对抗知识焦虑,从看懂这条开始
App 下载
AI超分终于不瞎了:能认出每一个物体细节
物体细节识别|图像超分辨率|同济大学|InstanceRSR|多模态视觉|人工智能
对抗知识焦虑,从看懂这条开始
App 下载物体细节识别|图像超分辨率|同济大学|InstanceRSR|多模态视觉|人工智能
你有没有过这种经历:翻出十年前的家庭合影,用AI放大修复后,爸妈的脸清晰了,可妈妈毛衣上的麻花针脚糊成了一片,背景里的老槐树叶子像打了马赛克——整体看着高清,细节却经不起盯。这不是AI偷懒,是过去的超分技术天生“脸盲”:它只会盯着整张图的全局清晰度,却分不清画面里的每一个独立物体。直到同济大学的团队掏出了InstanceRSR——这个能“认出”每个物体的AI,终于解决了真实世界超分“全局清楚、局部模糊”的老难题。
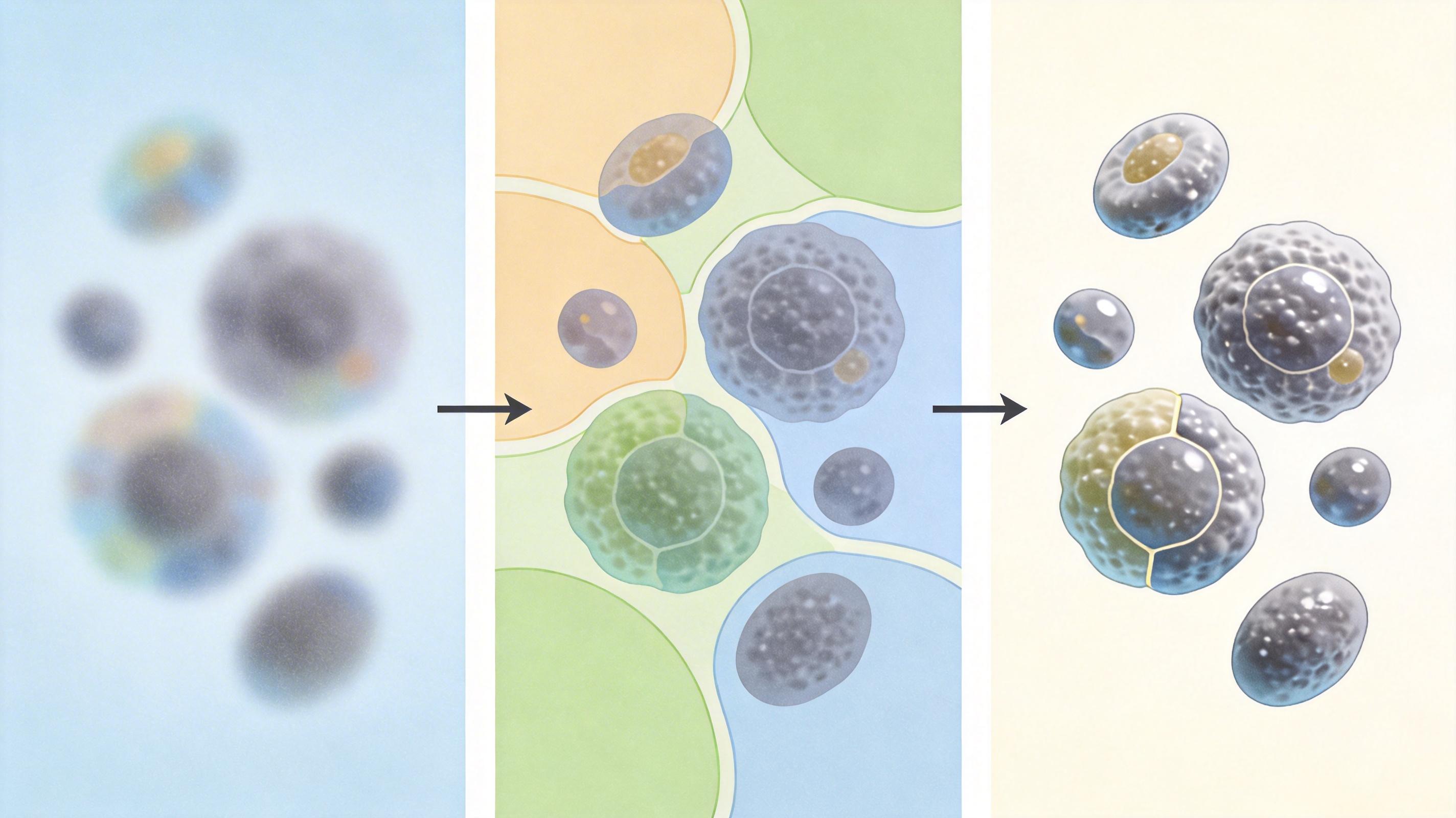
真实世界的低分辨率照片,从来不是“高清图缩小”这么简单——它可能混着手机传感器的噪声、网络压缩的伪影、手抖造成的运动模糊,是一堆复杂退化的混合体。过去的超分模型,比如基于扩散模型的StableSR、DiffBIR,都把“全局一致性”当第一目标:它们会盯着低分辨率图的整体布局、颜色,确保放大后的图和原图“看起来像”。
但问题就出在这儿。这些模型用的去噪损失函数,更擅长抓整体的边缘、明暗,却对每个物体的精细纹理、边界没什么约束力。就像一群人挤在合影里,模型分不清谁是谁,把毛衣的针脚和背景的树叶当成了同类信息,糊在了一起。有个直观的对比:把StableSR和InstanceRSR的中间层特征可视化,前者的特征点像乱炖的豆子,不同物体的特征混在一起;后者的特征点却像分好类的货架,猫归猫,植物归植物,泾渭分明。
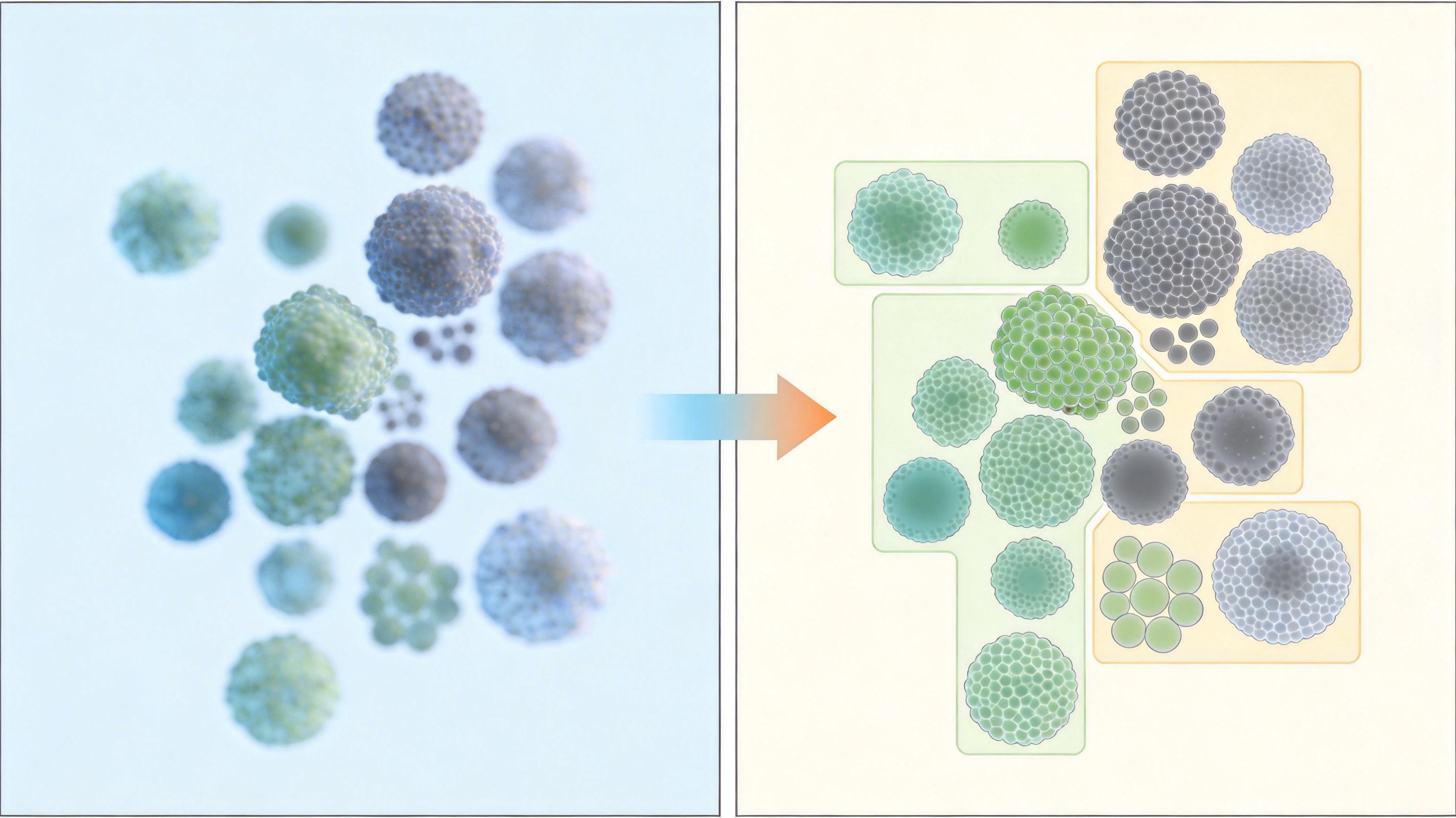
InstanceRSR的核心思路,就是给AI补上“认物体”的能力。它没在复杂的退化模型上死磕,而是直接把“语义分割图”和低分辨率图一起喂给模型——简单说,就是不仅给AI看模糊的合影,还告诉它:“这块是人脸,这块是毛衣,这块是槐树叶子。”
这个分割图不用人工标注,直接用Meta的SAM模型自动生成——这个能给任何图像分清楚物体边界的模型,相当于给AI提供了一张“物体地图”。但光有地图还不够,团队又加了两道“对齐保险”:
第一道是语义对齐。请出Meta的DINOv2模型当“老师”,它能从高清图里提取出最准确的物体语义特征。InstanceRSR的扩散模型作为“学生”,要把自己生成的特征和老师的特征对齐——就像学画画时,老师告诉你“毛衣的针脚应该是这种交错的质感”,而不是随便画几道线。
第二道是实例尺度对齐。给每个物体分配一个随机的“浓度值”,比如毛衣是1.2,树叶是0.8,要求模型把同一个物体的所有特征都聚集在这个浓度值周围。这招的妙处在于,它不管具体数值,只要求模型能分清“这是毛衣”“那是树叶”——就像给每个物体贴了个独特的标签,再也不会混在一起。
这套组合拳打下来,AI终于能做到:全局清晰度靠低分辨率图保证,每个物体的细节靠“物体地图”和两道对齐机制精准还原。
在DrealSR、RealSR等四个真实世界超分基准数据集上,InstanceRSR把所有主流指标都刷到了第一。比如衡量感知差异的LPIPS指标,它的分数最低——意味着生成的图和真实高清图在纹理、结构上最像;还有不需要真实高清图参考的MUSIQ、MANIQA等指标,它也全拿了第一,说明人眼看起来就是更清晰自然。
视觉对比更直观:用StableSR处理的窗户,格子歪歪扭扭;用InstanceRSR处理的窗户,横平竖直,每一根窗棂都清清楚楚。前者的花瓣脉络糊成一片,后者的花瓣纹理根根分明,连边缘的锯齿都清晰可见。

当然它也有局限:它依赖SAM的分割结果,如果SAM在复杂场景下分错了物体,比如把毛衣上的图案当成了背景,最终的超分结果也会跟着错。而且它需要调用SAM、DINOv2、DiT三个大模型,计算量不小,现在还没法在手机上实时运行。但这些问题,都挡不住它的核心价值:它给超分技术指了一条新路子——与其在退化模型里内卷,不如先让AI“看懂”画面里的每个物体。
InstanceRSR的出现,本质上是超分技术的一次“认知升级”:从“像素级的修复”,跳到了“物体级的理解”。过去我们总说AI能“生成”高清图,现在它终于能“读懂”要修复的内容了。
这不仅能让老照片修复得更逼真、监控画面看得更清楚,更给所有图像生成任务提了个醒:AI的生成能力,永远受限于它的认知能力。当AI能认出每一片树叶、每一根针脚,它才能真正还原出那个充满细节的真实世界。
看清细节的前提,是先看懂物体。