对抗知识焦虑,从看懂这条开始
App 下载
别再调模型了,AI系统的未来在这层‘操作系统’
自我优化系统|AI操作系统|MIT|斯坦福|Meta-Harness|大语言模型|人工智能
对抗知识焦虑,从看懂这条开始
App 下载自我优化系统|AI操作系统|MIT|斯坦福|Meta-Harness|大语言模型|人工智能
当你还在为大模型的一两个百分点准确率反复修改提示词时,斯坦福和MIT的团队已经换了赛道:他们不再死磕模型本身,而是给大模型套上了一套能自我优化的‘操作系统’——Meta-Harness。这套系统把AI的工作逻辑、调用工具的流程、甚至处理上下文的方式,都变成了可以自动迭代的程序。在文本分类任务里,它把准确率从40.9%拉到48.6%,同时把上下文开销砍到原来的五分之一。更关键的是,它完全不用人盯着试错,全靠AI自己翻历史日志、找问题、改代码。这背后的逻辑,可能彻底改变AI系统的优化方式。
你可以把大模型想象成一台性能极强的CPU,但没有操作系统的话,它连打开一个文件都做不到。这里的‘操作系统’就是harness——它负责给大模型安排任务、管理上下文、调用工具,甚至记住之前的工作进度。过去,这套‘操作系统’全靠工程师手工写,就像给每台电脑单独定制DOS命令,不仅慢,还容易出错。
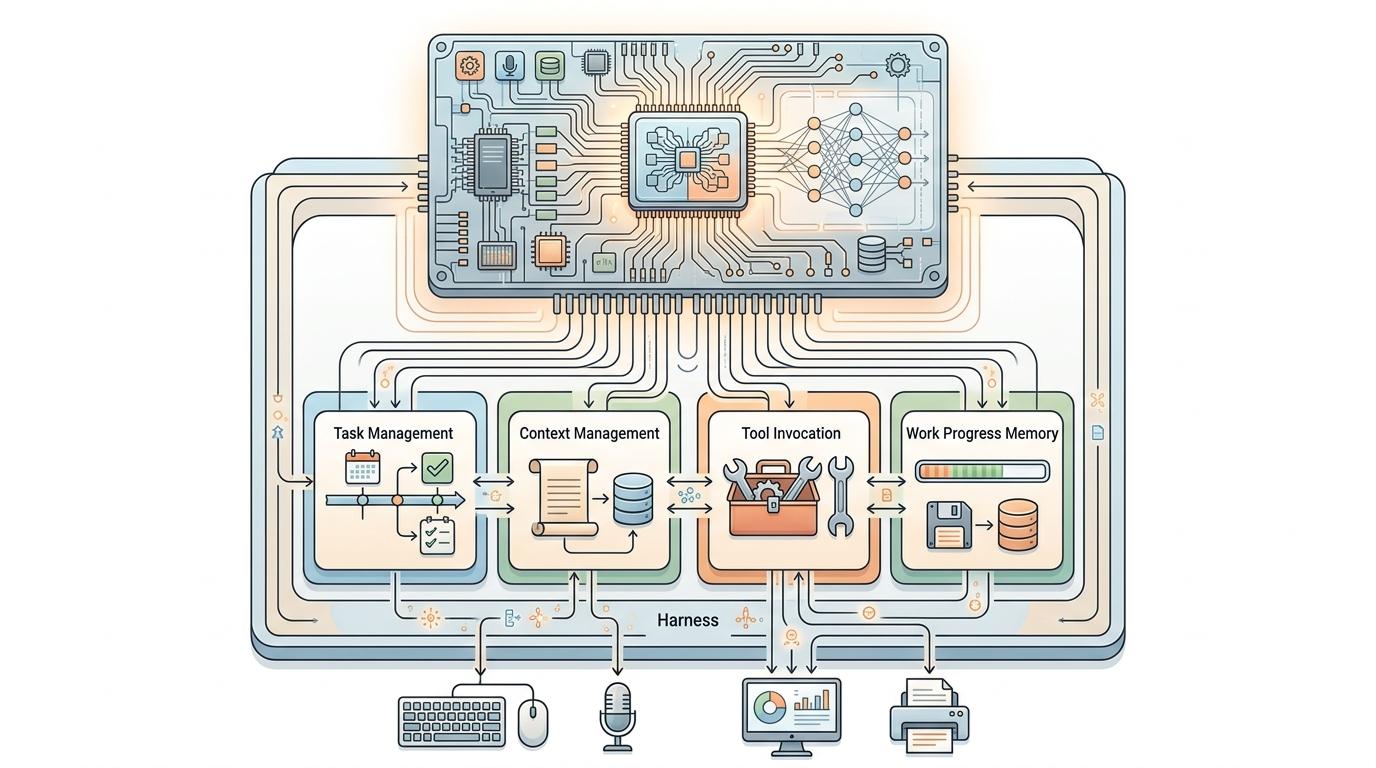
Meta-Harness的核心突破,就是把整个harness程序变成了优化对象。它不像传统方法只改一两句提示词,而是直接让AI自己写代码、测性能、改逻辑。每一次尝试的代码、运行结果、甚至出错时的详细轨迹,都会被完整存在文件系统里,就像给AI留了一本可以随时翻的‘错题本’。AI会用终端命令自己去查这些日志,分析上次为什么失败——是上下文切错了,还是工具调用时机不对——然后针对性地修改harness程序。
这个过程完全自动化:提出候选方案→测试→写日志→再改进,一轮接一轮。在数学推理任务里,它甚至自己摸索出了一套‘四路检索法’,会根据题型自动切换搜索策略,比人工设计的方法还灵活。
传统AI优化有个致命问题:总喜欢把反馈压缩成简单的分数或者摘要。比如模型做错了,只告诉它‘得分60’,却不说是哪一步错了、怎么错的。就像老师改作业只打个分,不写错题原因,学生根本不知道怎么改。
Meta-Harness彻底抛弃了这种偷懒的做法。它让AI直接读取最原始的执行轨迹——比如代码运行时每一步的输入输出、调用工具的记录、甚至中间思考的过程。在消融实验里,只看分数和代码的话,AI的准确率只有41.3%;加上LLM生成的摘要,反而降到38.7%;但一给原始执行轨迹,准确率直接冲到56.7%。这说明那些被压缩掉的‘细节’,才是优化的关键。
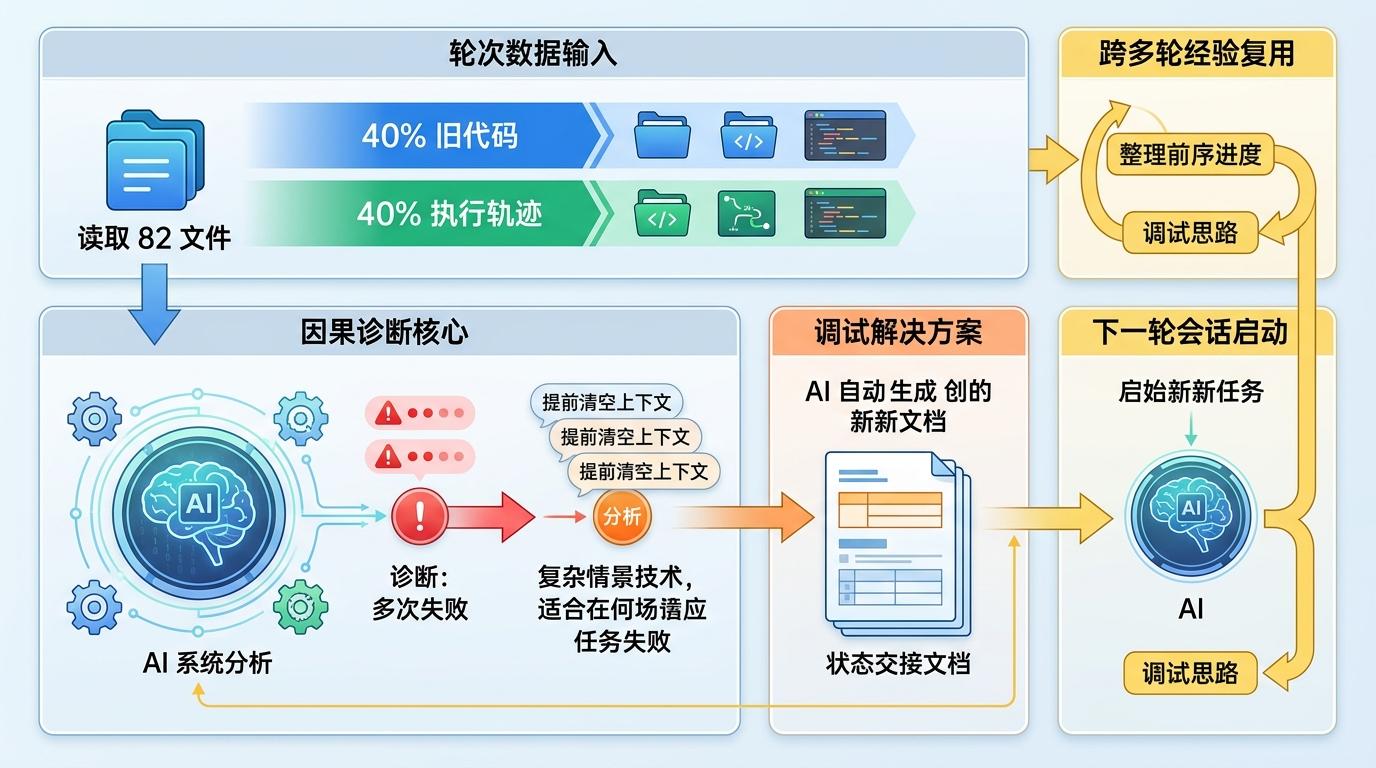
实验里的AI每轮要读82个文件,其中40%是旧代码,40%是执行轨迹。它不是在瞎试,而是在做‘因果诊断’——比如发现几次失败都是因为在复杂任务里提前清空了上下文,就会自动加上‘状态交接文档’,把之前的工作进度整理好再启动新会话。这种跨多轮的经验复用,已经有点像人类工程师的调试思路了。
Meta-Harness的出现,也在悄悄改变AI工程师的工作。过去大家的精力都放在‘调模型’上——改提示词、调参数、找数据。现在,工程师更像‘系统架构师’:设计harness的基本框架、制定测试标准、给AI划定安全边界,剩下的优化工作,交给AI自己来做。
这种转变已经在产业端显现:金融、医疗这些对AI可靠性要求极高的行业,开始用自动化harness来管理复杂任务。比如某汽车厂商用类似思路优化自动驾驶的决策流程,把开发周期缩短了30%。而那些只会改提示词的‘prompt工程师’,可能会慢慢被能设计系统的工程师取代。
当然,这套系统也有局限:它目前还只能优化单文件的Python程序,面对超大规模的分布式系统还有难度;而且AI自己写的代码,有时候会出现逻辑漏洞,需要人类做最终把关。但不可否认的是,它已经打开了一扇门——让AI不仅能解决任务,还能优化解决任务的方式。
当大模型的参数竞赛逐渐触顶,人们开始意识到,AI的上限从来不是模型本身,而是模型之外的‘工作方式’。Meta-Harness就像给大模型装上了一个能自我进化的大脑,让它从‘只会干活的工具’,变成了‘会优化干活方法的助手’。
未来的AI系统,可能不再是一个孤立的模型,而是一套能自我迭代、自我修复的生态。就像人类从手工制作到流水线生产,再到智能制造,每一次生产方式的升级,都带来了效率的爆炸式增长。AI的下一个时代,或许就藏在这层看不见的‘操作系统’里。
模型是引擎,系统才是赛道。