对抗知识焦虑,从看懂这条开始
App 下载
同一AI模型,换套系统性能差53个百分点
AI编程性能|CORE-Bench Hard|Harness系统|Claude Opus 4.5|大语言模型|人工智能
对抗知识焦虑,从看懂这条开始
App 下载AI编程性能|CORE-Bench Hard|Harness系统|Claude Opus 4.5|大语言模型|人工智能
当你以为AI编程的胜负早已由模型参数决定时,一组数据正在推翻这个常识:同样是Claude Opus 4.5模型,放进Anthropic的Harness系统,在CORE-Bench Hard测试中能拿到95%的高分;换成一套朴素的开源配置,成绩直接跌到42%。53个百分点的差距,相当于顶级选手和入门新手的鸿沟——而这一切,和模型本身的智能水平毫无关系。这就是2026年AI编程领域最隐秘的胜负手:Harness,一套包裹在模型之外的「智能脚手架」。
你可以把大语言模型想象成一个精通所有编程语言的天才,但它只会说自己的「模型语言」——一堆抽象的逻辑和代码片段,没法直接对接真实的开发环境。而Harness,就是把天才的语言翻译成开发者能用的「工程语言」的翻译官。
它不是一个简单的工具,而是一套完整的系统:负责帮模型记住整个代码库的上下文,管理它调用终端、读写文件、运行测试的权限,在它出错时把报错信息转化成能理解的反馈,甚至把复杂任务拆成一个个小步骤,让模型一步步完成。比如你让AI「修复这个bug」,模型可能只会生成一段代码,但Harness会指挥它:先定位bug位置,修改代码,运行测试,读报错信息,再回来修正——直到问题真正解决。
Anthropic的工程师把这套逻辑总结成一个公式:Agent = Model + Harness。模型提供智能,Harness让智能落地。
2026年的AI编程赛道,已经从「拼模型参数」转向「拼Harness设计」。OpenAI的内部实验显示,同一模型在不同Harness上的性能差异可达6倍;LangChain团队仅仅优化了Harness架构,就把自家代理在Terminal Bench 2.0的排名从第30位拉到了第5位。
Harness的威力,本质上是解决了模型的天生缺陷:它的上下文窗口有限,没法记住整个代码库;它容易「过度自信」,没写完就说任务完成;它不会自己调用工具,只能被动生成代码。而Harness通过五大核心模块补上了这些短板:用状态持久化解决「失忆」问题,用工具调用扩展模型能力边界,用上下文压缩突破窗口限制,用多代理协作拆分复杂任务,用安全隔离防止AI乱改代码。
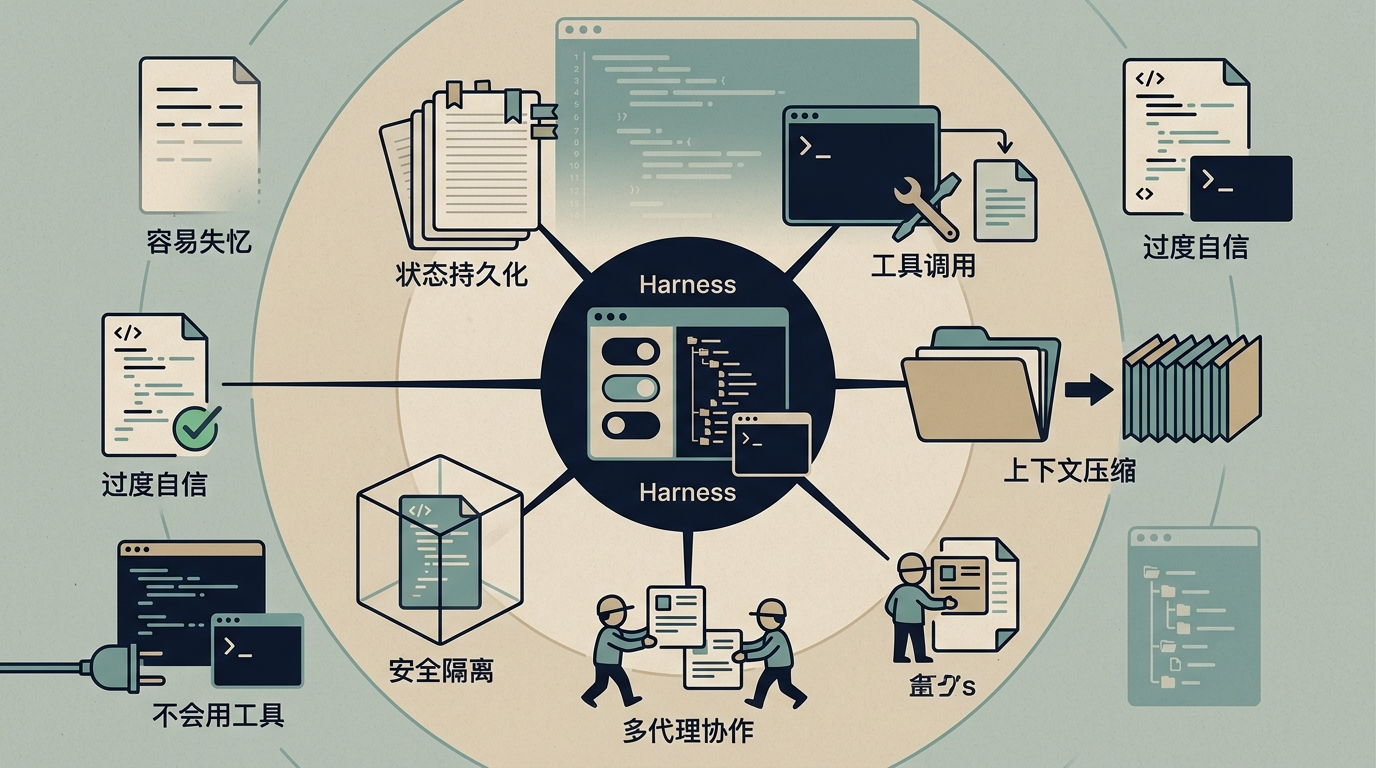
更关键的是,Harness和模型不是单向配合,而是在互相进化。每次模型升级,Harness就会去掉一些冗余的辅助逻辑;每次Harness发现新的问题,这些数据又会被用来训练模型,让模型下次能自己解决。Anthropic的Claude Code就是这样迭代的:从只能运行几分钟的代码助手,变成能连续工作几小时的工程代理,背后是Harness和模型的17次同步升级。
当Claude Code凭借Harness成为行业标杆时,中国开发者却被挡在了门外——Anthropic禁止中国大陆用户访问,甚至限制中国资本控股的企业使用。这道壁垒,反而催生了国内团队的破局机会:DeepSeek在2026年5月启动了Harness团队招聘,目标是用自家的R1模型,搭配自主研发的Harness系统,打造对标Claude Code的代码代理。
DeepSeek的优势在于,它的R1模型本身就是为高效推理设计的混合专家模型,训练成本只有GPT-4的十分之一。但要追上Claude Code,关键不在模型,而在Harness的工程能力:如何让模型稳定处理真实代码库的复杂任务,如何构建从用户反馈到模型训练的闭环,如何设计安全可靠的沙箱环境。这些都是Claude Code花了一年时间才打磨出来的壁垒,也是DeepSeek需要跨越的门槛。
有意思的是,开源社区已经提前行动了:有人基于DeepSeek模型开发了「DeepSeek-TUI」,实现了类似Claude Code的终端功能,但缺乏官方支持的迭代和优化。DeepSeek的官方Harness团队,正是要把这种民间的自发创新,变成能和国际巨头抗衡的产品。
当我们还在争论哪个模型更强大时,AI编程的战场已经悄悄转移了。就像同样的发动机,装在普通轿车上和F1赛车上,性能天差地别——Harness就是那个把模型变成「赛车」的工程师。

未来十年,AI编程的竞争,不再是模型参数的竞赛,而是Harness工程能力的较量。谁能把模型的智能高效地转化为生产力,谁能构建起模型与Harness的协同进化闭环,谁就能掌握下一代软件开发的主动权。
模型决定上限,Harness决定下限。 这句话,正在成为AI编程领域的新共识。