对抗知识焦虑,从看懂这条开始
App 下载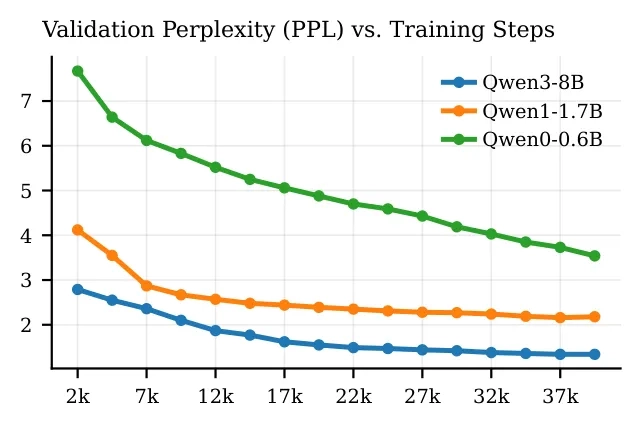
北大团队让大模型一秒学会新知识
开源项目|高效学习|知识注入|SHINE架构|北京大学|大语言模型|人工智能
想象你刚读完一本10万字的专业手册,转头要给别人讲透里面的核心知识——正常人得花几小时梳理重点,大模型以前也得跟着学上好几轮。但现在,北京大学的团队做了件离谱的事:让大模型扫一眼文本,0.1秒就能把知识刻进自己的参数里,还能直接用这些知识跟你聊一下午。不用反复输入文本当提示,不用花几小时微调训练,一次前向传播就搞定。这不是科幻,是今天刚开源的SHINE架构——它把大模型的「学习效率」直接拉到了人类都望尘莫及的地步。为什么这一步就能颠覆大模型的知识注入逻辑?
从「死记硬背」到「一键刻入」的质变
你可以把大模型想象成一个装满书的图书馆,以前要让它学会新知识,要么是把整本书拆成碎纸条塞进提示词(也就是In-Context Learning),每次查资料都得翻一遍;要么是重新装修书架(监督微调),得花好几天功夫。而SHINE做的,是给图书馆装了台「知识复印机」——超网络(Hypernetwork)。
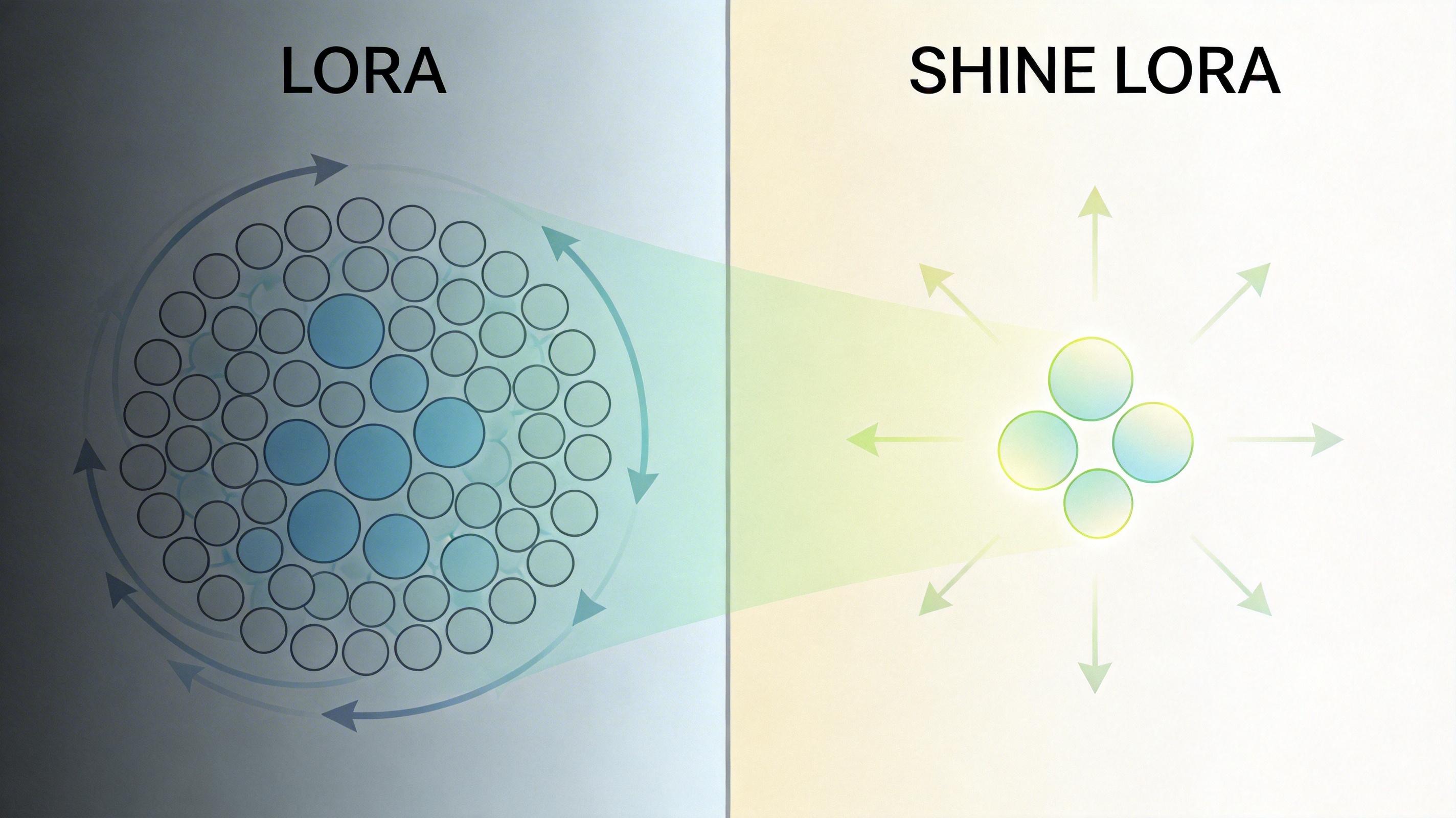
超网络是个特殊的神经网络,它的输出不是答案,是另一个网络的参数。在SHINE这里,它的任务就是把输入的文本,直接生成大模型的LoRA参数。LoRA你可以理解成「图书馆的临时索引卡」:不用动书架上的书(大模型的预训练参数),只要加几张索引卡,就能让图书馆立刻学会怎么找新资料。
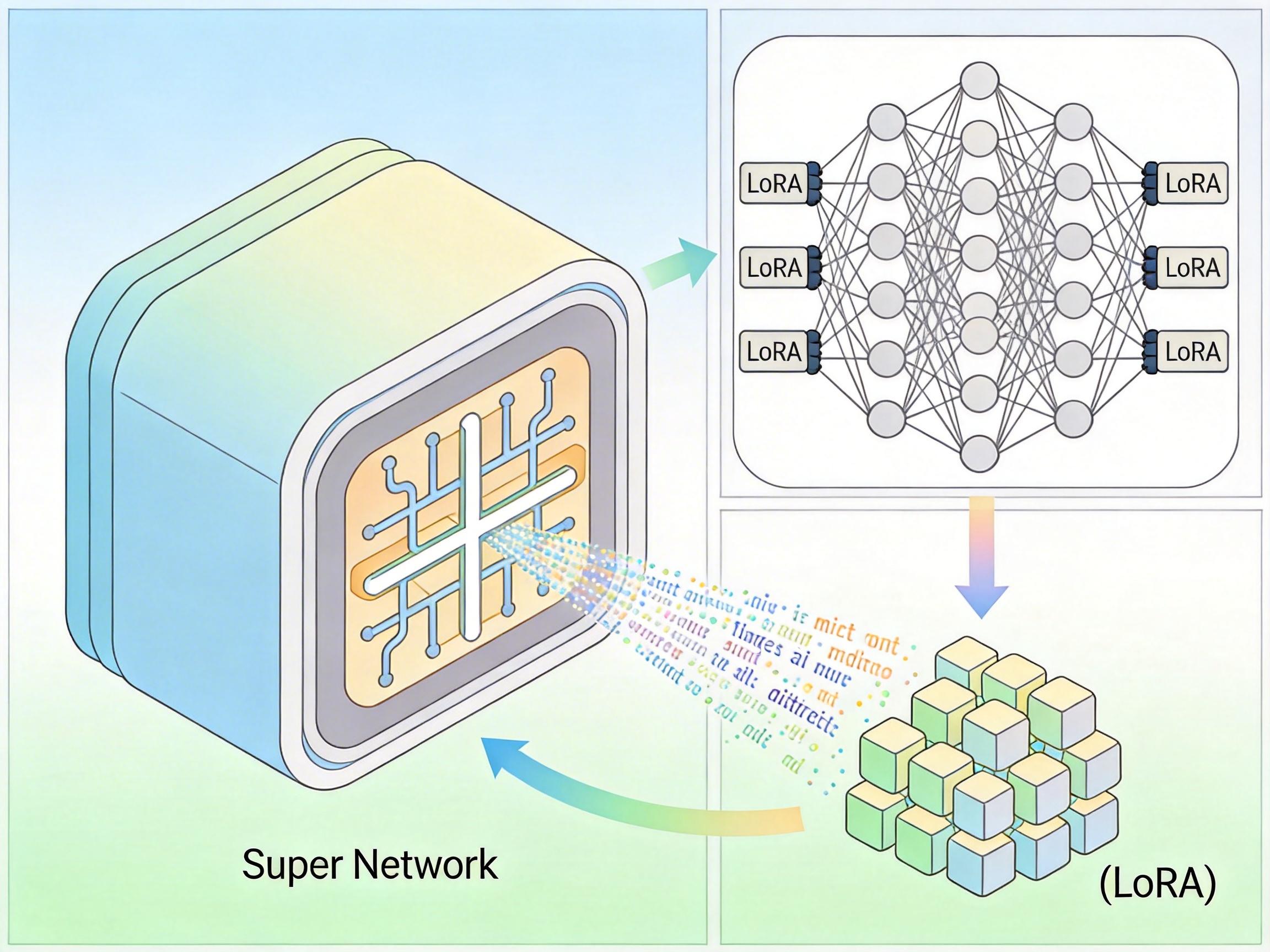
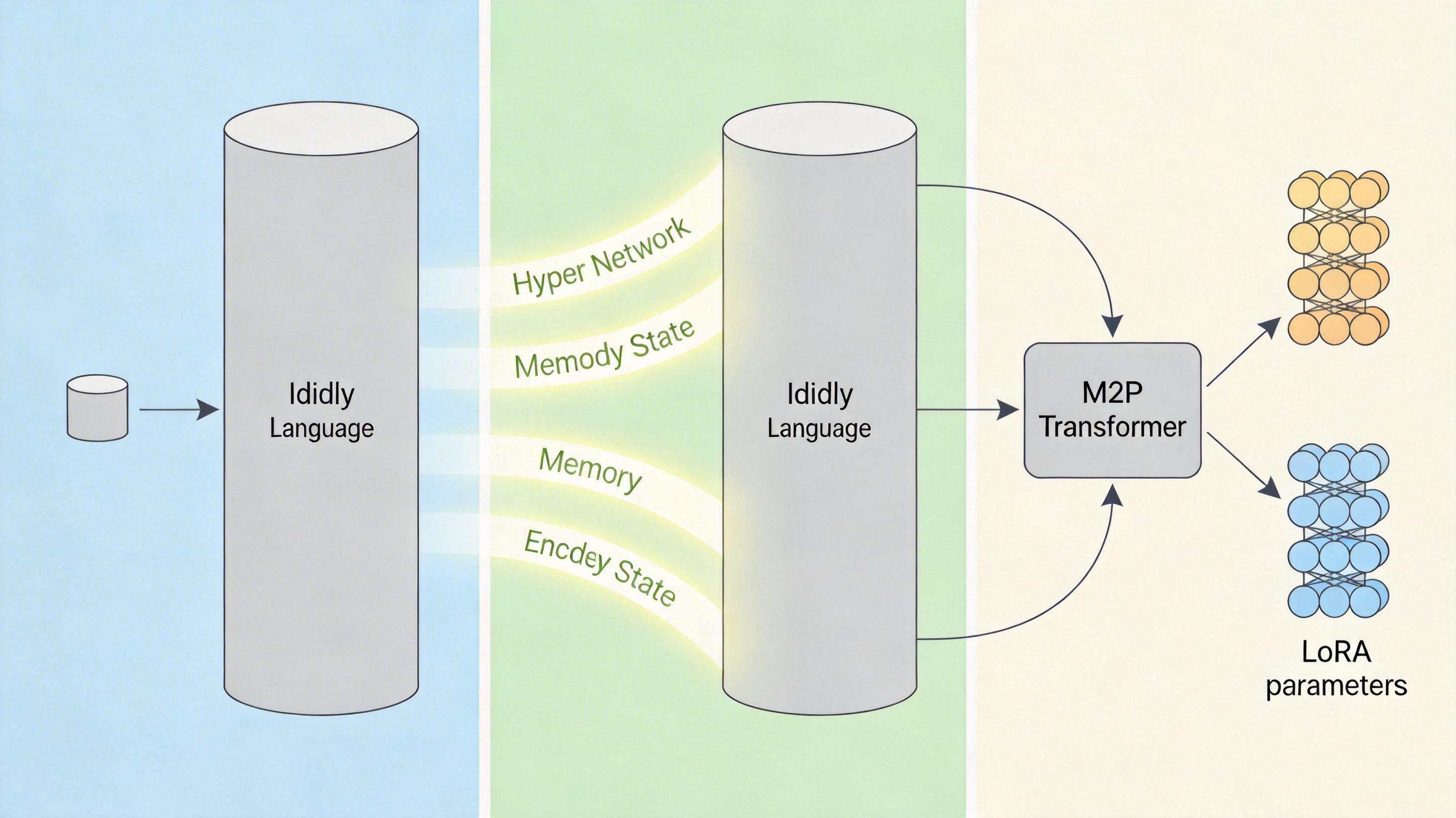
以前的超网络要么只能给小模型做参数,要么就靠个小型MLP凑数,生成的索引卡根本没法用在大模型上。SHINE的巧劲在于,它直接复用了大模型本身的能力:先让大模型把文本编码成中间的「记忆状态」,再用一个轻量级的M2P Transformer把这些状态转换成LoRA参数。整个过程只需要一次前向传播,相当于扫一眼文本就把索引卡做出来了。
比传统方法快100倍,还更准
在SQuAD问答数据集的测试里,SHINE生成的LoRA,效果甚至比需要花几小时做测试时训练(TTT)的LoRA还好。更关键的是效率:传统微调一个LoRA要跑好几轮训练,SHINE只需要0.1秒。推理的时候也不用再把大段文本当提示词输入,直接用生成的LoRA就行,token消耗直接砍了80%,计算成本也降了一大半。
它的训练逻辑也跟大模型的「预训练-指令微调」路子完全对齐:先用60亿token的文本做预训练,让超网络学会怎么把文本转换成有用的LoRA;再用问答数据做指令微调,让它生成的LoRA能精准回答问题。而且随着数据量和模型规模的增大,SHINE的性能还在持续提升,目前还没看到瓶颈——这是以前那些靠小型MLP的超网络根本做不到的。
当然,它也不是完美的。现在处理超长文本的时候,还得靠分块生成多个LoRA组合;面对特别复杂的推理任务,生成的LoRA偶尔会掉链子。但这些问题,都挡不住它成为大模型持续学习的新标杆:毕竟,谁能拒绝一个一秒钟就能学会新知识的模型呢?
从实验室到产业的一步之遥
SHINE刚开源,就已经有同行跟上了——Sakana AI的Doc-to-LoRA、腾讯的HY-WU,都是类似的「超网络生成LoRA」思路。这说明,大模型的知识注入正在从「反复训练」转向「即时生成」,而SHINE就是捅破这层窗户纸的那个。
对产业界来说,这意味着什么?客服机器人可以一秒钟学会新的产品手册,智能助理可以瞬间掌握你的日程偏好,甚至医生的AI助手能立刻记住一个罕见病例的所有细节——而且这些知识都存在参数里,不用每次都去查数据库。更重要的是,它解决了大模型「持续学习」的核心痛点:不用怕学了新的忘了旧的,每个新知识都是一张独立的索引卡,随时可以加,也随时可以拆。
当然,安全问题也得提一嘴:既然LoRA可以一键生成,那恶意攻击者会不会生成带后门的LoRA?比如让模型在特定关键词下输出错误信息。这也是未来需要解决的问题——毕竟,效率越高的工具,越需要可靠的安全闸。
我们以前总说,大模型的学习像人类,但SHINE让它变成了另一种生物——一种能把知识直接「刻进DNA」的生物。以前大模型的「记忆」存在训练数据里,后来存在提示词里,现在,它终于可以把知识存在自己的参数里,像人类把经验刻进脑子里一样。
「知识不是输入的文本,是刻入的参数」——这可能是大模型从「信息检索工具」变成「真正的学习者」的第一步。当大模型能在0.1秒内学会新知识,我们对AI的想象边界,又被拓宽了一点点。