对抗知识焦虑,从看懂这条开始
App 下载
词元成AI新计量单位,智能经济正在换引擎
AI计量单位|数据要素改革|智能经济|词元套餐|词元|大语言模型|人工智能
对抗知识焦虑,从看懂这条开始
App 下载AI计量单位|数据要素改革|智能经济|词元套餐|词元|大语言模型|人工智能
2026年3月的一天,中国每一秒就有超过16万亿个「词元」在AI模型里流转——这个数字是2024年初的1400倍。你用AI写方案、剪视频、查资料的每一次操作,背后都是成百上千万个词元在被调用、计算、计费。当三大运营商开始像卖流量一样卖「词元套餐」,当国家把词元经济纳入数据要素改革的核心,很多人还没意识到:我们熟悉的数字经济,正在被这个看不见的小单位彻底重构。为什么一个AI运算的最小单元,能成为智能经济的新锚点?
你可以把词元理解成AI世界的「千瓦时」——它是大模型处理文本、图像、视频等所有信息的最小运算单元,就像电网里的每一度电。但它的作用远不止于此:它是AI服务的计量单位,像流量一样能统计使用量;是结算单位,按调用量付费的模式让AI从「定制化奢侈品」变成「按需购买的公共服务」;更是统计单位,能精准反映AI产业的活跃度。
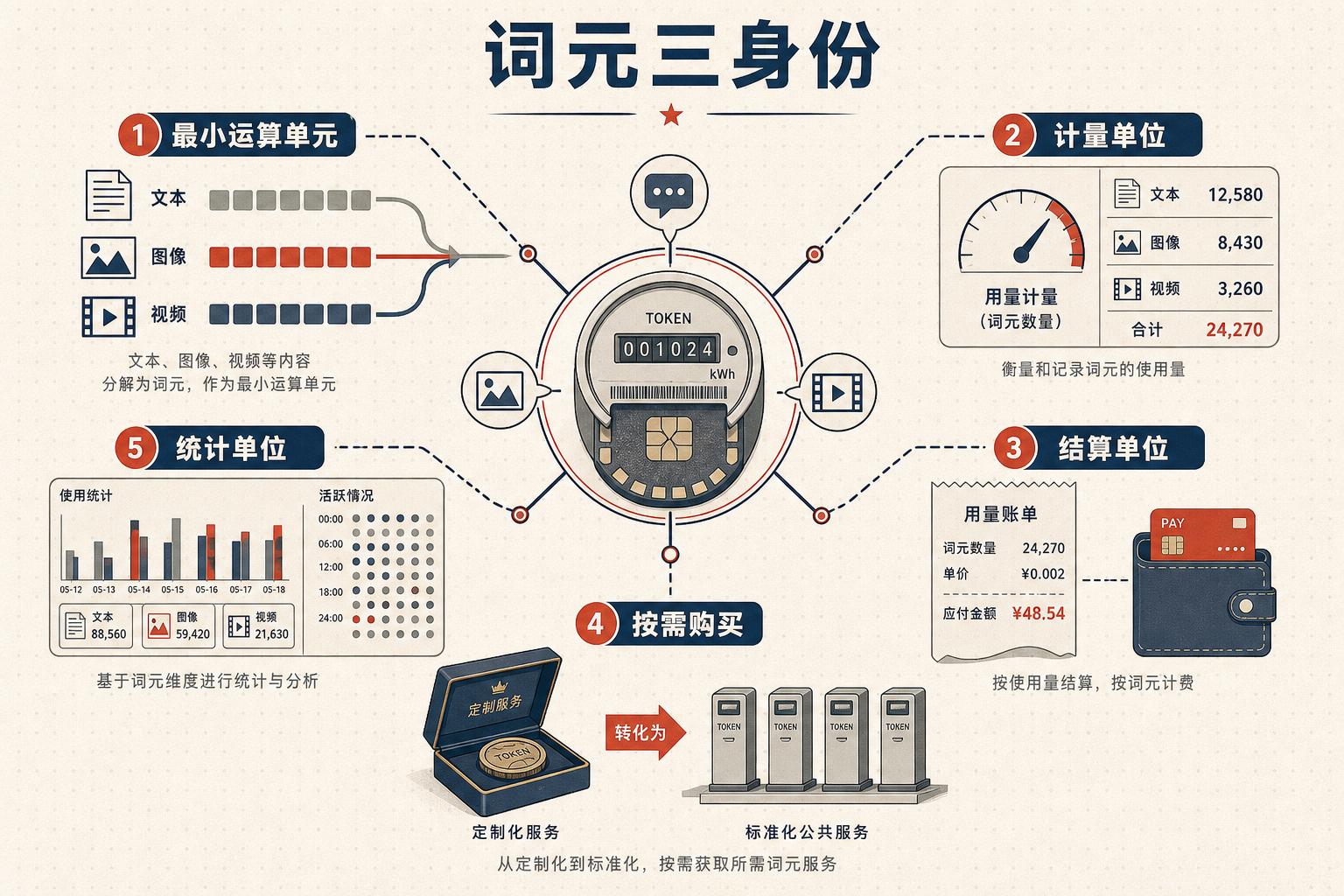
2026年3月,中国日均词元调用量突破140万亿,三个月内增长40%。这个数字的背后,是中小微企业不用再花百万成本自建算力,买个词元套餐就能部署AI客服;是运营商把机房里的算力变成了手机上能订阅的服务;是数据、算力、算法这三个AI核心要素,第一次被同一个单位串联了起来——词元就像一根线,把分散的数字资源拧成了能流通、能计价、能规模化使用的智能经济链条。
当全球每周词元用量达到27万亿时,中国模型占了近一半份额。这不是靠低价竞争的偶然——中国的词元经济正在形成一套独特的优势:西部的清洁能源支撑了更低的算力成本,自研的稀疏注意力机制让模型处理长文本的效率提升数倍,多模态模型把视频、语音转化为词元的损耗率降到了全球最低。
比如DeepSeek V3.2模型,用线性复杂度的注意力机制替代传统的平方级运算,处理128K上下文的词元消耗只有同类模型的1/3;字节跳动的Doubao模型,把一分钟视频转化为可计算的词元时,能通过缓存机制节省80%以上的重复计算。这些技术突破让中国的词元不仅有量的规模,更有了质的效率——我们正在从「全球最大的词元消费者」,变成「最会用词元的智能经济体」。
但词元经济的繁荣里,也藏着容易被忽略的陷阱。
很多企业以为选了低价的开源模型就省了钱,却没发现完成同样的任务,开源模型的词元消耗是闭源模型的1.5到4倍——简单查询甚至会差10倍。这种「单价低但用量大」的效率幻觉,会让企业的AI成本在规模化后失控。更棘手的是,当词元消耗被当成KPI考核时,会出现AI砍价机器人互相对话产生无效词元、员工为了刷指标反复调用模型的浪费现象,这就是经济学里的「古德哈特定律」:当指标成为目标,它就不再是有效的指标了。
同时,算力的增长速度还跟不上词元的爆发——2026年全球AI算力缺口仍有30%,高端芯片的制造周期要18个月,而词元调用量每三个月就增长40%。我们既要避免为了追求词元数量而浪费算力,也要解决基础设施跟不上需求的矛盾。
当我们把AI的能力拆成一个个可计量的词元,其实是在给智能经济搭一套全新的「基础设施」——就像一百年前电网把电力变成公共资源一样,词元正在把AI能力变成每个人、每个企业都能按需使用的资源。
词元不是冰冷的运算单元,它是智能经济的「新货币」,是连接技术和商业的「新纽带」。未来的智能经济,不再比谁的模型参数更多,而是比谁的词元用得更高效、更有价值。
词元为尺,丈量智能经济的新刻度。