对抗知识焦虑,从看懂这条开始
App 下载
戴在脸上的AI,不止是能看能说
视觉特征提取|手势识别|实时翻译|近眼显示设备|多模态视觉|人工智能
对抗知识焦虑,从看懂这条开始
App 下载视觉特征提取|手势识别|实时翻译|近眼显示设备|多模态视觉|人工智能
你试过在拥挤的地铁里,不用掏出手机,只抬抬下巴就能问清下一站出口的换乘方向吗?或者在跨国会议上,眼前的PPT文字实时转成母语,连发言人的手势都能被AI解读成补充说明?这不是科幻片里的场景——一款搭载多模态AI的近眼显示设备,已经把这些变成了日常。它的核心,是让设备像人一样,同时用眼睛和耳朵接收信息,再用自然的方式给出反馈。这背后的技术,比单纯的语音助手或图像识别要复杂得多。
多模态AI的关键,是把视觉、语音甚至触觉的信息拧成一股绳。想象一下,当你指着路边的陌生植物提问,设备的摄像头先捕捉叶片的形状、纹理,麦克风录下你的问题,AI会先把图像转换成机器能读懂的视觉特征,再把语音转换成文本指令,最后在后台把两者比对、关联——这就像你先看一眼东西,再在脑子里搜索相关知识,只不过AI把这个过程压缩到了几百毫秒里。为了让这个过程在小小的眼镜里实现,工程师们还得把大模型“减肥”,用模型剪枝、量化的技术,把原本需要云端算力的算法,塞进眼镜里的低功耗芯片。
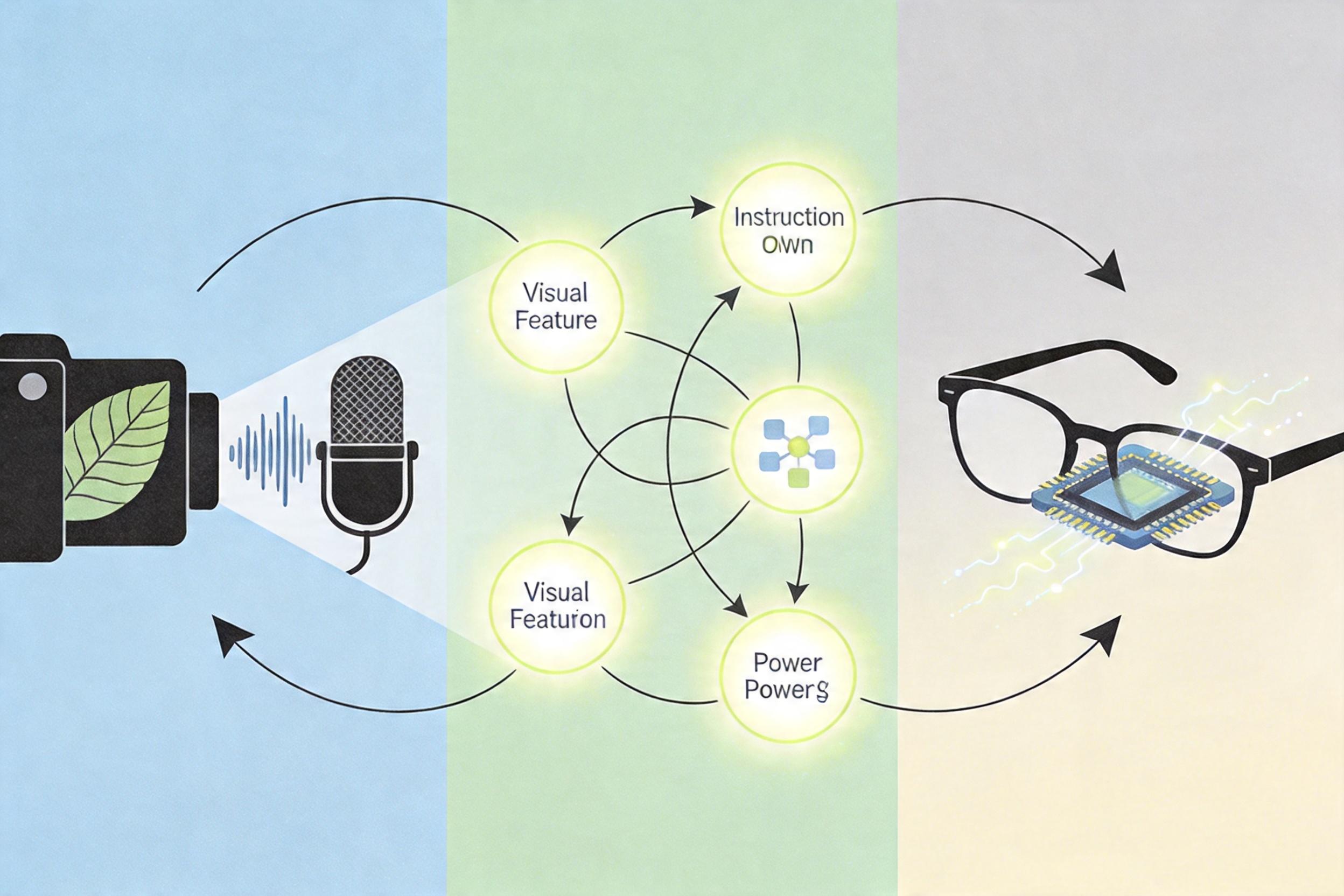
但这还不是最核心的突破。过去的智能设备,大多是“你问它答”的被动模式,而多模态近眼设备正在变成“主动感知”的伙伴。比如它能通过你的语速、眼神停留的时间,判断你是不是在赶时间,给出更简洁的导航提示;在会议上,它能识别你皱眉的动作,自动标记你可能没听懂的段落,会后生成重点标注的纪要。这种“读心术”,其实是AI对多模态数据的交叉分析——语音的停顿、视线的轨迹、甚至环境的噪音,都成了它判断你需求的线索。
当然,现在的技术还没到完美的地步。比如在强光下,近眼显示的亮度还得再提升,才能让文字清晰可见;多模态AI的隐私问题也悬而未决——摄像头和麦克风时刻开启,怎么保证你的个人信息不被泄露?工程师们正在用边缘计算解决这个问题:让大部分AI运算在设备本地完成,不用把数据传到云端,就像你的思考只在脑子里进行,不会说给别人听。
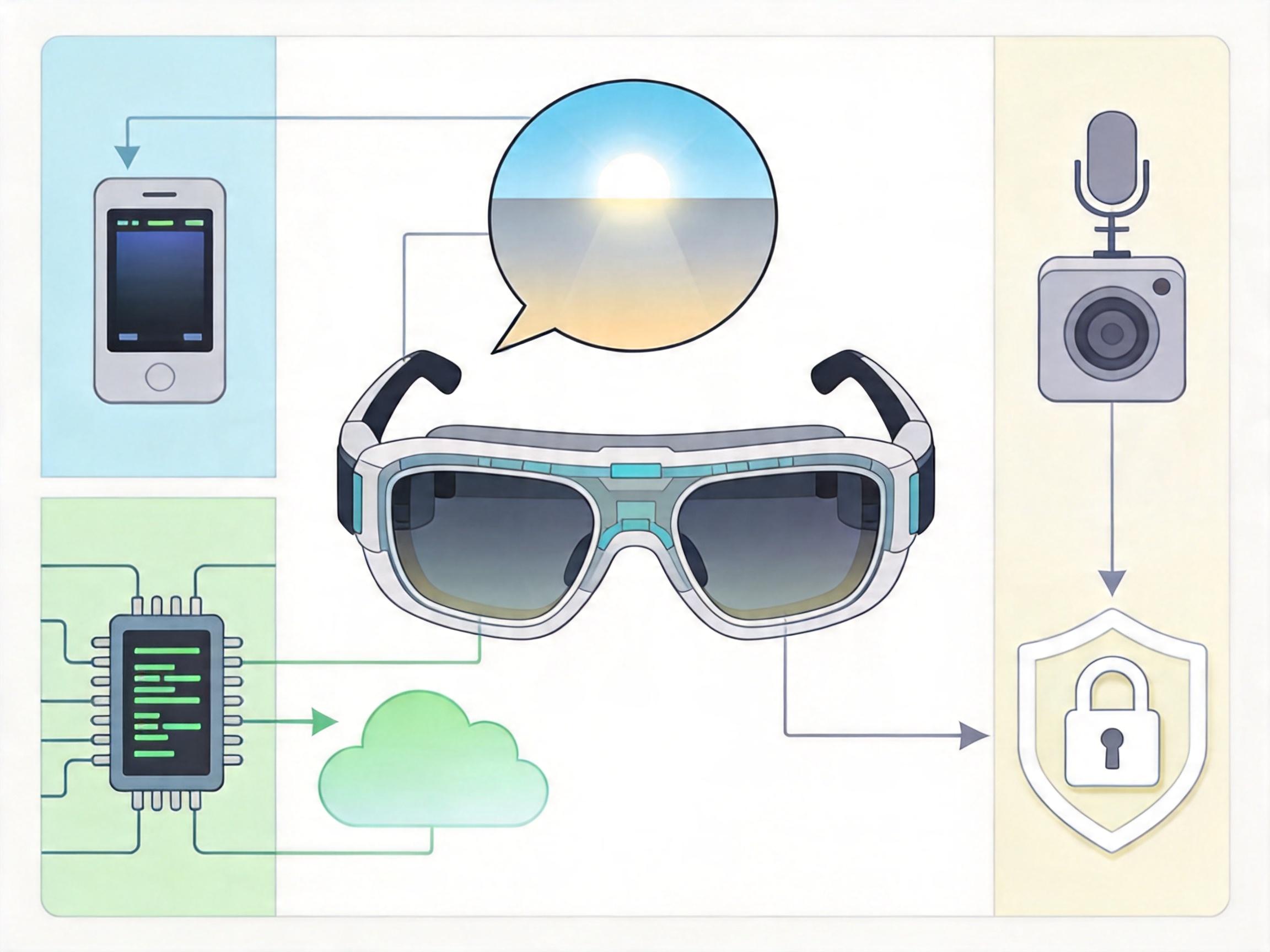
未来的近眼显示设备,会更像一个“隐形的助手”。它可能不会有明显的屏幕,而是通过投影把信息投在你视野的角落;它甚至能通过皮肤的电信号,感知你的情绪,在你焦虑的时候,悄悄给出一段舒缓的音乐建议。当AI真正学会了“看”和“听”,人和机器的交互,终于能从“操作设备”,变成“对话伙伴”。
技术的终极目标,从来不是让设备更强大,而是让它更懂你。当戴在脸上的AI能跟上你的眼神、听懂你的语气,它就不再是一个工具,而是你延伸出去的另一个感官。