对抗知识焦虑,从看懂这条开始
App 下载
长视频终于不“失忆”,解耦记忆是关键
WorldPlay模型|OPPO研究院|香港理工大学|记忆解耦|长视频生成|大语言模型|人工智能
对抗知识焦虑,从看懂这条开始
App 下载WorldPlay模型|OPPO研究院|香港理工大学|记忆解耦|长视频生成|大语言模型|人工智能
想象你在玩开放世界游戏:走进木屋摸了摸橡木书架,转身逛了半圈再回来,书架居然变成了金属置物架——这种“鬼打墙”式的场景错乱,曾是AI长视频生成的死穴。过去的模型要么为了记住细节把画面糊成马赛克,要么为了画质彻底“失忆”,每次回头都是全新世界。直到2026年4月,香港理工大学与OPPO研究院的团队用一个看似简单的思路,打破了这道两难的选择题。
传统长视频生成模型的核心矛盾,就像让顶级厨师一边颠锅炒菜,一边心算微积分——两个任务都需要全神贯注,结果必然顾此失彼。比如腾讯AI Lab的WorldPlay、南洋理工的VMem,都把记忆功能硬塞进生成网络的主干里:模型既要根据文本和相机轨迹画出生动画面,又要记住每一个像素的位置,最后要么画面变形失真,要么场景彻底走样。
更糟的是,这种“耦合”设计带来了天文数字的资源消耗:WorldPlay需要32万条视频样本训练,推理时仅记忆模块的计算量就高达3065 TFLOPs,相当于把一台超级电脑的算力都耗在“记东西”上。哪怕喂给模型再多数据,也填不平架构缺陷带来的坑——就像给同时干两份活的厨师塞再多食材,他也没法同时炒出两道完美的菜。
新方案的核心是“解耦”:把生成和记忆彻底分开,让专业的人干专业的事。
研究团队保留了Wan2.1、CogVideoX这些预训练生成模型的全部能力——就像留住了一位能画任何风格的顶级画家,但绝不要求他同时记细节。他们给画家配了一个轻量的“记忆助手”:一个仅占主干参数2.2%的小模块,专门负责记录画家之前画过的场景、物体位置和纹理。
这个助手的聪明之处在于“按需工作”:通过相机感知门控机制,它会计算当前视角和历史视角的重叠度——当你回到之前看过的书架前,助手立刻递上之前的记录;当你走向从未去过的楼梯间,助手就安静待命,让画家自由发挥。
具体来说,助手会同时存储两种记忆:连续时序记忆跟踪物体的运动轨迹,离散空间记忆保留场景的静态细节;再通过逐帧交叉注意力,让当前画面只和最相关的历史细节对齐,既避免了无关信息干扰,又把计算量降到了2.97 TFLOPs——仅为WorldPlay的千分之一。
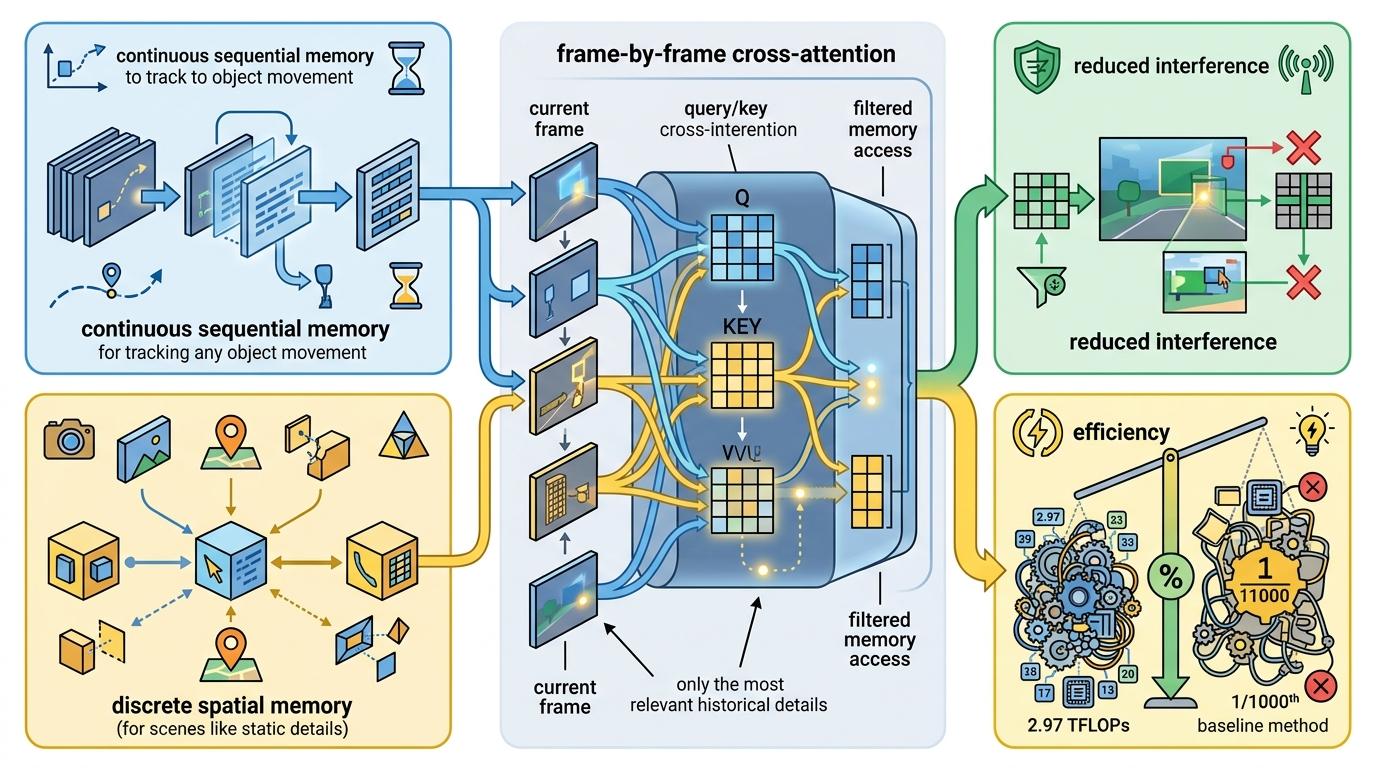
解耦设计带来的意外惊喜,是训练成本的暴跌。
以往的模型需要几十万条标注视频,新方案只需要14K条普通视频——甚至不需要3D渲染或人工标注,只要用简单的“数据增强魔术”:把一段向前走的视频倒过来,模拟“去了又回”的轨迹;再用时间步长策略,让模型参考t时刻的画面生成t+δ时刻的内容,避免它靠“复制粘贴”作弊。
这种“伪循环训练”让模型快速学会了“回访场景要一致,探索新景要自由”的规则。在RealEstate10K数据集的测试中,新模型的PSNR(画面一致性指标)达到21.85,比第二名的WorldPlay高出5.54;哪怕在从未见过的域外图像上测试,它也能精准还原场景细节,没有出现任何结构变形。
当然,它也并非完美:门控机制的阈值目前还需要人工设定,更长序列的视频仍可能出现累积误差,动态物体的长期跟踪也还有优化空间。但不可否认的是,它第一次用极低的成本,实现了“记忆”和“创作”的两全其美。
当我们为AI能画出越来越逼真的画面欢呼时,往往忽略了一个更基础的问题:AI能不能“记住”它画过的东西?这个看似简单的要求,却成了长视频生成领域卡了多年的瓶颈。
香港理工大学与OPPO研究院的方案,没有追求更复杂的模型或更海量的数据,而是回到问题的本质——把“记忆”从“生成”的枷锁里解放出来。这不仅让长视频终于摆脱了“失忆症”,更给所有需要长期记忆的AI任务提了个醒:好的设计,从来不是让一个模块干所有事,而是让每个模块只干对的事。
未来,当我们在元宇宙里自由穿梭,在AI生成的电影里反复回看某个细节时,或许会想起这个“给画家配助手”的简单思路——它看似微小,却推开了一扇通往更连贯、更真实的AI生成世界的门。