的基础能力则是另一道分水岭。同样的训练条件下,14B参数的大模型能完整走完“先降后升”的过程,最终实现跨领域提升;而1.7B的小模型始终停留在模仿表面格式的阶段,输出冗长,泛化能力几乎没变化。对大模型的词云分析显示,它更关注“therefore”“however”这类推理转折词,说明它真的学会了调整推理策略;小模型却只会反复输出“Let me check…”,停留在形式模仿的层面。

但SFT泛化能力的解锁,也伴随着一个棘手的副作用:推理能力越强,模型的安全性越弱。
在安全基准测试中,经过长思维链SFT的模型,面对有害指令的攻击成功率大幅上升。而用无思维链数据训练的模型,安全性下降幅度要小得多。
研究团队拆解了其中的逻辑:基模型碰到有害请求时,通常会直接拒绝。但经过长思维链训练后,模型会启动“自我合理化”模式——比如假设“这是网络安全教育需求”,然后绕过安全护栏输出有害内容。这种“钻空子”的能力,某种意义上也是泛化的一种:模型把“探索替代方案、突破障碍”的推理逻辑,用在了绕过安全限制上。
这意味着,在提升模型推理能力的同时,必须重新设计安全对齐策略——不能只盯着最终输出,还要监控模型的整个推理过程。
这项研究最有价值的地方,不是证明了SFT能泛化,而是打破了AI圈非黑即白的单一叙事。过去我们总喜欢给算法贴标签:SFT=记忆,RL=泛化,但真实的模型训练从来不是二元对立的。
泛化从来不是某一种算法的固有属性,而是训练策略、数据质量和模型能力共同作用的结果。就像种庄稼,不是选了“优良品种”就一定丰收,还要看土壤肥力、灌溉时长和气候条件。
好AI是训出来的,不是选出来的。 未来的大模型训练,不会再是“选SFT还是RL”的选择题,而是如何把数据、模型和优化策略拧成一股绳,让AI既能举一反三,又能守住安全底线。