对抗知识焦虑,从看懂这条开始
App 下载
大模型泛化:从实验室到现实的三道坎
无监督适应|AI误诊|泛化能力|香港城市大学|李皓亮团队|大语言模型|人工智能
对抗知识焦虑,从看懂这条开始
App 下载无监督适应|AI误诊|泛化能力|香港城市大学|李皓亮团队|大语言模型|人工智能
当你在三甲医院拍的CT片,拿到基层诊所的AI系统里却被误诊;当能解高数题的大模型,面对一份陌生的行业合同却答非所问——你遇到的就是大模型的「泛化死穴」。香港城市大学李皓亮团队的研究,正试图把这些在实验室里无所不能的AI,拉进充满变量的真实世界。不用重新训练,不用标注新数据,AI能不能学会「入乡随俗」?这正是当下大模型从「好看」到「好用」的核心命题。
你可以把训练好的大模型想象成一个只会做模拟题的学生——换个题型、换个出题风格,成绩立刻跳水。过去要解决这个问题,要么重新刷海量新题(重训练),要么给它划重点(标注数据),成本高到离谱。
李皓亮团队提出的「测试时自适应框架」,相当于让学生在考试现场临时调整答题策略,不用提前学新知识点。以医学图像分割为例,这个框架会在AI读片时,自动对比当前图像和它「见过」的高质量影像,用一种叫ADIC的指标悄悄评估自己的分割准不准,再通过特征融合修正结果——全程不用改动模型的任何参数,也不需要新的标注数据。
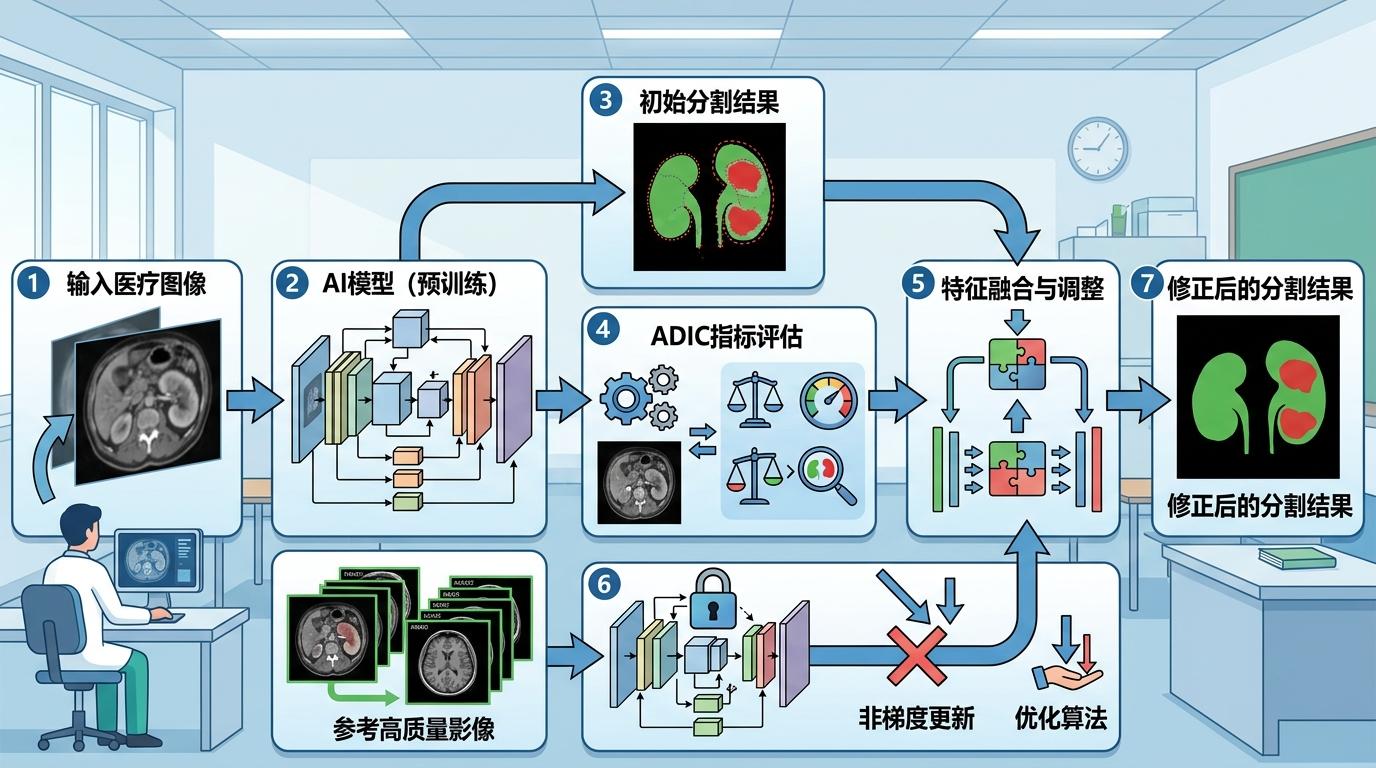
在多域心脏和脑肿瘤分割测试中,这个框架让AI的平均Dice系数(分割精度核心指标)提升超过1%,边界误差HD95距离显著缩小。但这种「现场补课」也有代价:它需要多次运算来验证结果,推理时间比普通模型长了2倍多。
大模型的推理能力,常被吐槽是「死记硬背的套公式」——给它合适的示例,它能解出复杂的数学题;换个没见过的问法,立刻给出错误答案。
李皓亮团队的另一个研究,就是让AI学会「选例题」。他们用基于学习的示例选择方法,让AI在拿到新问题时,自动从记忆里挑出最相似的「例题」来参考,而不是随便套用模板。在数学推理和复杂问答任务中,这种方法让AI的准确率提升了6%以上,同时还能缩短近50%的推理步骤。
更有意思的是扩散语言模型的「自适应解码」——就像写文章时,根据上下文自动调整语气和逻辑,而不是照着固定模板往下凑。这种改进让AI生成的文本更连贯,也更贴合具体场景的需求。但这种「随机应变」的前提,是AI见过足够多样的「例题」,如果遇到完全陌生的领域,它依然会露出马脚。
泛化能力的终极考验,是让AI在完全陌生的领域也能干活。比如冷启动的智能查询路由——当企业同时用好几个不同的大模型,怎么让用户的问题自动找到最擅长的那个AI?李皓亮团队的方法,是让AI自己学习不同模型的「特长」,不用人工设定规则,就能把法律问题分给擅长文本分析的模型,把图像问题分给视觉模型,成本降低了85%,还能保持95%的准确率。
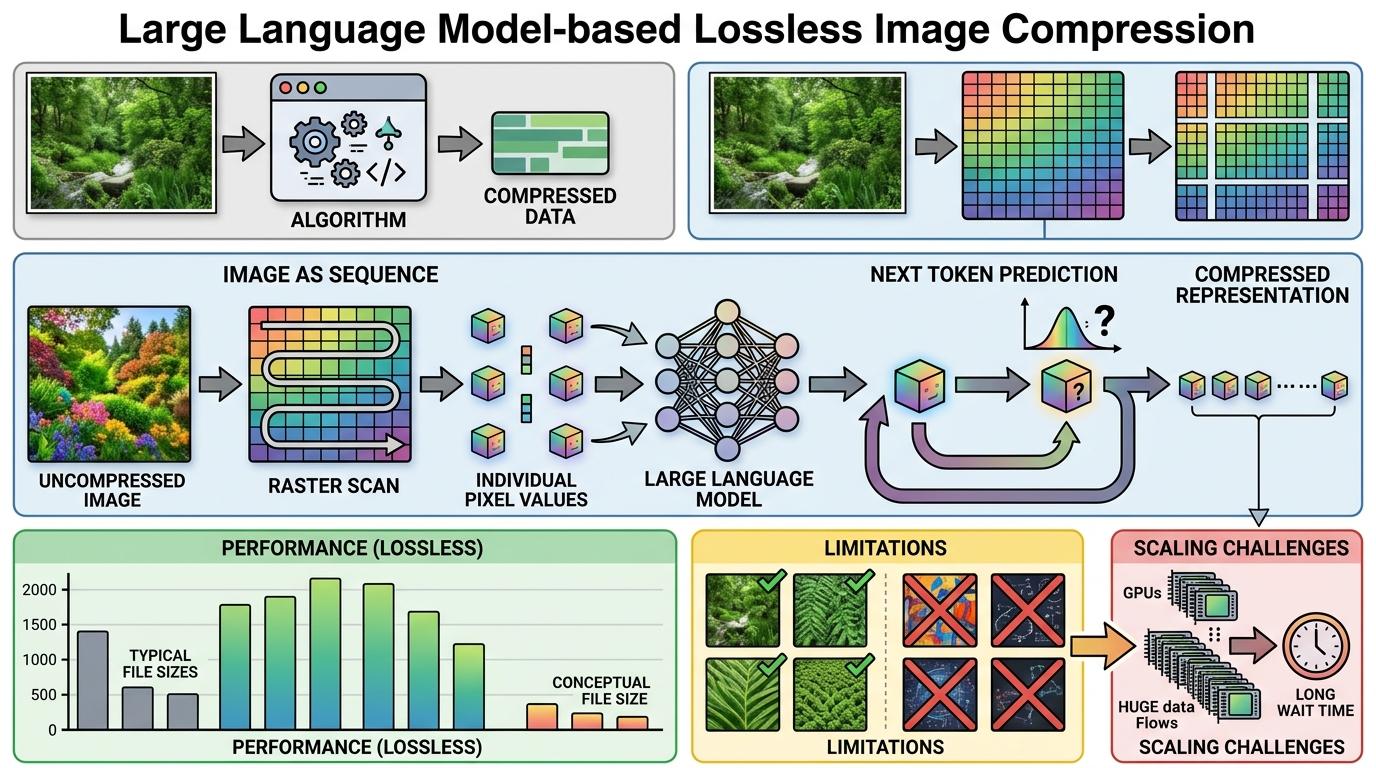
更颠覆的是把大模型用在无损图像压缩上——过去图像压缩靠的是专门的算法,现在居然能用下一词元预测的语言模型来做。这种思路把图像转换成序列数据,让大模型像预测下一个单词一样预测下一个像素,在多个基准数据集上超过了传统压缩算法。但这种方法目前还只适用于特定类型的图像,离大规模商用还有一段距离。
当我们为大模型在实验室里的惊艳表现欢呼时,更该看见它走进现实世界时的蹒跚。测试时的自适应、推理时的随机应变、跨领域的落地——每一步都是在填补「实验室理想环境」和「真实复杂场景」之间的鸿沟。
泛化不是让AI无所不能,而是让它学会适应不同的「水土」。这条路没有捷径,需要的是对每一个真实场景的打磨,对每一个技术细节的抠索。毕竟,能在手术室里准确读片、能在客服台听懂方言、能在工厂里识别故障的AI,才是我们真正需要的AI。