对抗知识焦虑,从看懂这条开始
App 下载
3亿押注AI视频:从看视频到玩视频
C轮融资|视频交互产品|Runway|AI视频赛道|爱诗科技|AIGC|人工智能
对抗知识焦虑,从看懂这条开始
App 下载C轮融资|视频交互产品|Runway|AI视频赛道|爱诗科技|AIGC|人工智能
2026年3月的AI圈,有个数字比OpenAI的融资更值得咂摸:成立不到3年的爱诗科技,拿到了3亿美元C轮融资——这是国内AI视频赛道单笔融资的最高纪录。而美国的Runway,花了7年才在2026年初拿到差不多量级的E轮。
更反常的是,这笔钱的押注重点,不是能生成更逼真视频的模型,而是一款能让你「玩」视频的产品:你可以在播放中的视频里改背景、调光影、让主角转身,系统2秒内就能给出响应。

为什么资本愿意为「玩视频」砸下重金?这得从三年前一个反常识的技术选择说起。
2023年,当国内AI视频团队都在抢用成熟的U-Net架构时,爱诗科技选了当时没人看好的DiT——扩散模型(Diffusion)和Transformer结合的架构。
你可以把U-Net想象成一个熟练的修图师,擅长把局部细节磨得完美,但要让它理解一整段视频里主角从客厅走到厨房的完整逻辑,就像让一个只会抠细节的人写长篇小说,力不从心。而DiT更像一个会读剧本的导演:它把视频拆成一个个小画面块,通过Transformer的「全局注意力」,能同时盯着从开头到结尾的所有帧,记住主角的发型、杯子的位置,甚至光影的方向。
当然,这个选择在当时要付出代价:DiT初期训练对算力和数据的要求是U-Net的数倍,前三个月生成的视频甚至不如U-Net流畅。但爱诗赌的是长期:U-Net的局部优势是天花板,而DiT的全局能力,能支撑起更复杂的视频逻辑——比如让视频里的世界,像真实世界一样能被改变。
2024年OpenAI发布Sora时,公开的核心架构正是DiT。此时爱诗已经在DiT上跑了一年多的训练数据,积累的工程经验,成了后来实时交互的技术底座。
如果说DiT是地基,那PixVerse R1就是爱诗在上面盖的第一栋「可交互大楼」。
过去的AI视频生成,本质是「离线渲染」——你输入指令,等几分钟拿到一段固定的视频,就像洗胶卷,出来什么样就是什么样。但R1不一样,它是一个「实时交互式世界模型」:你在视频播放时输入「把晴天改成雨天」,2秒后画面里就会落下雨滴,主角会下意识拉衣领,甚至地面会慢慢变湿。
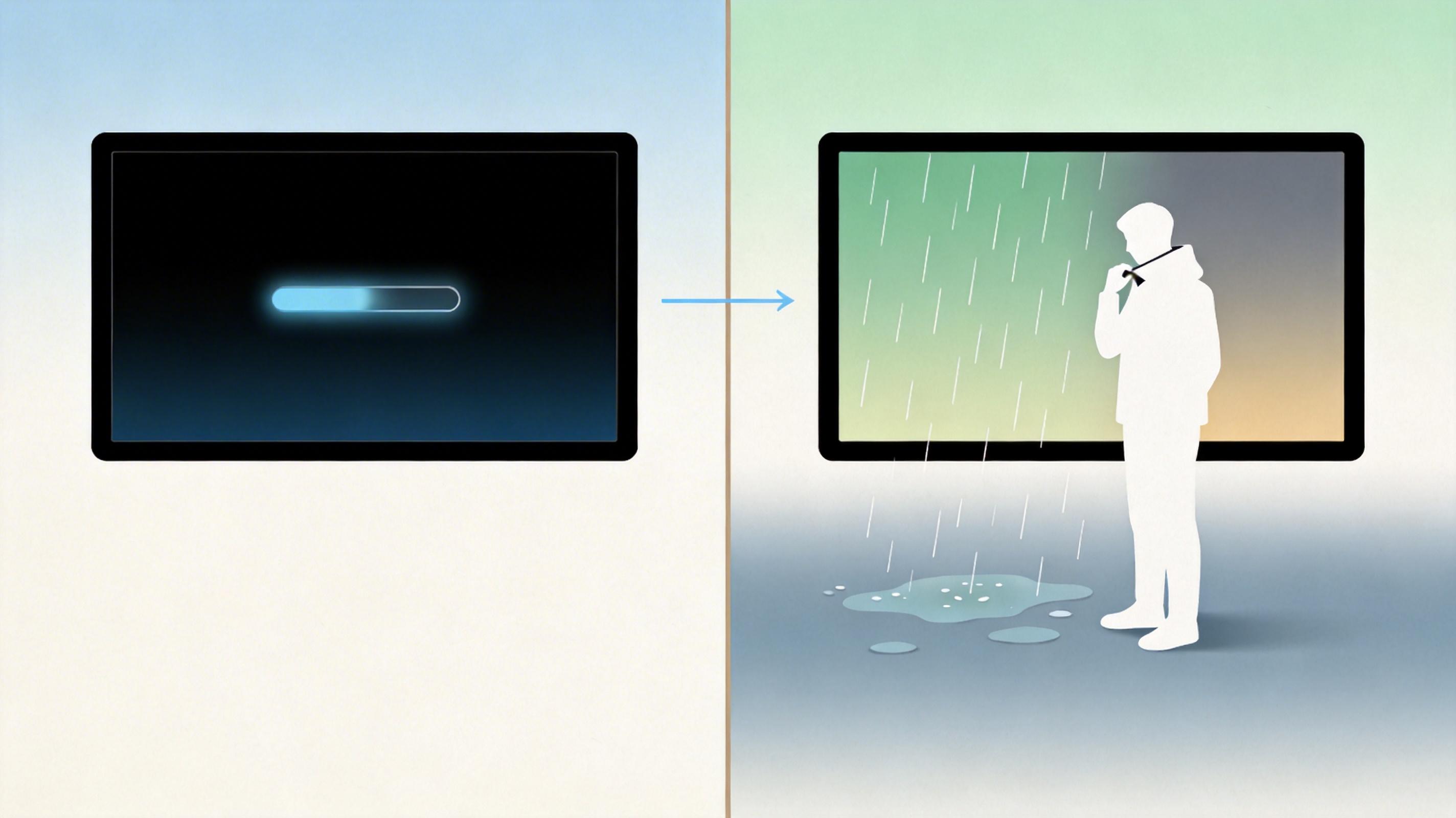
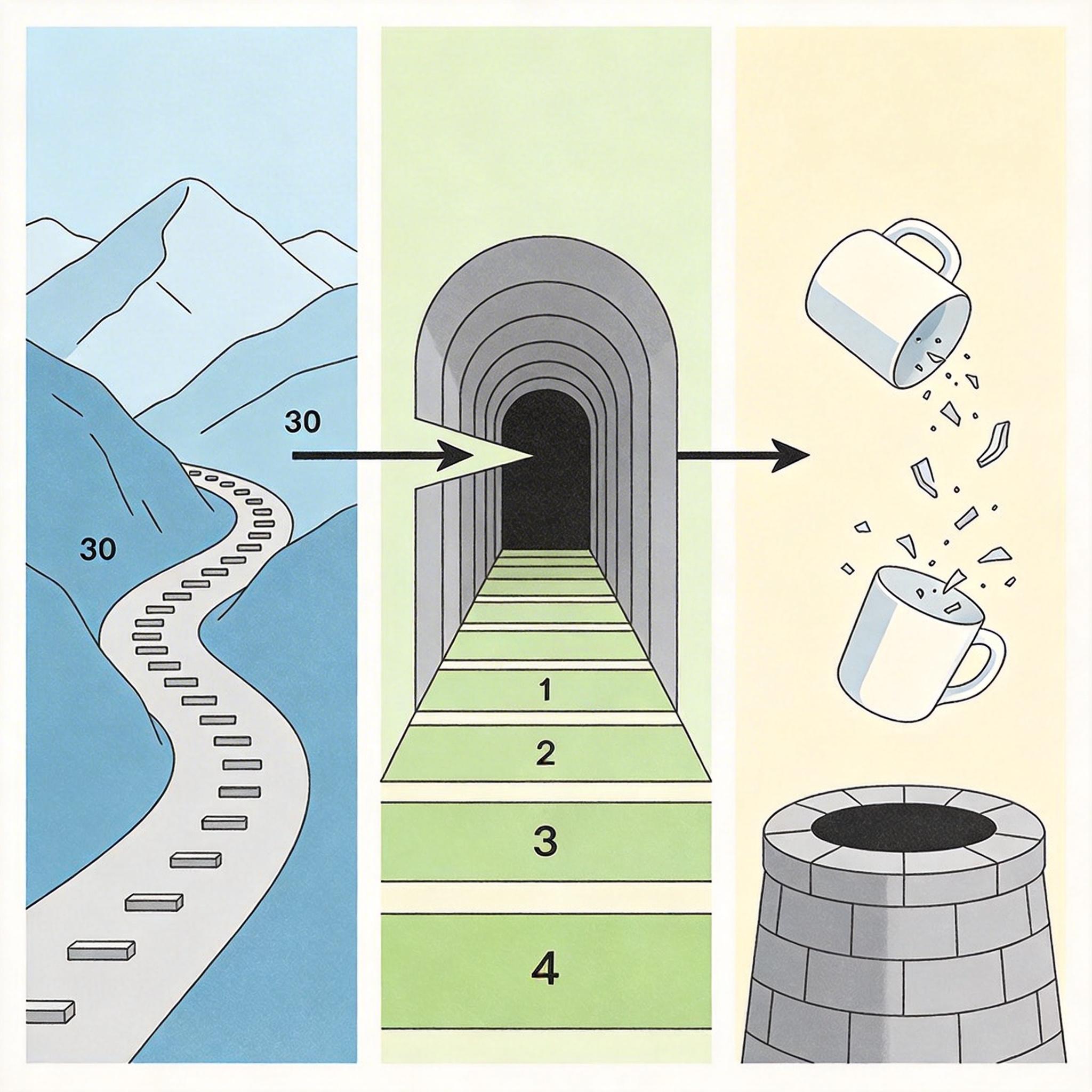
这背后的关键是爱诗自研的「瞬时响应引擎(IRE)」。传统扩散模型要把噪声一步步变成视频,得走几十步计算,IRE把这个过程压缩到了1-4步——相当于把一条绕远的盘山公路,修成了直达山顶的隧道。它还在模型里加入了「空间记忆」,能记住视频里每一个物体的位置和物理属性,比如杯子掉在地上会碎,而不是飘起来。
这个变化的意义,已经超出了「更好的视频工具」。影视公司可以用它快速做互动剧的Demo,游戏公司能直接生成可玩的关卡原型,甚至教育领域能做出「可以亲手调整实验参数」的虚拟课堂。用爱诗联合创始人谢旭璋的话说:「未来视频和游戏的边界会消失,视频不再是用来『看』的,而是用来『进入』的。」
鼎晖领投3亿美元时,看中的不只是R1的技术参数,而是它背后的产业信号:AI视频终于从「辅助工具」,变成了能重塑行业的「基础设施」。
过去,视频生产是「专业门槛极高的线性流程」——写脚本、拍素材、剪片子,每一步都要专业人做专业事。AI视频生成把这个流程缩短了,但本质还是「批量生产视频」。而实时交互的世界模型,是把「生产视频」变成了「搭建世界」——你不需要写好完整脚本,只需要设定规则,用户就能自己在里面创造内容。
这也是为什么产业资本会扎堆入场:中国儒意(影视)看中了互动内容的新形态,三七互娱(游戏)看到了AI原生游戏的可能性。当视频能像游戏一样被实时操作,广告可以让用户自己切换产品颜色,短剧可以让观众决定主角的选择,整个内容产业的生产逻辑都会被改写。
当然,现在的R1还不完美:长时交互下偶尔会出现物体「漂移」,物理细节也不如离线生成的精细。但资本赌的是「趋势」——就像当年智能手机刚出来时,没人会因为它不如PC流畅就否定它。
三年前,爱诗选择DiT时,有人说他们「放着成熟的路不走,偏要绕远」。现在看,他们只是提前走上了一条更宽的路。
我们这代人习惯了「视频是用来观看的」,就像上一代人习惯了「电视是用来接收信号的」。但技术的迭代,往往就是从「打破习惯」开始的——当视频能被实时交互,当我们能在数字世界里像在现实中一样行动,视频就不再是内容,而是一个入口。
视频的未来,是可进入的世界。
这笔3亿美元的融资,与其说是押注AI视频,不如说是押注一个正在到来的、人与数字世界更紧密连接的时代。