对抗知识焦虑,从看懂这条开始
App 下载
丰田给自动驾驶装了副"记忆眼镜",雨天也能看清路
车道线补全|恶劣天气感知|LG-FA模块|丰田|自动驾驶|人工智能
对抗知识焦虑,从看懂这条开始
App 下载车道线补全|恶劣天气感知|LG-FA模块|丰田|自动驾驶|人工智能
想象一下:你开着自动驾驶车在暴雨夜赶路,摄像头里的车道线被雨水冲得支离破碎,路沿隐没在积水里,连导航都开始犹豫——这正是当下自动驾驶最致命的盲区。此前要么靠成本高到离谱的高清地图硬扛,要么让模型死磕恶劣天气数据,效果都像在给近视眼贴近视贴,治标不治本。但丰田的工程师们换了个思路:既然眼睛看不清,不如给系统装一副能"记路"的眼镜。他们推出的LG-FA模块,不用改现有模型,不用依赖高清地图,就能让自动驾驶在雨雪夜里把缺失的标线补全,感知完成率直接拉满。
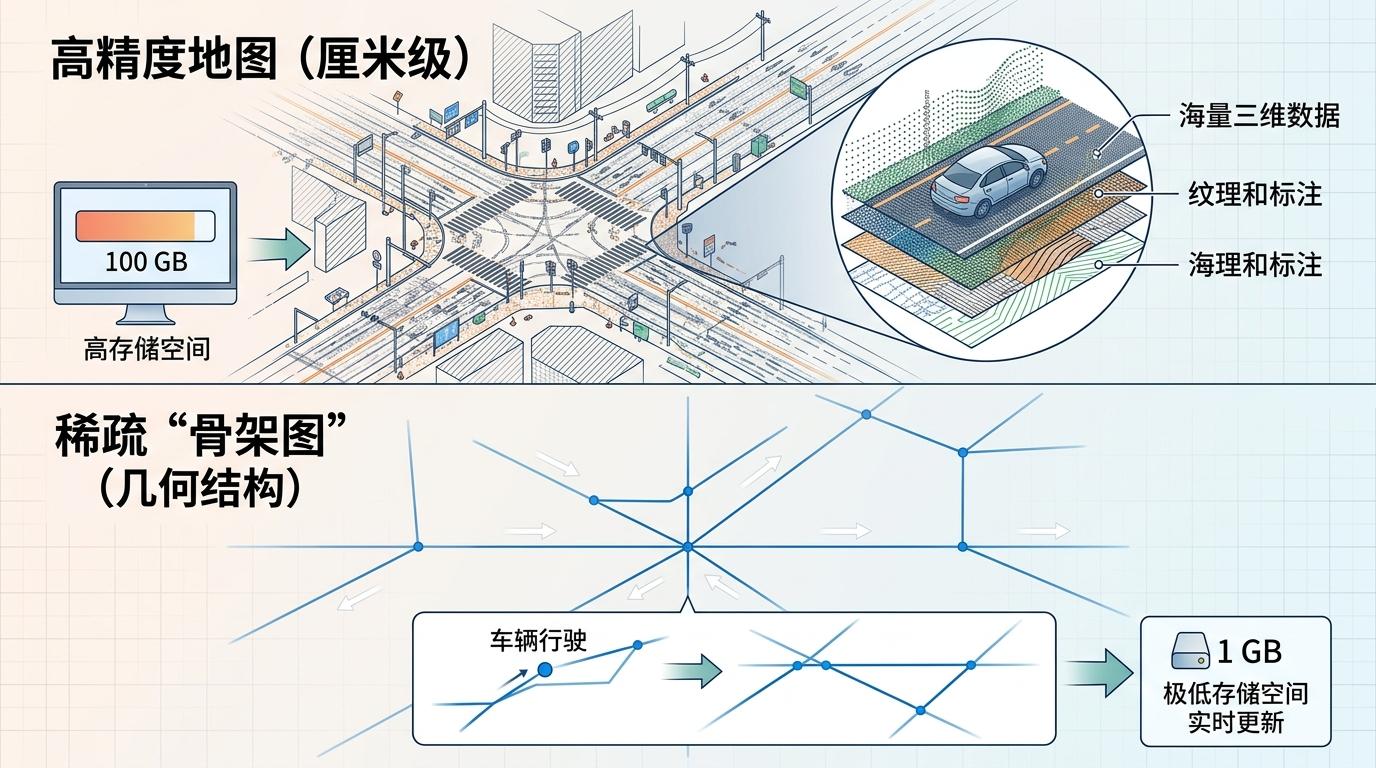
你可以把这个模块的工作逻辑,理解成一个老司机的开车习惯:每次路过一段路,都会默默记下路面的标线位置,下次再走哪怕看不清,也能凭着记忆知道路在哪。LG-FA就是把这个习惯自动化了。 它会在车辆行驶时,把每一帧感知到的车道线、路沿、人行横道,通过GNSS/IMU提供的粗略位置,一点点"贴"到同一个全局坐标系里。就像用碎片拼拼图,它会用一种叫对称最近邻差异的算法,判断新感知到的标线碎片和已经拼好的地图是不是同一段——比如新检测到的车道线,只会和地图里的车道线比对,不会认错成路沿。匹配上就合并成更完整的线段,匹配不上就新增一段,还会自动删掉那些孤立的小碎片,避免干扰。 最终拼出来的不是高清地图那种厘米级的精细画像,而是一张稀疏但准确的"骨架图"——只用关键的几何线条记录道路结构,存储空间和计算成本都只有高清地图的几十分之一。而且这张图是实时更新的,车辆开得越久,地图就越完整。
光有地图还不够,得知道自己在地图的哪个点上——这就是定位的核心。传统的定位算法比如ICP,就像蒙着眼找拼图位置,很容易把不同类别的线条认错,比如把路沿当成车道线对齐,结果越偏越远。 LG-FA给定位加了个"类别约束"的紧箍咒:只能用同类别的线条做匹配。比如要找当前车道线的位置,就只能去地图里找车道线的片段比对,路沿和人行横道再近也不能碰。它还设计了双向损失的判断逻辑:既要让当前帧的标线贴合地图,也要让地图的标线能对应上当前帧,相当于双向验证,把定位误差压到最小。 在nuScenes数据集的测试里,当初始定位误差放大3倍时,传统ICP的平移误差会飙升到1.8米,航向误差超过3度,而LG-FA的平移误差还能稳定在0.72米,航向误差1.59度——相当于在暴雨里,它还能像晴天一样找准自己的位置。
数据最能体现这个模块的价值。在nuScenes数据集的恶劣天气场景测试中,单纯靠单帧感知的标线完成率,人行横道只有30.5%,车道分隔线更是低到20.1%——相当于每5帧里就有4帧看不清完整的车道线。 但加上LG-FA模块后,三类标线的完成率都接近100%,平均提升了70%。更关键的是,它不需要额外的硬件,也不用改动现有感知模型的骨干网络,就像给手机装了个拍照增强APP,点一下就能用,计算量小到在CPU上就能实时运行。 当然它也有局限:如果初始的GNSS/IMU误差太大,或者感知网络完全没检测到任何标线,这张"记忆地图"也会抓瞎;长时间行驶后,地图还可能积累冗余信息,需要定期清理。但这些都是可以通过后续算法优化解决的问题,不影响它作为"低成本补盲方案"的核心价值。
自动驾驶的终极目标,从来不是在晴天的高速路上跑得多顺,而是在暴雨、暴雪、深夜这些极端场景里,能像老司机一样从容应对。LG-FA的思路,本质上是把自动驾驶从"依赖实时视觉",转向了"结合历史记忆"——就像人类开车时,不会只盯着眼前的路,还会凭着经验预判接下来的路况。 这或许是更贴近真实驾驶的方向:不用追求极致的硬件,也不用依赖完美的地图,而是让系统学会"积累经验",用最低的成本补上最致命的短板。好的自动驾驶,要会看路,更要会记路。