对抗知识焦虑,从看懂这条开始
App 下载
AI自己当裁判,代码评测进入无人时代
零人工干预|自动打分报告|代码模型对比|AI自动化评测|AI产业应用|人工智能
对抗知识焦虑,从看懂这条开始
App 下载零人工干预|自动打分报告|代码模型对比|AI自动化评测|AI产业应用|人工智能
想象一下:你不用写一行测试用例,不用盯着屏幕比对代码,甚至不用给模型打分——只要给AI一个指令,它就能自动生成复杂的测试任务,把两款AI模型放进完全隔离的环境里PK,最后输出一份比人工评测还细致的打分报告。这不是科幻场景,而是2026年已经落地的AI自动化评测技术。有人用这套方法,仅花3分钟设置,就让AI完成了两款国产代码模型的四轮对比测试,从并发bug修复到可视化仪表盘生成,全程零人工干预。这背后的核心,是让AI自己当裁判的自动化评测机制——它正在重构代码能力测试的游戏规则。
传统的代码模型评测,就像老师手动批改试卷:要先出几十道覆盖不同知识点的题目,再逐行检查学生的答案,最后还要给每道题打分、写评语。不仅耗时耗力,还容易因为个人偏好出现偏差。而AI自动化评测,相当于让最顶尖的老师同时当命题人、监考和阅卷老师——它能在几秒钟内生成上百个贴合真实工程场景的测试用例,把每个模型放进独立的“考场”避免干扰,最后用统一的评分标准给出客观结果。
你可以把这套机制想象成一场AI界的“编程奥运会”:裁判AI会先搭建好标准化的赛道,比如要求模型修复包含信号量泄漏、竞态条件的并发bug,或者从零实现支持Redis的滑动窗口限流器。参赛模型跑完后,裁判会从功能正确性、代码架构、运行效率等多个维度打分,甚至能指出某个模型的修复方案更简洁,另一个的分析报告更细致。
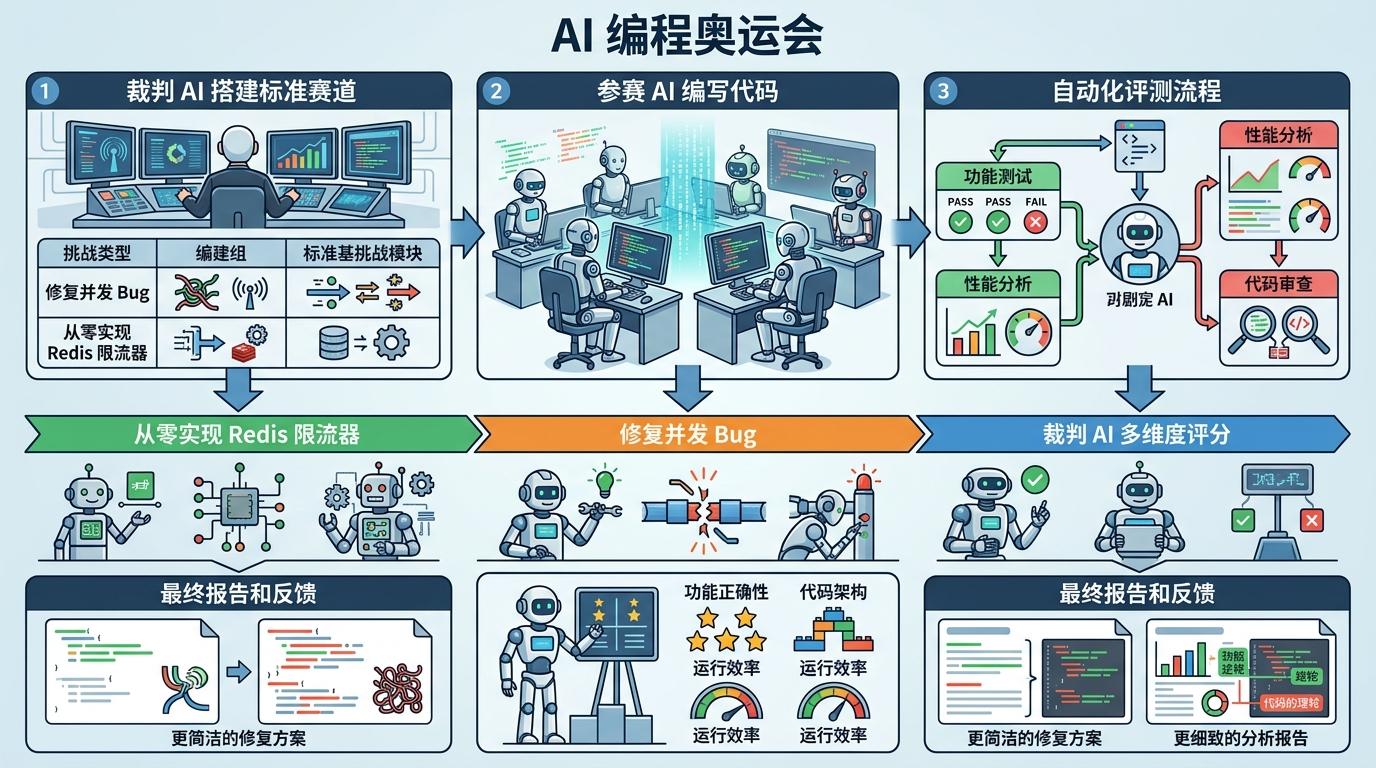
更关键的是,这套机制能把评测效率提升几个数量级。过去人工评测两款模型可能要花几天,现在AI只需要几十分钟就能完成四轮测试,还能自动生成包含所有原始数据的评测报告。
代码能力评测最大的挑战,是如何判断一段代码的“真实水平”——表面上能运行的代码,可能藏着逻辑漏洞;看起来复杂的架构,可能反而引入了新问题。传统的黑盒测试就像只看考试分数,不管学生的解题思路,很容易漏掉潜在的问题。而新一代的白盒评测技术,能直接“看穿”AI生成代码的过程。
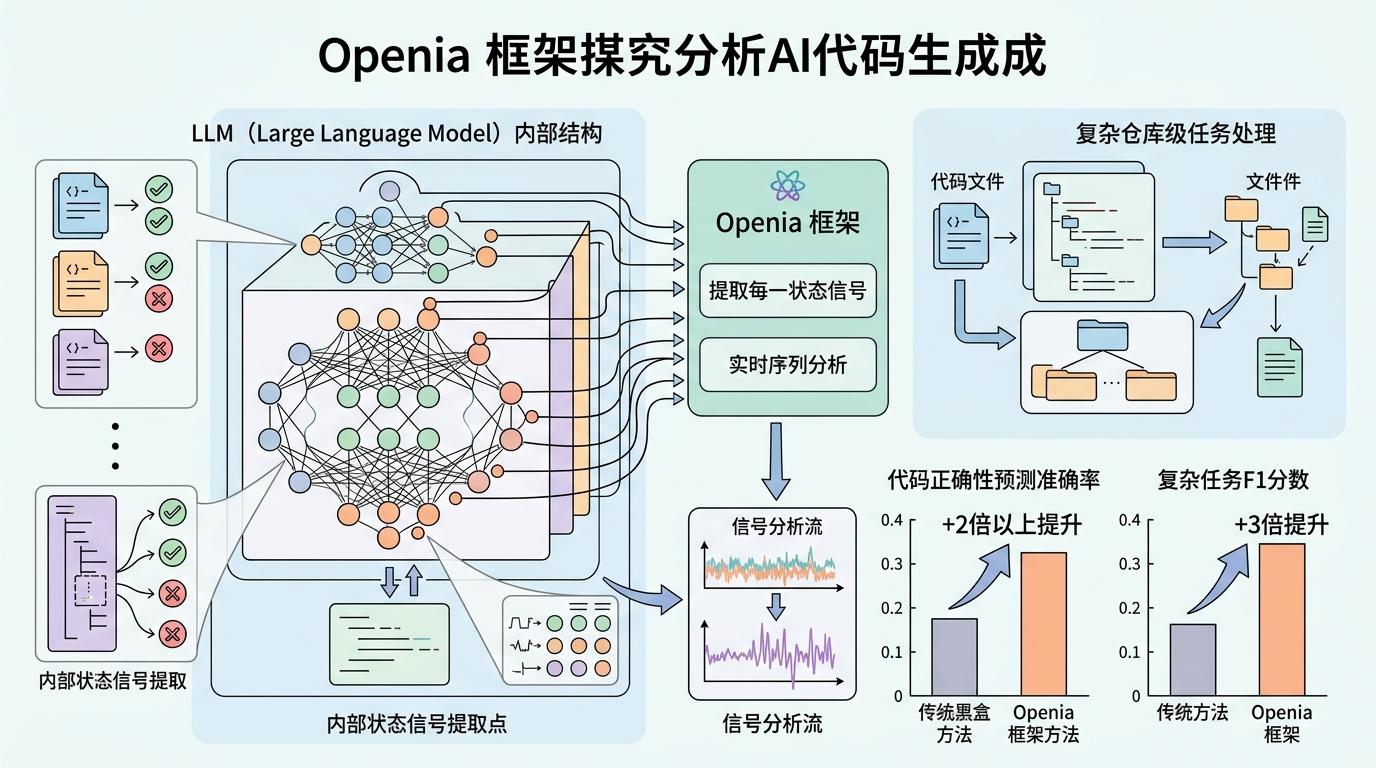
比如Openia框架,它会提取AI生成代码时的每一个内部状态信号,就像观察学生在草稿纸上的演算步骤。通过分析这些隐藏的信号,它能提前预测这段代码是否正确,准确率比传统黑盒方法高2倍以上。在处理复杂的仓库级代码生成任务时,它的F1分数甚至能提升3倍。
另一个突破是真实场景基准的建立。过去的测试用例大多是简单的小程序,就像考试只考选择题,根本测不出学生的真实编程能力。而RE2-Bench这样的新基准,直接从真实开源项目中提取了1101个复杂问题,涵盖跨文件调用、第三方API依赖、多层嵌套结构等真实工程场景。测试发现,AI模型在这些“难题”上的表现,比在简单题目上平均下降了40%以上——这才是它们的真实水平。
现在,自动化评测已经不是实验室里的技术,而是大规模AI开发流程中的标配。它能无缝集成到CI/CD流水线里,就像给代码生产线装了一个自动质检机:每次模型迭代更新,它都会自动运行上百个测试用例,如果质量不达标,就直接阻断发布。
比如有的团队用Braintrust这样的平台,每次提交代码都会自动触发评测,结果直接显示在PR评论里——开发者能立刻看到自己的改动让模型的准确率提升了多少,或者在哪个测试场景里出了问题。还有的团队用云端测试平台实现并行测试,把过去要花几小时的测试压缩到几分钟内完成,大幅缩短了模型的迭代周期。
当然,这套机制也不是完美的。AI裁判偶尔也会有“偏心”,比如更喜欢冗长的回答;真实场景的测试用例也需要不断更新,才能跟上AI模型的进化速度。但不可否认的是,自动化评测正在让AI模型的质量控制变得更高效、更客观、更贴近真实需求。
当AI开始自己评测自己,我们其实是在构建一套让AI自我进化的闭环:通过自动化评测发现模型的弱点,再用这些反馈去优化模型,然后再评测、再优化。这个过程不需要太多人工干预,却能让AI的代码能力以肉眼可见的速度提升。
未来的AI编程,可能就像现在的软件开发一样:自动化评测会成为基础设施,每一行AI生成的代码,都会经过几十甚至上百个自动化测试的检验。而我们要做的,就是给AI指明方向,然后看着它自己跑起来。
AI评测AI,是智能编程的成人礼。