对抗知识焦虑,从看懂这条开始
App 下载
不碰DOM算文本高度,快了200倍还准
虚拟列表|GitHub开源库|前端性能优化|文本高度计算|软件工程|前沿科技
对抗知识焦虑,从看懂这条开始
App 下载虚拟列表|GitHub开源库|前端性能优化|文本高度计算|软件工程|前沿科技
你有没有刷到过这样的网页:滚动聊天列表丝滑得像摸丝绸,瀑布流图片加载完全不抖,虚拟列表划多久都不卡?这种体验在Web开发里曾是奢望——因为要让文字在指定宽度里精准显示,过去30年只能靠浏览器反复计算整个页面布局,频繁操作的话,性能直接掉到谷底。
直到三天前,一个15KB的小库在GitHub上拿到了3.4万星,把这个卡了前端圈30年的问题给解决了。它能在完全不碰DOM的前提下,精确算出一段文字的高度,速度是传统方法的200倍以上。更狠的是,中文、阿拉伯文、日文这些难搞的多语言文本,它都能算得丝毫不差。
你可以把过去的文本测量想象成:要知道一筐书堆起来有多高,就得先把整筐书搬上秤,读完每本书的内容,再重新堆一遍——每测一次,就得把整个流程走一遍。浏览器的getBoundingClientRect或者offsetHeight就是这个笨办法,每次调用都要强制浏览器重新计算页面布局,在虚拟滚动、聊天界面这种要频繁测量的场景里,相当于让浏览器一直在“搬书堆书”,不卡才怪。

这个小库的破局点,是把测量拆成了完全独立的两步:
第一步是预处理:把输入的文本按语言规则拆成片段,比如英文按单词、中文按语义块,再用Canvas的测量API算出每个片段的宽度,把结果存进缓存里。这一步相当于先把每本书的厚度单独测好记下来,500段文本大概要19毫秒,只需要做一次。
第二步是**纯算术布局**:拿到预处理好的宽度数据,用简单的除法和加法算换行——给定容器宽度,一段段累加文本宽度,超了就换行,最后把所有行的高度加起来。这一步就像拿着每本书的厚度清单,直接算堆高,500段文本只需要0.09毫秒。
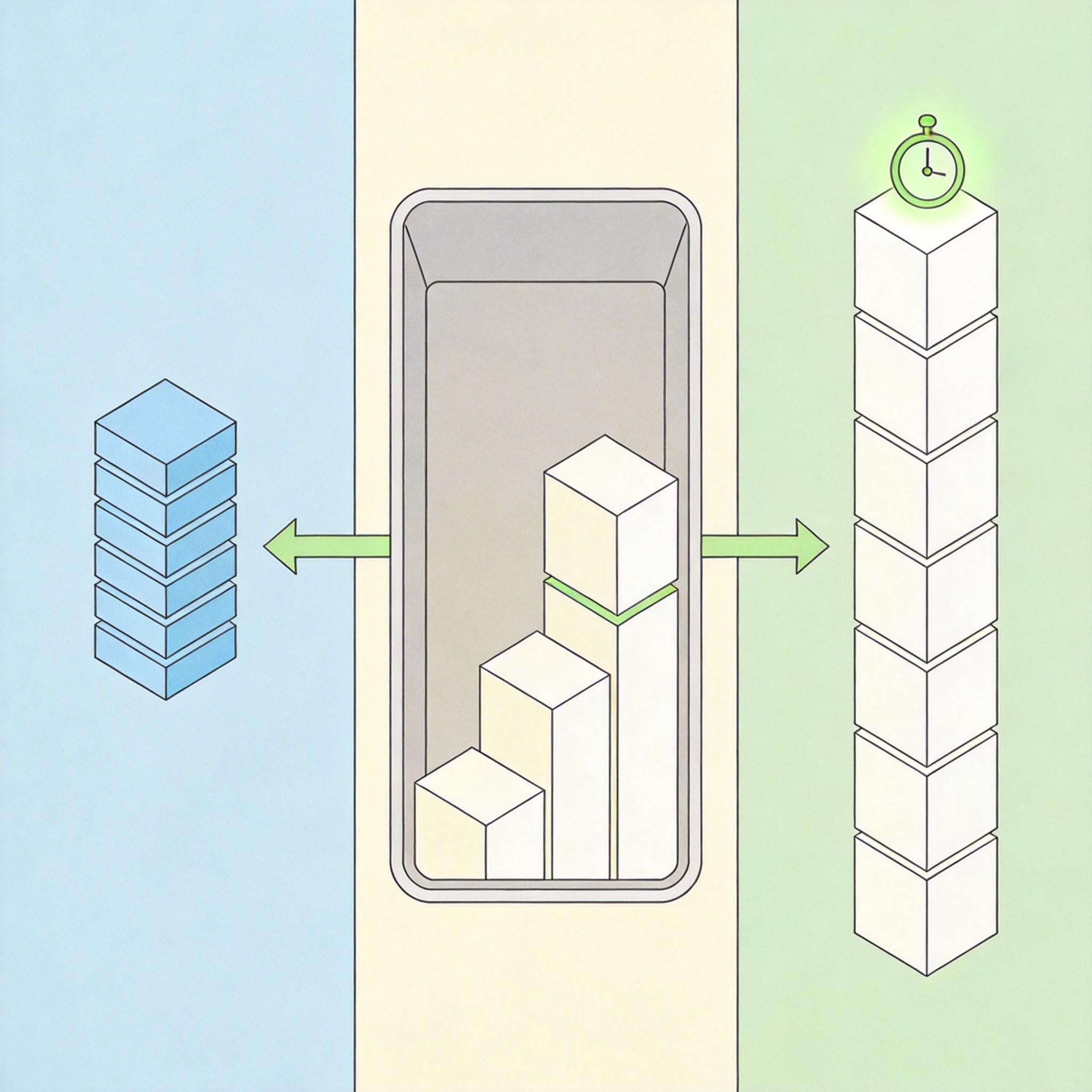
关键是,当窗口大小变化时,只需要重新跑第二步就行——预处理的缓存还在,不用再“拆书测厚度”了。
你可能会问:不靠浏览器的DOM渲染,怎么保证算出来的高度和实际显示的一模一样?
秘密藏在预处理阶段的细节里。它没有自己造一套文本渲染规则,而是直接用了浏览器原生的Canvas测量能力——Canvas的<a class="wiki-keyword" data-keyword="measureText" href="#">measureText</a>API和浏览器渲染文本用的是同一套字体引擎,能精准算出每个字符的宽度、字距甚至连字效果。同时,它还处理了最让前端头疼的多语言问题:
比如阿拉伯文这种从右到左的语言,它会按Unicode双向文本规则重新排序片段;中文、日文没有空格分词,它会用语言特定的断行规则拆分;甚至连表情符号这种特殊字符,它也能准确识别宽度。开发团队用整本《了不起的盖茨比》和几十种语言的文本做测试,在Chrome、Safari、Firefox上的准确率都是100%。
当然它也不是万能的。目前它还不支持富文本的复杂样式,比如加粗、斜体混排的文本测量,也没法处理CSS里的letter-spacing这种精细调整。而且如果遇到非常生僻的字体,Canvas的测量结果可能和实际渲染有细微偏差——不过对于绝大多数日常开发场景,这些局限暂时还不影响它的实用性。
这个库能火,不止是因为解决了性能问题,更因为它给前端开发提了个醒:有些被当成“常识”的操作,其实换个思路就能彻底优化。
过去我们总觉得,要获取页面元素的尺寸,必须碰DOM;要做文本布局,必须依赖浏览器的渲染引擎。但这个库证明了,把复杂的渲染过程拆成“数据预处理”和“纯逻辑计算”,就能在不依赖DOM的前提下,拿到精准的结果。这种两阶段架构其实在信息检索领域早就用烂了——先召回候选结果,再精细排序,本质都是用一次相对重的计算,换无数次轻量的复用。
开发团队在做测试的时候,还用上了AI工具:让Claude Code和Codex在几十种容器宽度下对比浏览器的真实渲染结果,自动修正算法里的偏差。这种“AI辅助验证”的方式,也给开源项目的测试提供了新的可能性——不用靠人工写几百个测试用例,AI就能帮你覆盖绝大多数边界场景。
你可能觉得,一个文本测量库而已,犯得着这么激动吗?但前端开发的进步,往往就是从这种“小问题”开始的——30年来,我们一直在为了一点点性能提升抠细节,从减少DOM操作到用虚拟DOM,从防抖节流到Web Worker,本质都是在和浏览器的渲染性能较劲。
这个15KB的小库,就像一把小扳手,看似只拧动了一个小螺丝,却撬开了一个被忽略已久的思路:原来我们不需要一直跟着浏览器的规则走,换个姿势,就能把过去的“不可能”变成“随手能用”。
好的工具,总在帮人偷懒——用更聪明的方式。