对抗知识焦虑,从看懂这条开始
App 下载
AI时代的新搜索引擎,不是给人用的
即时响应|技术栈|事实碎片检索|AI搜索引擎|AI智能体|人工智能
对抗知识焦虑,从看懂这条开始
App 下载即时响应|技术栈|事实碎片检索|AI搜索引擎|AI智能体|人工智能
当你在谷歌输入问题,它返回10个蓝色链接——这是为人类的浏览习惯设计的。但如果提问的是一个AI智能体呢?它不需要链接,要的是精准到段落的事实碎片;它不能等700毫秒,要的是200毫秒内的即时响应;它的查询可能涉及商业机密,容不得半分数据留存。2026年,一家估值22亿美元的公司用三年时间证明:AI需要的搜索引擎,和我们熟悉的完全是两回事。为什么这个判断让它的估值一年翻三倍?答案藏在一套从零建起的技术栈里。
你可以把传统搜索引擎的索引想象成一本巨大的字典——每个关键词对应一串网页地址,查词就像翻目录找页码。但AI要的不是目录,是直接把相关段落递到它面前。 这家公司的解决方案是扔掉字典,用「语义向量」重新编码整个互联网。他们训练了专门的嵌入模型,把每篇网页转化成一串几十维到上百维的数字向量——就像给每个网页拍了张「语义X光片」,内容越相似的网页,向量在空间里的距离越近。当AI提问时,系统不是匹配关键词,而是把问题也转成向量,在向量数据库里「找相似」。 这背后是一套全栈自研的体系:从能抓取动态网页的爬虫,到存储5000亿个向量的数据库,再到144块H200 GPU组成的计算集群。他们甚至放弃了谷歌依赖的倒排索引,用近似最近邻算法实现毫秒级检索——这是套壳谷歌的产品永远做不到的,就像你没法在别人的字典里,按自己的逻辑重新排序所有词条。 最关键的是,这套系统能做到「零数据保留」:查询完成后,所有痕迹直接销毁,没有任何第三方能获取AI的提问内容。这对处理商业机密的企业客户来说,不是加分项,是生命线。
如果说语义搜索是给AI递工具,那「智能体自主搜索」就是让AI学会自己用工具。 举个例子:当你问AI「2026年美国A轮融资的农业科技公司有哪些」,传统搜索会返回一堆新闻链接,但智能体搜索能自己拆解任务:先定位美国农业科技公司的融资新闻,再筛选A轮、2026年的项目,最后整理成结构化列表。它会自动发起多轮子查询,甚至会验证信息的准确性——比如交叉核对公司官网和融资公告。 这套机制的核心是「思考-行动-反思」的循环:系统先分析任务复杂度,决定要不要拆分;执行搜索后,会判断结果是否足够,如果不够就调整关键词再搜;最后把零散的信息汇总成符合要求的答案。在DeepMind的DeepSearchQA测试中,这种方法的准确率比传统搜索高了30%。
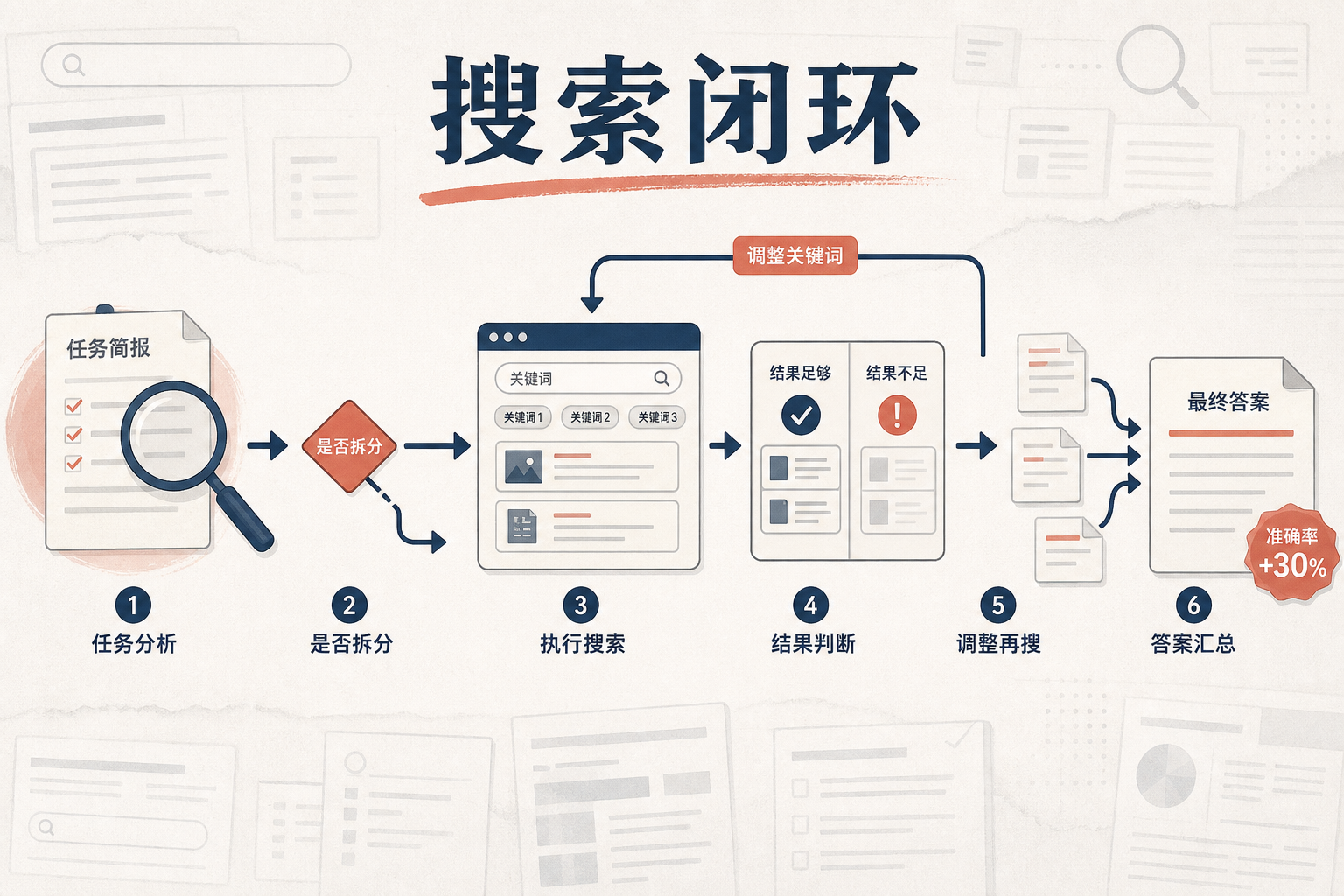
更重要的是,它把搜索从「单次查询」变成了「任务闭环」。企业用它来做市场调研,能省掉人工筛选信息的几天时间;开发者用它来补全代码,能直接从GitHub上找到匹配的解决方案。这不再是简单的信息检索,而是AI完成复杂任务的「信息手脚」。
搜索不只是AI工作时的工具,更是训练AI的「数据底座」。 这家公司做了一个实验:用自己的搜索结果训练强化学习智能体,和用谷歌搜索结果训练相比,token消耗减少了69%,搜索调用次数少了62%,交互轮数少了58%。原因很简单:谷歌返回的是给人看的网页,有广告、有导航栏,这些对AI来说都是无用信息;而他们的搜索结果直接返回关键段落,AI能更快学到有用的知识。 这就像给学生上课,一个老师给的是满是水印和广告的影印件,另一个给的是划好重点的讲义,后者的学习效率自然更高。对企业来说,这意味着训练AI的成本能砍掉近七成——在大模型训练动辄上千万美元的今天,这是真金白银的竞争力。

但这套系统也不是没有挑战。要维持5000亿个URL的实时索引,每天要处理数亿次更新;要支持每秒数十万次查询,计算集群的扩容速度永远赶不上需求增长。更棘手的是数据隐私:一旦处理医疗、金融等敏感数据,任何一点漏洞都可能引发合规风险。
当数万亿AI智能体在未来十年陆续上线,它们的搜索需求会是今天谷歌的一千倍。那时我们会发现,人类的搜索习惯只是互联网历史上的一个小插曲——真正支撑AI时代的,是为机器设计的信息基础设施。 这家公司的崛起不是偶然,它只是提前摸到了时代的脉搏:AI需要的不是更好的人类搜索引擎,而是一套全新的信息规则。 给机器的搜索,才是未来的搜索。