对抗知识焦虑,从看懂这条开始
App 下载
0.2M参数的小模型,碾压脑电去噪大模型
小参数模型|便携设备|脑电信号去噪|BandRouteNet|多模态视觉|人工智能
对抗知识焦虑,从看懂这条开始
App 下载小参数模型|便携设备|脑电信号去噪|BandRouteNet|多模态视觉|人工智能
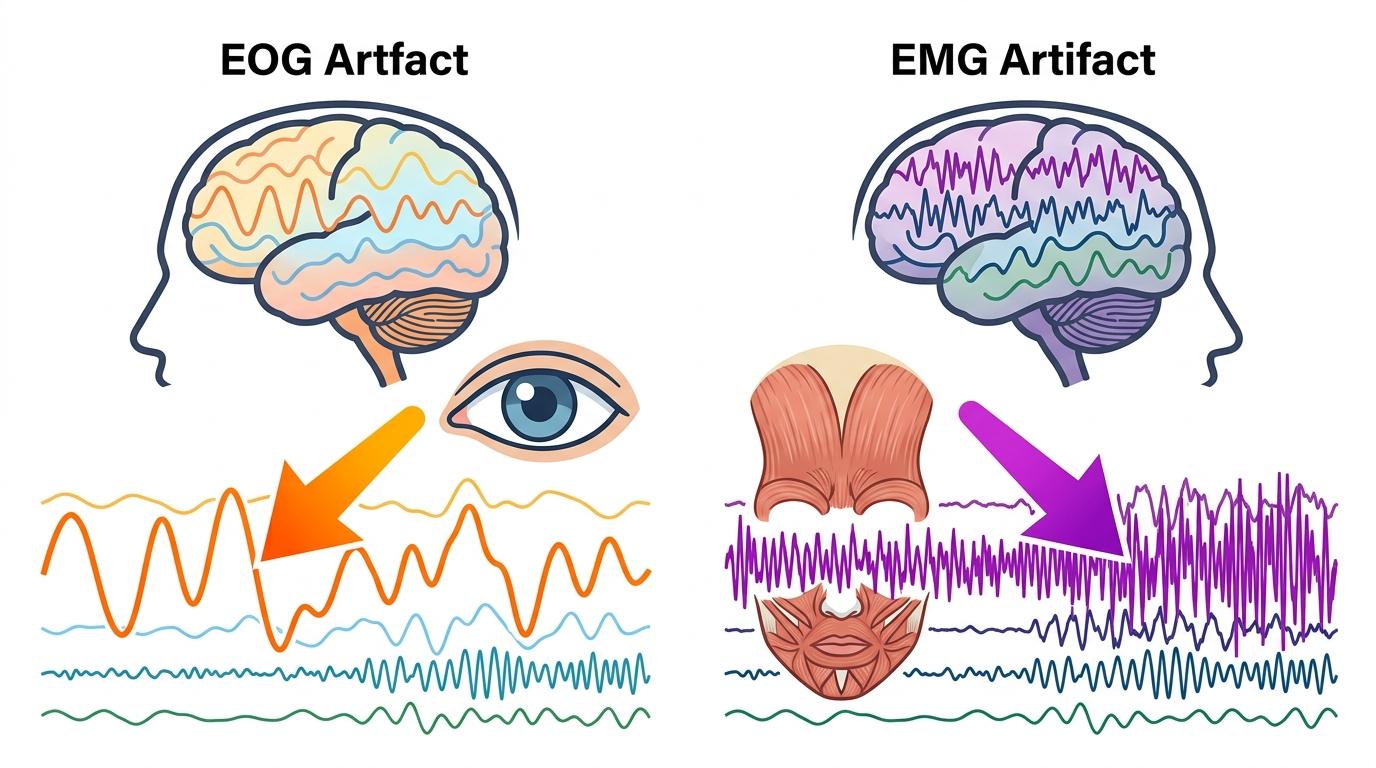
想象你戴着脑电帽做注意力训练,刚集中精神,一眨眼、皱下眉,屏幕上的脑波信号就被搅成了糊——眼动、皱眉产生的电信号,幅度是真实脑波的几十倍,像个蛮横的“噪音刺客”直接把大脑的“悄悄话”盖过去。传统方法要么得额外贴电极测眼动,要么不分青红皂白把所有信号削一遍,要么带着大模型的沉重算力根本没法装在便携设备里。但2026年4月出现的BandRouteNet,凭着0.2M的参数——还不到很多大模型的1%——却在标准测试集上把Transformer、U-Net这些热门模型全比了下去。它是怎么做到用这么少的参数,精准“抓刺客”的?
脑电信号里的噪音其实很“挑食”:眼动产生的EOG伪迹专盯低频段(0-8Hz),皱眉咬牙的EMG伪迹则在高频段(13Hz以上)撒野。传统模型要么把整个信号当一团处理,要么只在时域或频域单干,要么对所有频段用一样的去噪力度——结果要么没打准噪音,要么把有用的脑波也削没了。
BandRouteNet先把含噪脑电用傅里叶变换拆成6个标准频段,就像把混装的豆子按大小分成6堆。每个频段的信号会先过一个共享参数的编码器,再贴上一个“频带身份标签”——相当于给每堆豆子盖个戳,让模型不会把低频的“绿豆”和高频的“红豆”搞混。这还不够,它还有个“全局观察员”:直接处理原始全频段信号,用轻量的GRU和1D卷积提取整个时间段的上下文信息,输出两个关键参数τ和ψ。
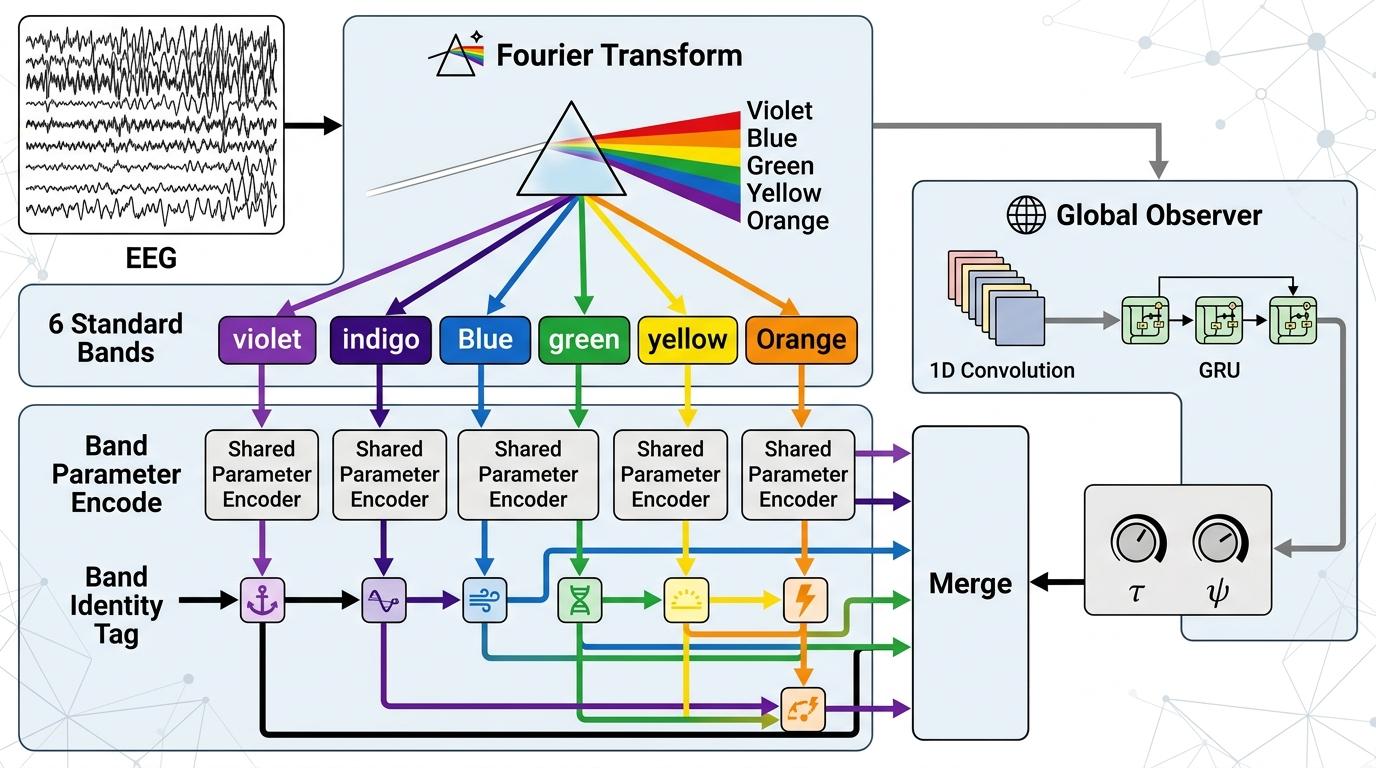
你可以把这两个参数想象成给每个频段的“处理指南”:τ是“缩放旋钮”,ψ是“偏移滑块”,通过FiLM(特征线性调制)机制,给每个频段的特征做针对性调整——比如发现低频段眼动噪音多,就把低频特征的敏感度调高,高频段肌电噪音多,就给高频特征加个专属滤镜。这一下就把全局的“战场态势”和局部的“精准打击”结合了起来。
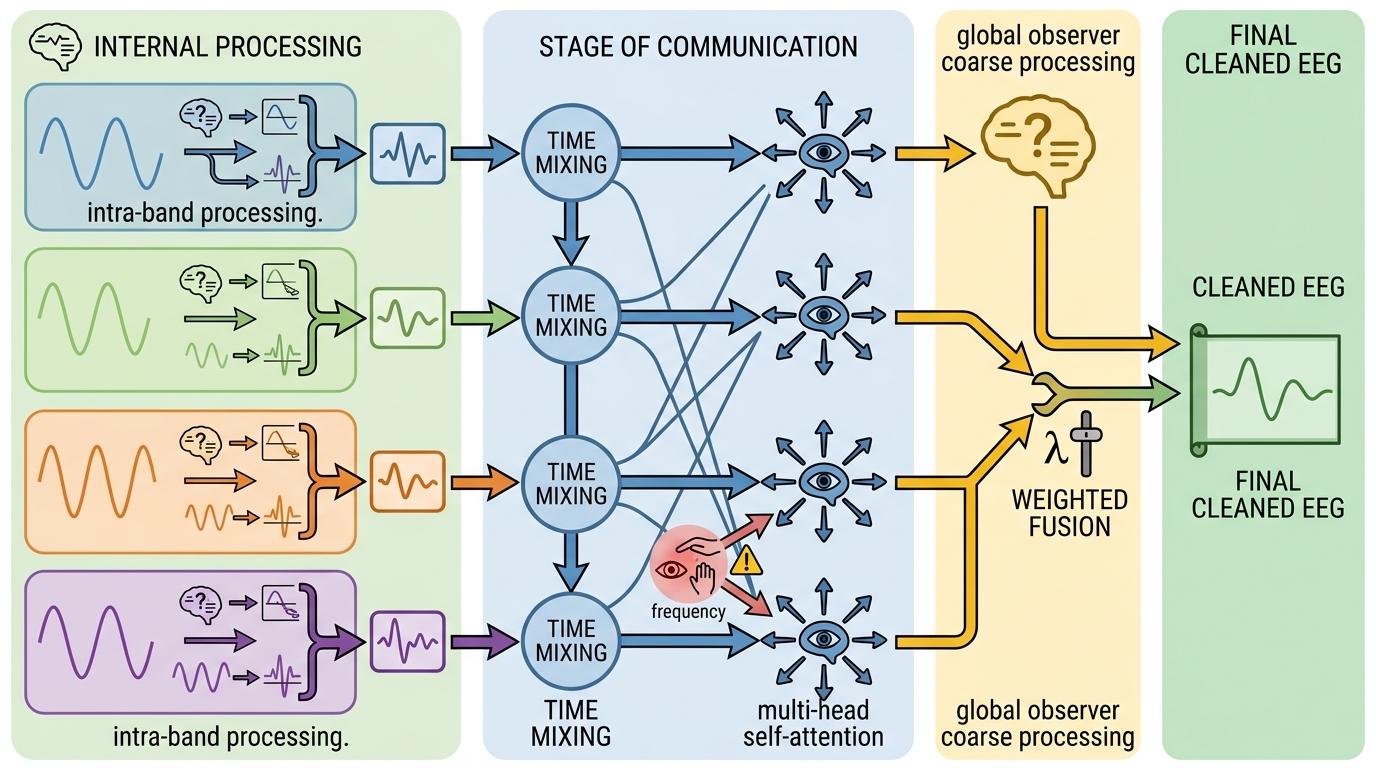
BandRouteNet最聪明的设计,是那个能“看人下菜碟”的伪迹路由机制。以前的模型不管信号脏不脏,上来就全频段一通操作,结果干净的脑波也被磨得没了细节。而这个路由机制,会给每个频段的每个时间点,预测一个0到1之间的软掩码g_k。
当g_k接近0时,说明这个时间点的这个频段很干净,模型就直接保留原始信号;当g_k接近1时,说明这里被噪音污染严重,模型就用上专门的去噪模块处理。生成这个掩码的路由器也很巧妙:一边用1D深度可分离卷积盯着局部的噪音突变,比如突然的眨眼;一边用时序平均池化看全局的信号规律,比如这段时间里眼动噪音一直很多,两边信息融合后再输出掩码——既不会放过瞬间的噪音,也不会误判整体的信号趋势。
为了让各个频段能互通消息,所有频段的处理结果还会开个“圆桌会议”:先在每个频段内部做时序混合,再用多头自注意力让不同频段互相“交流”——比如低频段发现了眼动噪音,会告诉高频段“这段时间受试者在眨眼,你注意有没有连带的肌电噪音”。最后,频段处理的结果和全局观察员的粗处理信号,再通过一个动态门控参数λ加权融合,得到最终的干净脑电。
实验数据最能说明问题:在EEGDenoiseNet测试集上,它处理眼动噪音时,时域相对均方根误差低至0.3831,相关系数达到0.9156,信噪比提升了13.98dB——全是所有对比模型里的最好成绩,而它的参数只有0.2M,是Simple-CNN的1/84,EEGDNet的1/4。
更值得关注的是,BandRouteNet的轻量设计,直接解决了脑电技术落地的核心难题:便携性。以前的脑电去噪模型,要么得靠大型服务器算力,要么得在设备上装笨重的芯片,根本没法做成戴在头上的便携设备。而0.2M参数的模型,甚至能在普通的嵌入式设备上跑起来,这意味着以后我们可能戴着个轻便的脑电帽,就能在户外实时做注意力训练、睡眠监测,不用再泡在实验室里。
当然它也有局限:目前只在EEGDenoiseNet这一个数据集上做了测试,真实临床场景里的脑电信号会有更多类型的噪音,比如心电、呼吸、电极接触不良的干扰;而且现在它只能处理2秒的信号片段,要处理连续的实时脑电数据流,还得解决延迟和连续处理的问题。但这些都是可以通过后续优化解决的细节,它已经给脑电去噪指了一条新路子:与其堆参数搞大模型,不如把力气花在精准理解信号的规律上。
从依赖专家经验的传统滤波,到堆参数的深度学习模型,脑电去噪一直卡在“要么不准,要么太重”的死胡同里。BandRouteNet的出现,就像给这个死胡同开了一扇窗:原来不用把所有力气都花在堆模型规模上,只要精准抓住信号的规律,用对方法,小模型也能打赢大仗。
好钢用在刀刃上,算力花在需要处。这不仅是脑电去噪的破局点,更是所有AI技术落地的核心——真正的高效,从来不是做更多,而是做对事。