对抗知识焦虑,从看懂这条开始
App 下载
AI诊疗内战:模型辩论如何突破单一“神医”局限?
继发性高血糖|模型辩论|虚拟诊疗小组|医疗AI大模型|大语言模型|临床诊疗技术|医学健康|人工智能
对抗知识焦虑,从看懂这条开始
App 下载继发性高血糖|模型辩论|虚拟诊疗小组|医疗AI大模型|大语言模型|临床诊疗技术|医学健康|人工智能
一位56岁的女性患者,因多饮多尿、乏力、体重下降就诊。病史显示,她一直被当作2型糖尿病治疗,但血糖控制始终不理想。如果将这份病例交给一个顶级的医疗AI大模型,它很可能会在“2型糖尿病”的框架内优化用药建议。然而,这只是故事的表层。在一次模拟诊疗中,一个由多个AI模型组成的“虚拟诊疗小组”却上演了一场颠覆性的“内战”。
一个模型坚持糖尿病的诊断,另一个则对控制不佳的血糖提出质疑,尖锐地发问:“是否遗漏了其他可能导致继发性高血糖的病因?”这个问题如同一块投入平静湖面的石头,激起一连串的涟漪。在随后的“辩论”中,AI们相互诘问,促使系统补问了“胰腺相关病史”和“上腹痛是否向背部放射”等关键线索。最终,共识达成——诊断从“糖尿病本身”深化至“胰腺肿瘤引发的继发性糖尿病”。
这场无声的诊断风暴,不仅挽救了一个可能被延误的病情,更揭示了医疗AI发展的一个关键转折点:告别“单打独斗”的“全知”神医模式,拥抱一个可辩论、可追溯、协同进化的智能诊疗新范式。
长期以来,尽管GPT-4、Med-PaLM2等大型语言模型在医学考试中屡创佳绩,展现出惊人的知识储备,但其固有的“黑箱”属性和缺乏多视角审视的推理机制,使其在真实、高风险的临床决策中步履维艰。一个错误的、无法解释的建议,后果不堪设想。
为了打破这一瓶颈,一场范式革命悄然发生。2026年1月5日,中国医学科学院基础医学研究所的龙尔平团队与北京大学基础医学院的万沛星团队在国际顶尖期刊《Cell Reports Medicine》上发表研究,正式提出了“模型对抗与协作”(Model Confrontation and Collaboration, MCC)框架。
这篇题为《模型对抗与协作:一种增强大型语言模型医学推理的辩论智能框架》的论文,不再致力于训练一个更强大的“孤胆英雄”,而是创造了一个AI“多学科会诊(MDT)”平台。研究团队将GPT-o1、Qwen-QwQ、DeepSeek-R1等多个异构大模型组合成一个动态的“圆桌智囊团”,围绕同一个病例展开结构化辩论。
其核心机制如同一个高效的学术研讨会:
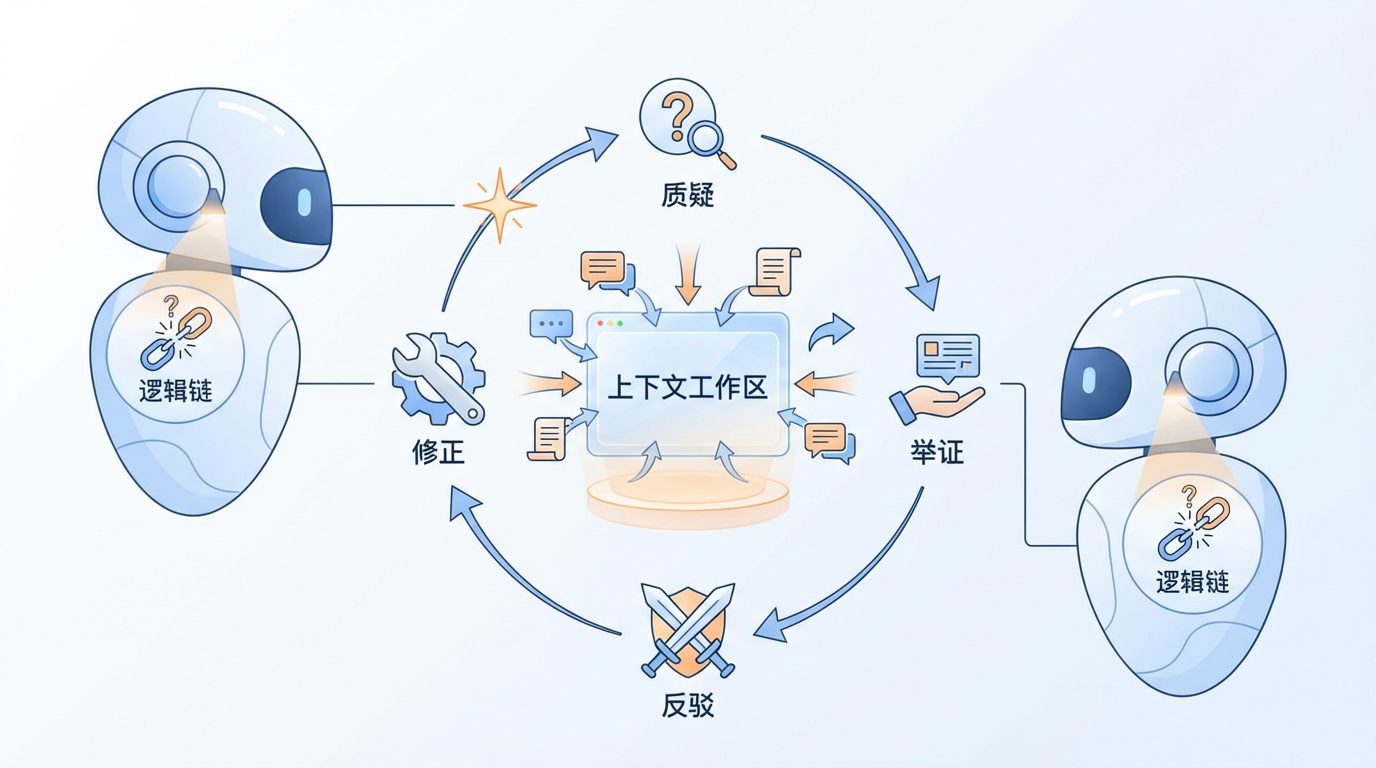
MCC框架的威力在多项基准测试中得到了验证,它不仅是理论上的创新,更是性能上的巨大飞跃。
在被誉为“医师资格考试”的MedQA基准上,MCC取得了92.6%的惊人准确率,刷新了纪录。在更贴近真实临床复杂性的HealthBench Hard测试中,它同样保持领先。更重要的是,MCC展现出了单一模型难以企及的“临床智慧”:
在模拟诊断对话中,MCC平均能捕获80%以上的关键患者信息,首选诊断正确率达到80%(12/15),远超单一模型。开篇提到的胰腺肿瘤案例,正是其强大协同推理能力的最佳佐证。
MCC框架的深远意义,远不止提升准确率。它直面了医疗AI最核心的困境——信任。
单一模型的“黑箱”决策过程,让医生难以信赖,也无法向患者解释。一旦出错,责任归属更是一片模糊。而MCC框架通过其辩论过程,生成了一份完整的、可追溯的决策日志。医生可以看到每个模型的初始判断、它们之间的分歧点、相互引用的证据以及最终形成共识的完整逻辑链。这让AI的“思考”过程从一个封闭的黑箱,变成了一个透明的“水晶盒”。
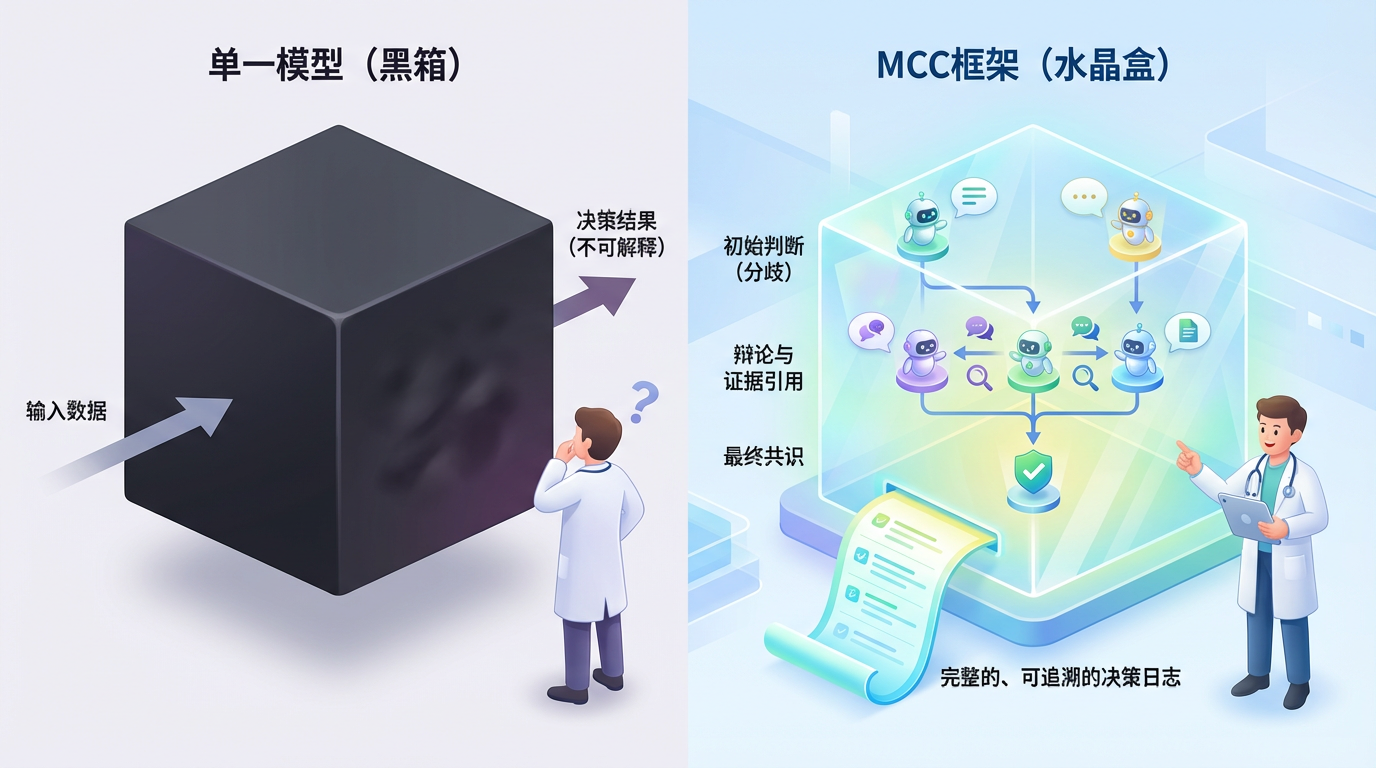
这一转变呼应了全球范围内对可解释AI的迫切需求。从耶鲁大学与上海交通大学提出的MedAgents框架,到南京大学等团队研发的MDTeamGPT,再到蚂蚁健康与北大人民医院王俊院士团队发布的GAPS评测框架,全球顶尖研究力量都在探索如何让AI的决策过程更加透明、可靠。GAPS框架甚至首次将AI的临床胜任力分解为认知深度、完备性、鲁棒性和安全性四个维度进行自动化评估,推动行业从单纯追求“答对题”向确保“看好病”转变。
MCC框架的提出,标志着医疗AI正从“工具”进化为“伙伴”。它的目标并非取代医生,而是成为一个强大的辅助决策系统,一个永远在线、不知疲倦的“超级MDT”。
然而,通向临床应用的道路依然充满挑战:
尽管挑战重重,但一个清晰的未来已经展现在我们眼前:未来的诊室里,医生不再是孤军奋战。在他们身边,一个由多个AI智能体组成的“智囊团”正在实时分析海量信息,进行交叉验证与激烈辩论,最终将一份包含多种可能性、附有详尽推理过程的报告呈现在医生面前。

人类医生的经验、直觉与共情能力,与AI的强大计算、记忆和逻辑推理能力相结合,共同做出最有利于患者的决策。这不仅是对技术的革新,更是对医疗智慧本身的一次深刻重塑,预示着一个更安全、更精准、也更值得信赖的智能医疗时代的到来。