对抗知识焦虑,从看懂这条开始
App 下载
云厂商自研芯片突围,英伟达不再独霸算力
算力市场|自研芯片|AI初创公司|谷歌TPU|英伟达H100|半导体技术|AI算力|前沿科技|人工智能
对抗知识焦虑,从看懂这条开始
App 下载算力市场|自研芯片|AI初创公司|谷歌TPU|英伟达H100|半导体技术|AI算力|前沿科技|人工智能
当一家AI初创公司的CEO为了抢到100颗英伟达H100,在供应商办公室蹲守三天三夜时,谷歌的数据中心里,第八代TPU正以比H100低44%的成本,运行着苹果智能助手的核心模型。这不是科幻小说里的场景,而是2026年AI算力市场的真实切片:一边是英伟达GPU的一卡难求,一边是云厂商自研芯片正在从后台的“备胎”,悄悄变成推理场景的“主力”。这场从“花钱买算力”到“自己造算力”的转向,到底藏着怎样的博弈?
要理解云厂商的突围,得先看清英伟达的壁垒到底有多厚。2006年推出的CUDA(统一计算架构),是这条护城河的核心——你可以把它想象成一个超级工具箱,里面装着数千万开发者用了20年攒下的扳手、螺丝刀和说明书,从游戏渲染到AI训练,几乎所有GPU能做的事,都能在这个工具箱里找到现成工具。全球超过90%的AI训练任务跑在CUDA上,开发者一旦熟悉这套工具,切换到其他平台的成本,不亚于让一个老厨师换用一套全新的厨具。

硬件上的优势同样难以撼动。英伟达最新的Blackwell架构GPU,搭配NVLink高速互联技术,单颗GPU的互连带宽能达到3.6TB/s,是传统PCIe总线的14倍。就像给每台电脑都装了直达高速路,72颗GPU组成的集群能实现260TB/s的总带宽,足以支撑数万亿参数大模型的实时训练。这种“硬件+软件”的垂直整合,让英伟达在过去10年里,把数据中心GPU的市场份额稳定在90%以上。
云厂商的突围,没有直接硬碰硬挑战训练市场,而是从推理场景撕开了口子。AI推理就像餐厅的出餐环节——不需要研发新菜品,只需要把做好的菜快速、高效地端给客人。这个场景对通用性要求不高,却极度看重成本和效率,而这正是ASIC(专用集成电路)的强项。
亚马逊的Trainium3芯片就是最好的例子:它针对AI推理专门设计,性能是前代的4倍,能把推理成本降低50%。AWS公开的数据显示,Trainium和Inferentia系列芯片的年收入已经超过200亿美元,客户包括Anthropic、Snap等巨头。谷歌的TPV7芯片,在推理场景下的总拥有成本比英伟达GB200低44%,苹果用8192颗TPU训练了自己的智能助手,Meta也宣布要在2027年直接采购TPU。
这些自研芯片不需要兼容所有AI模型,只需要把云厂商自己的核心服务——比如谷歌的搜索、亚马逊的推荐、阿里的电商——优化到极致。就像餐厅自己定制的传菜机器人,虽然不能炒菜,但端菜的速度比普通服务员快3倍,成本只有1/3。
对于国内云厂商来说,自研芯片不是选择题,而是生存题。在出口管制的压力下,英伟达对中国市场的芯片供应受限,国产芯片的窗口期突然打开。2025年,国产AI加速卡的出货量首次突破国内市场的40%,华为昇腾、阿里平头哥、百度昆仑芯成为第一梯队。
华为的昇腾950PR芯片,性能已经超过英伟达的中国特供版H20,还专门优化了对CUDA的兼容性,让习惯英伟达工具的开发者能快速迁移。阿里的真武810E芯片,已经在阿里云部署了多个万卡集群,服务国家电网、中科院等400多家客户,60%的芯片对外销售,年营收达到百亿级别。百度的昆仑芯P800,单机8卡就能跑671B参数的大模型,在中国移动的集采中拿下了70%的份额。
不过,国产芯片的挑战依然明显:在训练场景,CUDA生态的壁垒依然难以逾越;高端芯片的制造工艺还依赖海外工厂;软件工具链的成熟度,和英伟达还有至少5年的差距。但出口管制带来的窗口期,给了国产芯片厂商宝贵的时间——就像被按下加速键的追赶者,虽然还没跑到终点,但距离已经在一步步缩小。
当AWS宣布把自研的Trainium4芯片和英伟达的NVLink技术混合部署时,这场算力战争的终局已经逐渐清晰:英伟达不会被取代,但也不再能独霸市场。未来的AI算力体系,会是一个“双核异构”的格局——英伟达GPU主导训练市场,云厂商自研芯片成为推理场景的主力,两者在数据中心里共存,各自发挥优势。
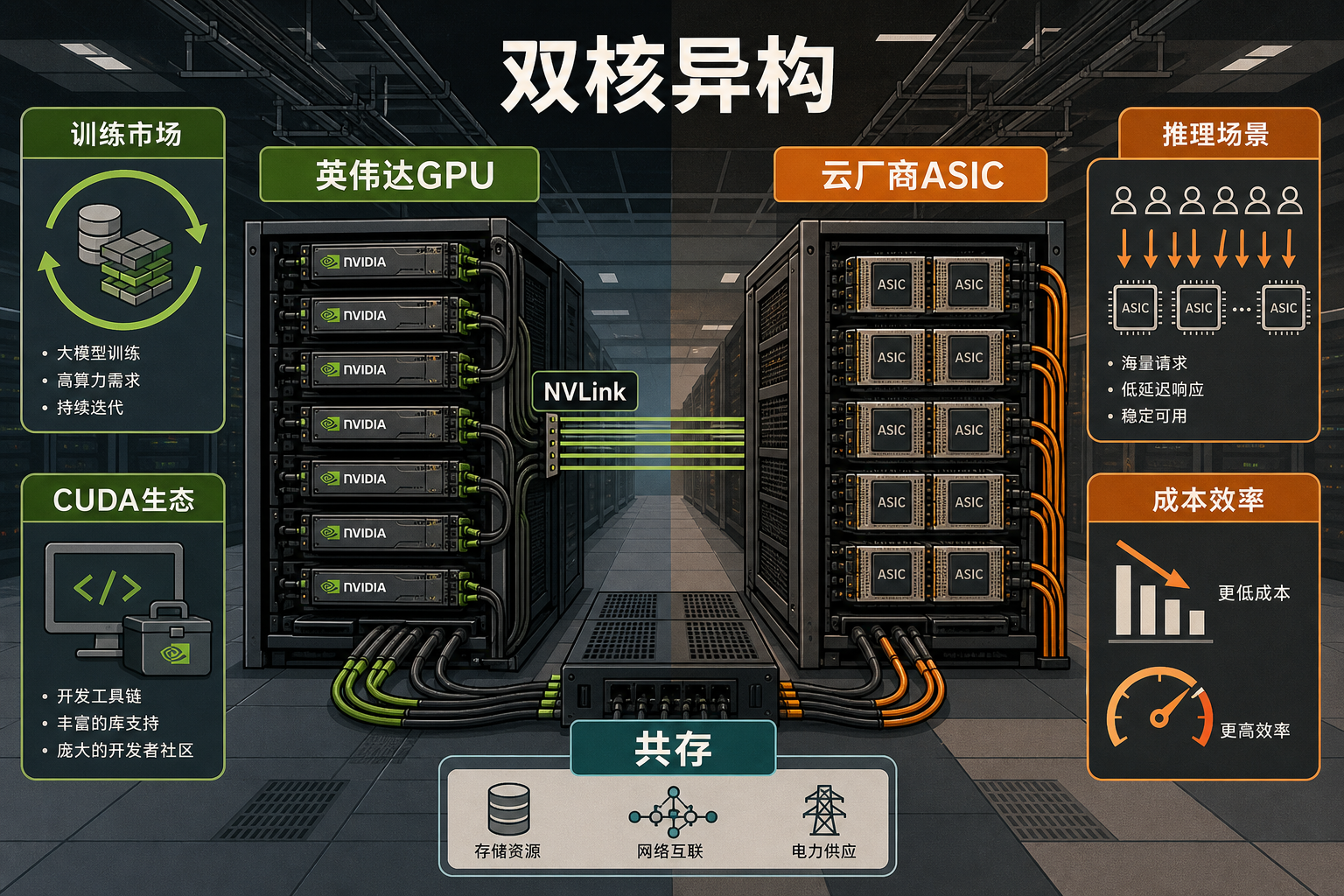
算力的本质,从来不是谁的芯片跑得最快,而是谁能以最低的成本,把算力送到需要的地方。从“买算力”到“造算力”,云厂商的突围,其实是一场对“算力自主权”的争夺。算力的未来,是定制化的天下。