对抗知识焦虑,从看懂这条开始
App 下载
机器人学会预判未来,从被动执行到主动决策
AGV小车|服务机器人|工业机器人|世界模型|实时预测系统|AI智能体|人工智能
对抗知识焦虑,从看懂这条开始
App 下载AGV小车|服务机器人|工业机器人|世界模型|实时预测系统|AI智能体|人工智能
想象一下:工厂里的机器人提前30秒预判到零件装配偏移,自动调整了抓手角度;家里的服务机器人在你碰倒水杯的瞬间,已经移动到旁边准备接住;物流仓库的AGV小车在货架倒塌前,就带着货物绕到了安全区域。这不是科幻电影的镜头,而是正在发生的技术突破——机器人正在从“看见就做”的执行者,变成“预见再做”的决策者。这背后的核心,是一套能让机器人“看懂”物理世界规律、提前推演未来变化的实时预测系统。
传统机器人的逻辑很简单:传感器看到什么,就按预设程序做出什么反应。但在真实世界里,杯子落地需要时间,零件偏移是渐变的,货架倒塌有前兆——这些动态变化的“时间差”,就是传统机器人的死穴。

现在的解决方案,是给机器人装一个“世界模型”——你可以把它理解成机器人脑子里的物理课本+沙盘模拟器。它不是简单存储“杯子是玻璃做的”这种静态知识,而是通过融合视觉、力觉、触觉等多模态数据,学习物理世界的因果规律:比如杯子倾斜到30度会掉,零件受力不均会偏移,货架螺丝松动会摇晃。
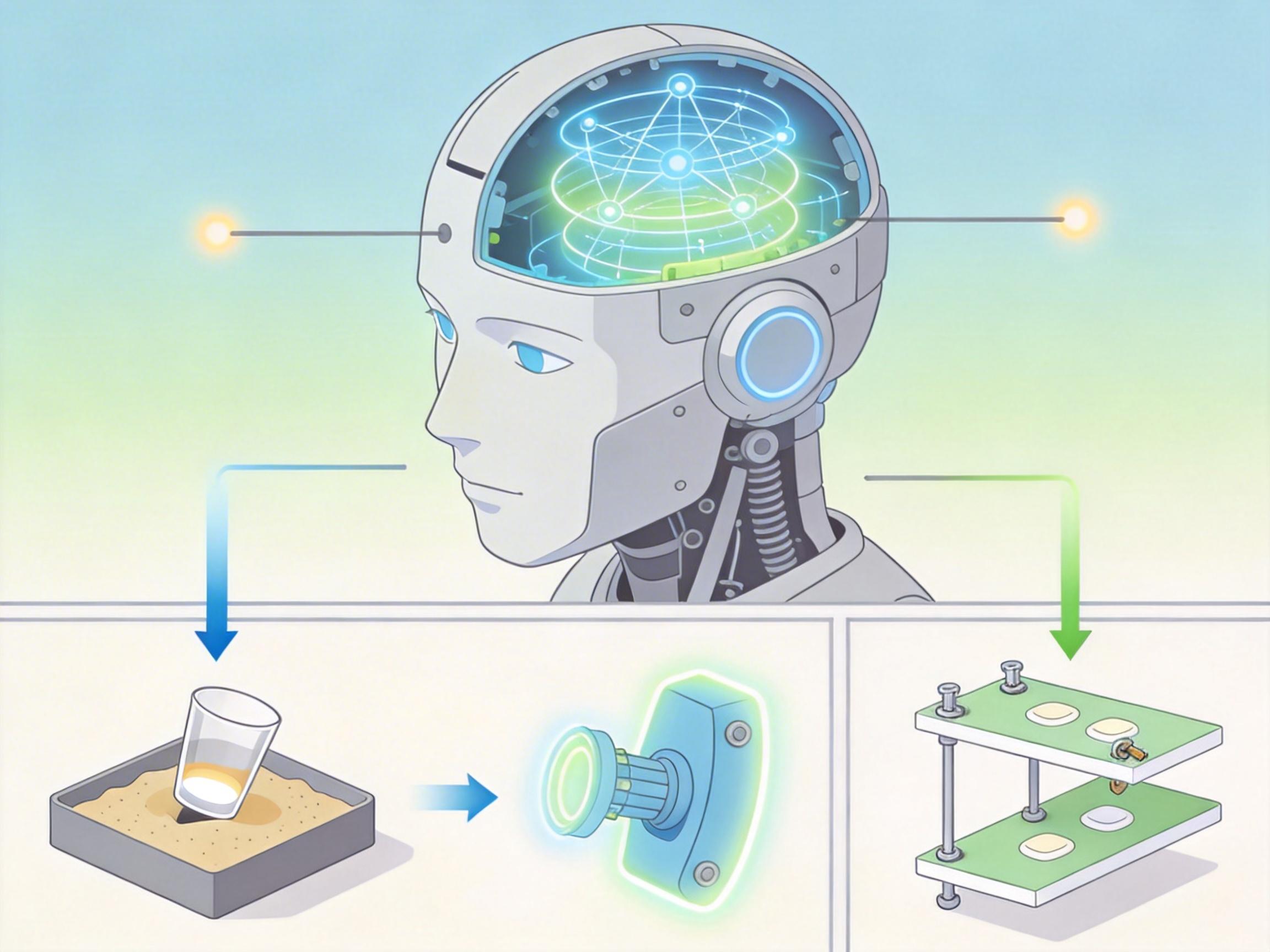
有了这个模型,机器人就能在毫秒级时间里,像做推演题一样模拟出未来10秒甚至1分钟的环境变化:如果我现在伸手,能不能接住杯子?如果我调整这个参数,零件会不会卡壳?然后根据推演结果,提前规划出最优动作——这就是从被动反应到主动预判的关键。
但让机器人学会预判,绝不是给模型输入物理公式那么简单。目前的技术攻关,主要卡在三个核心问题上:
第一个是“数据不够用”。机器人要学会预判,得先见过足够多的“杯子掉落”“零件偏移”场景,但真实世界里采集这些数据成本极高——总不能故意摔一万个杯子来训练。现在的解法是用数字孪生和生成式AI:在虚拟仿真环境里生成百万种不同角度、不同材质的杯子掉落场景,让机器人先在“虚拟世界”里练会预判,再放到真实环境里微调。
第二个是“反应不够快”。预判的核心是“实时”,如果机器人推演未来用了1秒,杯子早已经摔碎了。这就需要算法和硬件的协同优化:一边用轻量化的神经网络压缩模型计算量,一边用边缘计算芯片把算力直接装在机器人身上,不用再把数据传到云端处理——现在最快的系统,已经能在100毫秒内完成一次环境推演。
第三个是“泛化不够强”。在工厂里学会预判零件偏移的机器人,到了家里可能还是接不住杯子,因为不同场景的物理规律虽然相通,但细节千差万别。目前的突破方向是跨模态迁移学习:让机器人从人类的第一视角视频里学习物理常识——比如人是怎么接东西、怎么避免碰撞的,再把这些常识迁移到不同的机器人硬件上。
现在的技术已经能让机器人在特定场景里实现预判,但要走进工厂、家庭的日常,还要解决三个现实问题:
首先是成本。一套能支持实时预判的边缘计算芯片和模型,成本是传统机器人的3-5倍,这对中小企业来说门槛太高。未来的方向是硬件模块化和模型开源,把核心预判功能做成“通用插件”,让不同厂家的机器人都能低成本接入。
其次是安全。如果机器人预判错了怎么办?比如本来想接杯子,结果把桌子碰倒了。这就需要给预判系统加一层“安全闸”:在执行动作前,先验证推演结果的可靠性,一旦发现预判的不确定性超过阈值,就立刻切换回传统的被动反应模式。
最后是信任。你敢让一个能自己“做决定”的机器人在你家里活动吗?这不仅是技术问题,也是心理问题。未来的机器人需要像人一样“解释”自己的决策:它会用语音告诉你“我预判到杯子要掉,所以过来接住”,而不是默默地突然移动——透明的决策逻辑,才能建立人和机器人的信任。
其实人类的“预判能力”也不是天生的,是在成长中见过无数次杯子掉落、门被关上,才慢慢形成的“直觉”。现在机器人正在走的,就是这条从“学习规律”到“形成直觉”的路。
当机器人能像人一样“预见未来”,它就不再是一个冰冷的工具,而是一个能和我们协同工作的伙伴:工厂里它会提醒你“这个零件可能有问题”,家里它会帮你“提前把快递拿到门口”,甚至在紧急情况下,它会“先一步帮你避开危险”。
预判不是为了替代人,而是让机器人更懂人。 这或许才是机器人智能进化的最终方向——不是比人更聪明,而是比人更懂如何和人一起生活、工作。