对抗知识焦虑,从看懂这条开始
App 下载
国产开源大模型竞速,多模态重构AI应用边界
商品图编辑|稀疏激活|GLM5.1|DeepSeek-V4|京东开源模型|多模态视觉|人工智能
对抗知识焦虑,从看懂这条开始
App 下载商品图编辑|稀疏激活|GLM5.1|DeepSeek-V4|京东开源模型|多模态视觉|人工智能
2026年4月的一个普通工作日,杭州某电商团队的设计师只输入了一句“把这款耳机移到画面中央,调整到正面视角”,AI就自动完成了商品图的精细编辑——不需要复杂的图层操作,也不用重新拍摄。这不是科幻场景,而是京东开源的多模态模型带来的日常。就在同一个月,国内一口气开源了包括DeepSeek-V4、GLM5.1在内的5款重量级大模型,全球开源大模型的下载量占比里,中国模型已经从2024年底的1.2%跃升到了30%。这场看似疯狂的“月度更新”,背后藏着国产AI从追赶到重构规则的关键逻辑。
你可以把传统大模型想象成一个什么都懂的全才,但处理任何任务都要调动全部能力,既浪费算力又慢。而现在主流的稀疏激活MoE架构,更像是一个分工明确的专家团队——比如处理代码任务时只激活编程专家,处理图像时只唤醒视觉专家,平时大部分专家都处于“待命”状态。
以阿里开源的Marco-MoE系列为例,总参数17.3B的模型,实际激活的只有0.86B,相当于用十分之一的算力,实现了接近全参数模型的效果。这种架构的核心是一个“门控网络”,它会像项目主管一样,根据输入内容自动挑选最合适的“专家”组合。
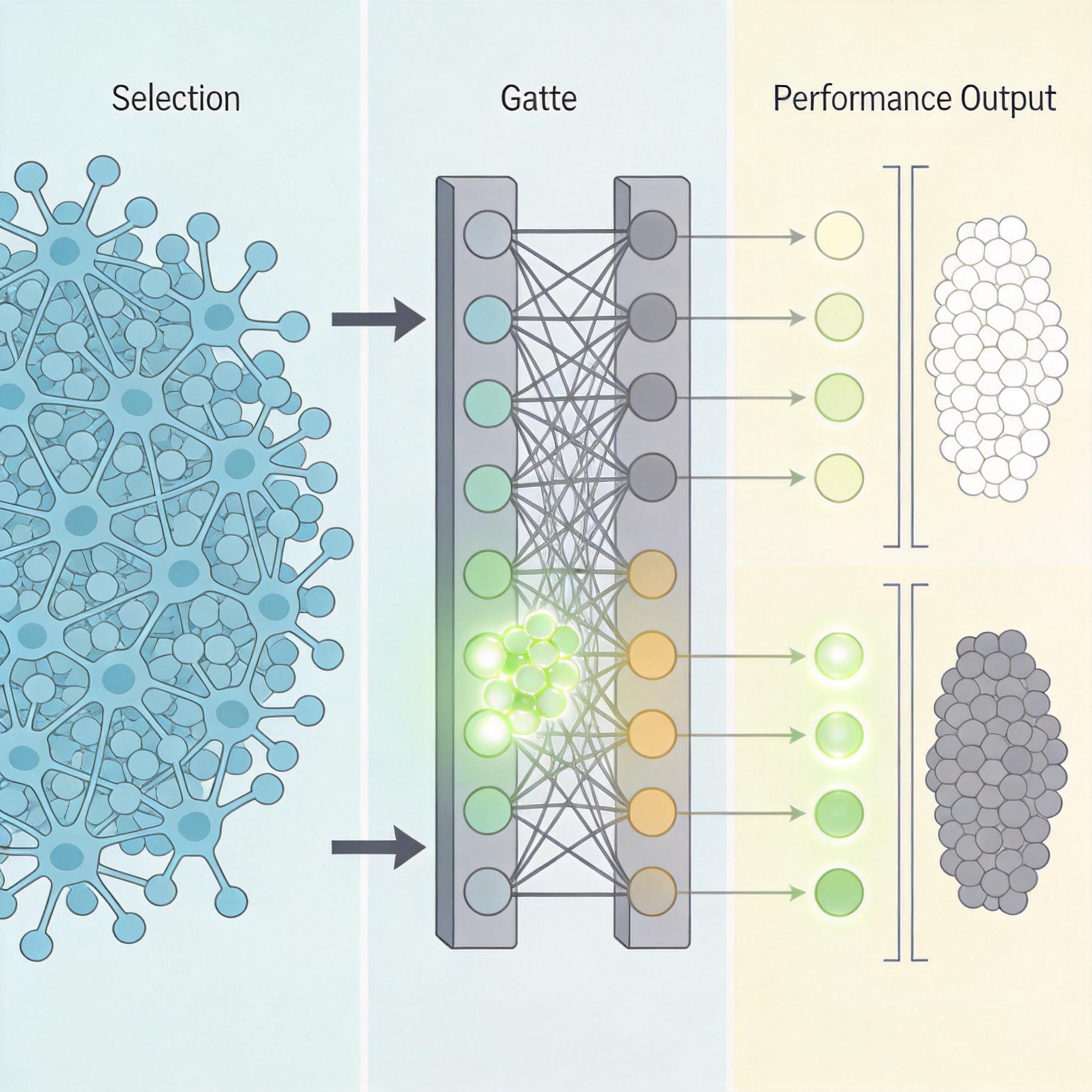
但真实的机制比这更精确:每个专家都是一个独立的神经网络模块,门控网络通过计算输入与各专家的匹配度,分配不同的权重,最终只让权重最高的少数专家参与计算。这不仅把推理成本降低了70%以上,还能通过增加专家数量轻松提升模型规模——DeepSeek-V4的总参数达到1.6T,却依然能在普通GPU上高效运行。
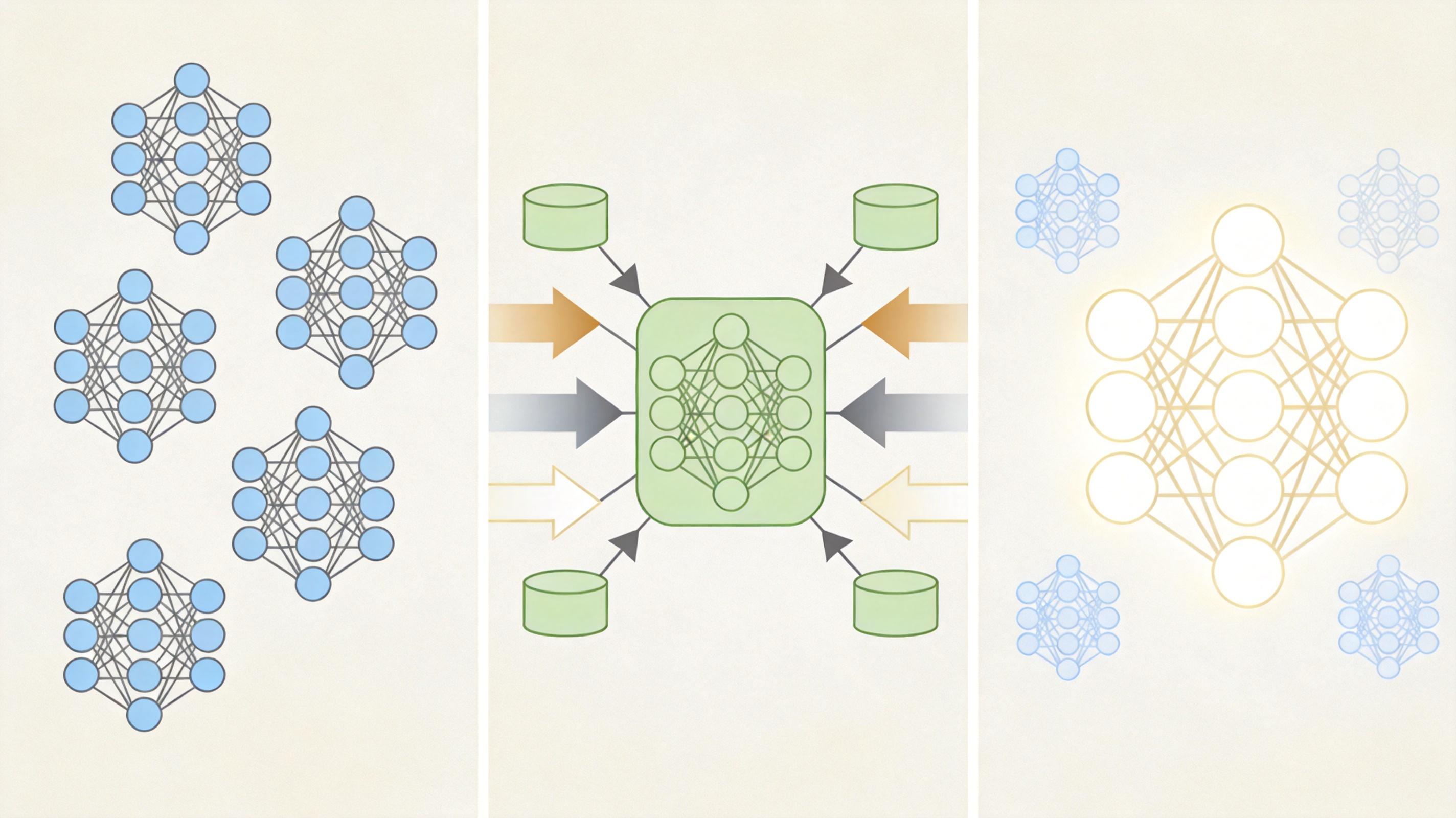
如果说文本大模型是只会听和说的AI,那多模态模型就是能看、能听、能理解复杂场景的“全能选手”——它能把文本、图像、音频甚至3D点云的信息揉在一起,完成过去单一模型做不到的事。
商汤开源的SenseNova-U1模型,直接跳过了传统的视觉编码器,用一个统一架构实现了像素到文字的端到端建模。比如你输入“画一张带数据图表的旅行攻略”,它能同时生成文字攻略和对应的可视化图表,而不是先写文字再单独生成图片。这种“原生统一”的架构,比过去“文本模型+视觉插件”的组合效率提升了40%。
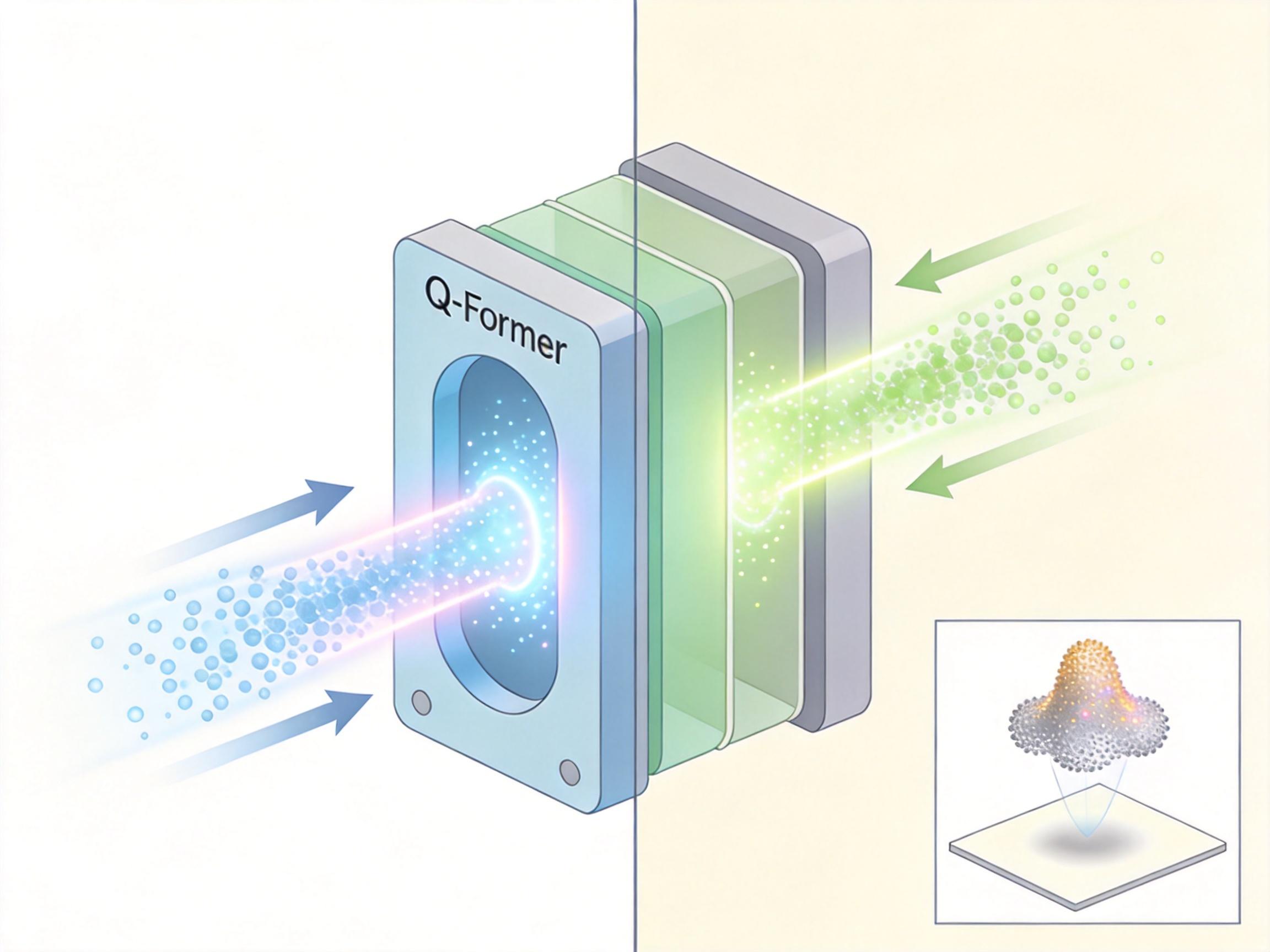
另一个关键突破是跨模态注意力机制,比如Q-Former模块,它就像一个翻译官,能把图像的视觉特征转换成文本模型能理解的“语言”。腾讯的HY-World 2.0模型,就是用这种技术把单张图片转换成了3D高斯点云,实现了从2D图像到3D世界的重建,能直接用于虚拟展厅或游戏场景生成。
不过目前多模态模型还存在局限:比如处理复杂透明物体的图像编辑时,容易出现细节失真;跨语言的多模态任务准确率还不够稳定,这些都是接下来要攻克的难题。
宽松的开源协议正在打破AI技术的垄断。2026年4月开源的模型里,大部分都采用了Apache 2.0或MIT许可,企业可以免费商用、修改甚至再发布,这直接把AI应用的门槛从“百万级投入”拉到了“普通开发者也能玩”。
阿里的Qwen系列模型在Hugging Face上的变体超过10万个,其中很多是中小企业甚至个人开发者基于它微调的行业模型——比如用于法律合同审查的Qwen-Law,用于医疗影像分析的Qwen-Med。这些衍生模型的数量,是国外同类模型的两倍还多。
但开源也带来了新的挑战:比如部分模型的“幻觉”问题会被二次放大,数据隐私和内容合规的责任也变得分散。目前国内已经有团队在开发针对开源模型的安全检测工具,比如能自动识别模型输出中虚假信息的AdaShield,但要建立完善的开源治理体系,还有很长的路要走。
当我们盯着每月更新的模型参数时,其实忽略了更重要的事:这场竞速的终点从来不是“比谁的模型更大”,而是“让AI真正融入每一个普通场景”。从电商设计师的日常工作,到医生手里的影像分析工具,再到开发者电脑上的代码助手,国产开源大模型正在把过去遥不可及的AI能力,变成像水电一样触手可及的基础设施。
开源不是免费的狂欢,而是创新的接力。当越来越多的人能参与到AI的改进中,我们离“让AI服务于人”的目标,才更近了一步。