对抗知识焦虑,从看懂这条开始
App 下载
AI生图不再靠猜,自回归架构重构可控性
确定性推理|空间逻辑|图像生成|自回归Transformer|多模态视觉|人工智能
对抗知识焦虑,从看懂这条开始
App 下载确定性推理|空间逻辑|图像生成|自回归Transformer|多模态视觉|人工智能
当你输入“凌晨两点的房间,雨打玻璃,暖灯旁的孤独”,AI不再随机拼凑光影,而是先在“脑海”里搭建空间逻辑:暖灯该在沙发左侧,咖啡杯的反光要对应窗外的雨,孤独感靠暖光与冷窗的对比实现——最后才生成画面。这不是某款大厂新工具的宣传,而是自回归Transformer架构正在改写AI图像生成的底层逻辑:从“概率性猜图”变成“确定性推理+生成”。
你可以把传统扩散模型想象成“盲人摸象式画画”:从一团噪声开始,一步步擦掉噪声还原图像,全程不知道最终画面的完整逻辑,全靠数据训练出的概率直觉。而自回归Transformer更像“写小说”:先把文字指令和图像都拆解成统一的“语言单位”(token),像人类读剧本分镜一样,先推理出画面的空间结构、光影关系、情绪氛围,再按序列生成每一个细节。
打个更具体的比方:扩散模型是给你一堆颜料,让你随机泼洒后慢慢调整成画;自回归模型则是先给你画好分镜脚本,再按脚本一笔一笔完成创作。它的核心是“先想清楚,再动手”——先通过Transformer的自注意力机制,把文字里的“凌晨两点”“孤独感”“暖灯冷雨”这些信息编织成完整的视觉逻辑,再生成像素。
这种架构的直接效果是,AI终于能听懂复杂的空间指令:“把左边沙发上的猫移到右边窗台,保持暖灯的光影方向”,不用反复调整提示词碰运气;给它一张分镜草图,它能自动补全符合逻辑的场景细节,而不是把草图当贴图拼进新画面。

传统AI生图的最大痛点是“可控性差”——你说“穿红裙子的女孩站在海边”,它可能给你生成红裙子飘在海里,女孩站在沙滩上。问题出在图文是两个独立的模型:文本模型先理解指令,再把语义传给图像模型,中间难免信息损耗。

自回归Transformer的解决办法是“统一序列建模”:把文字和图像都转换成相同格式的token,塞进同一个Transformer模型里处理。就像把中文和英文翻译成同一种世界语,让AI能直接在文字和图像的“世界语”里对话,不用经过两次翻译。
举个技术细节:它会用专门的编码器把图像拆成几百个视觉token,每个token对应图像的一块区域和语义;文字也拆成文字token,然后把两种token混在一起,让Transformer的自注意力机制计算它们之间的关联——比如“红裙子”的文字token会和图像中对应区域的视觉token建立强关联,确保裙子的颜色和位置都符合指令。
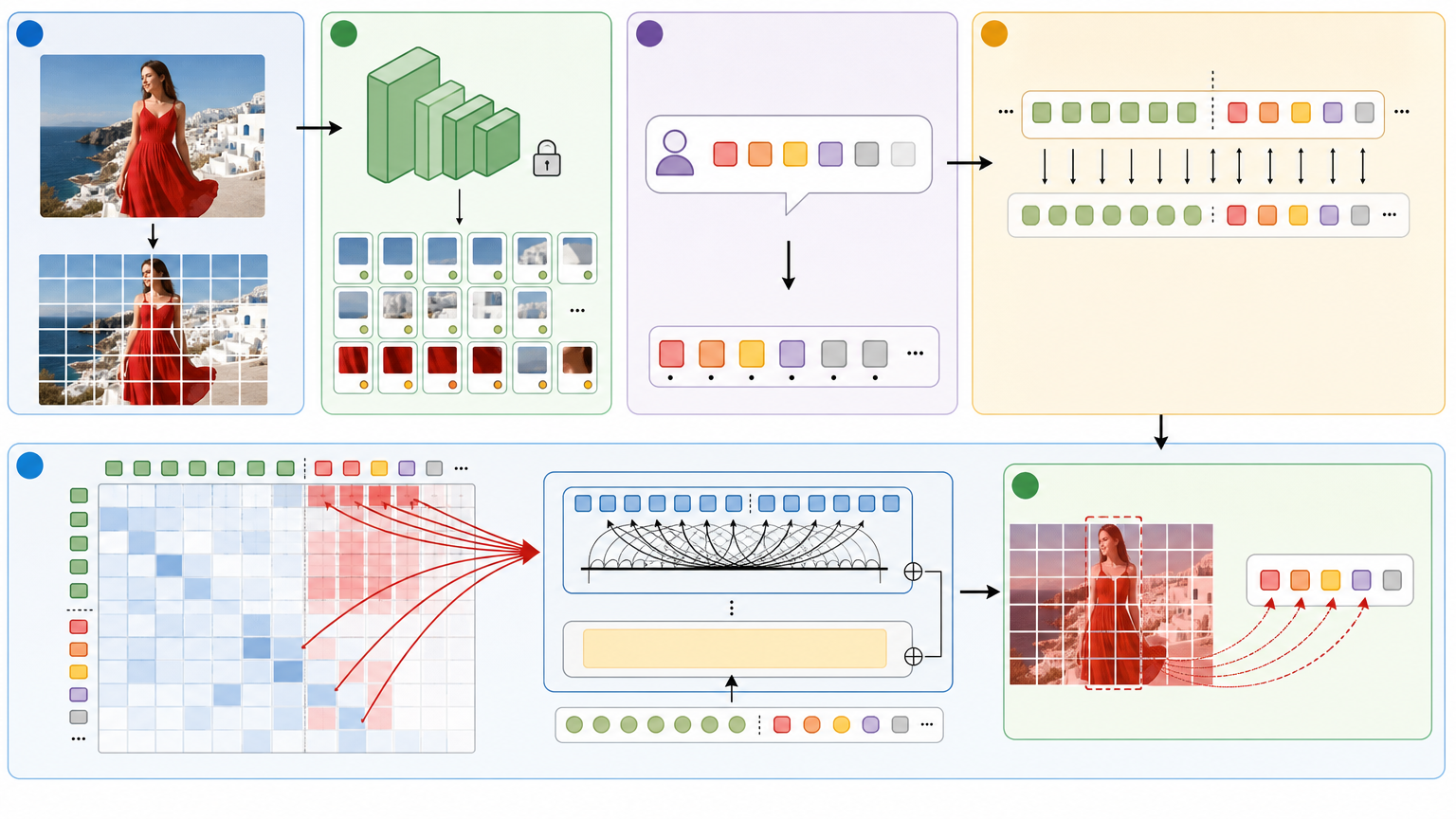
这种语义融合带来的改变是颠覆性的:你可以同时喂给AI产品照、品牌logo、场景参考图,它会理解这些素材的语义关系,把logo放在产品的正确位置,场景光影匹配产品的质感,而不是简单地把三张图拼在一起。某团队用这种技术把原本需要一年、耗资1500万美元的广告制作,压缩到40小时、2万美元完成,核心就是AI能精准执行复杂的品牌视觉约束。
当然,自回归架构不是AI生图的终极答案,它还面临着三道必须跨过的坎。
第一道是速度坎。自回归模型需要按序列生成每个token,就像打字要一个字一个字打,生成高分辨率图像时速度比扩散模型慢——目前最快的混合架构能把速度提升9倍,但离实时生成还有距离。
第二道是细节坎。视觉token化会不可避免地损失部分细节,比如手指的细微动作、文字的精确排版,目前还需要依赖扩散模型来补全细节,形成“自回归搭骨架,扩散模型填血肉”的混合方案。
第三道是版权坎。自回归模型的训练需要海量图文数据,而这些数据的版权归属仍存争议。目前已有超过70起针对AI图像生成公司的版权诉讼,一旦法院判定训练数据需获得授权,整个行业的成本结构都会改变。
更现实的问题是,自回归模型的“强可控性”会不会反而限制创意?当AI只会严格执行指令,会不会失去随机生成带来的意外灵感?这也是不少创作者的担忧。
当AI从“随机生成”转向“推理生成”,它的角色也从“创意灵感工具”变成了“精准执行助手”。这不是取代人类创意,而是把创作者从反复调整提示词的机械劳动中解放出来,把精力放在真正的创意构思上。
未来的AI生图,可能不会是某一种架构独霸天下,而是自回归、扩散、GAN等多种技术的融合——就像人类创作时,既需要严谨的分镜逻辑,也需要偶尔的即兴发挥。
AI生图的未来,是让创意摆脱技术的束缚。