对抗知识焦虑,从看懂这条开始
App 下载
AI生图终于写对字,背后是26岁中国学者的十年
中国学者团队|AI生成海报|架构重构|多语言文字渲染|GPT Image2|大语言模型|人工智能
对抗知识焦虑,从看懂这条开始
App 下载中国学者团队|AI生成海报|架构重构|多语言文字渲染|GPT Image2|大语言模型|人工智能
你或许见过AI生成的假海报——中文歪歪扭扭,韩文像乱码,孟加拉文干脆成了模糊的色块。但2026年4月发布的GPT Image2彻底解决了这个问题:它能在米粒大小的空间里刻出清晰的中文,能生成中韩孟三语精准对齐的海报,多语言文字渲染准确率超过99%。更关键的是,它不是把文字当图形“画”出来,而是像人写句子一样,一个字符接一个字符“生成”出来。这背后,是一个26岁中国学者带领13人团队完成的架构重构,以及他从编程小白到AI核心研究者的十年跃迁。
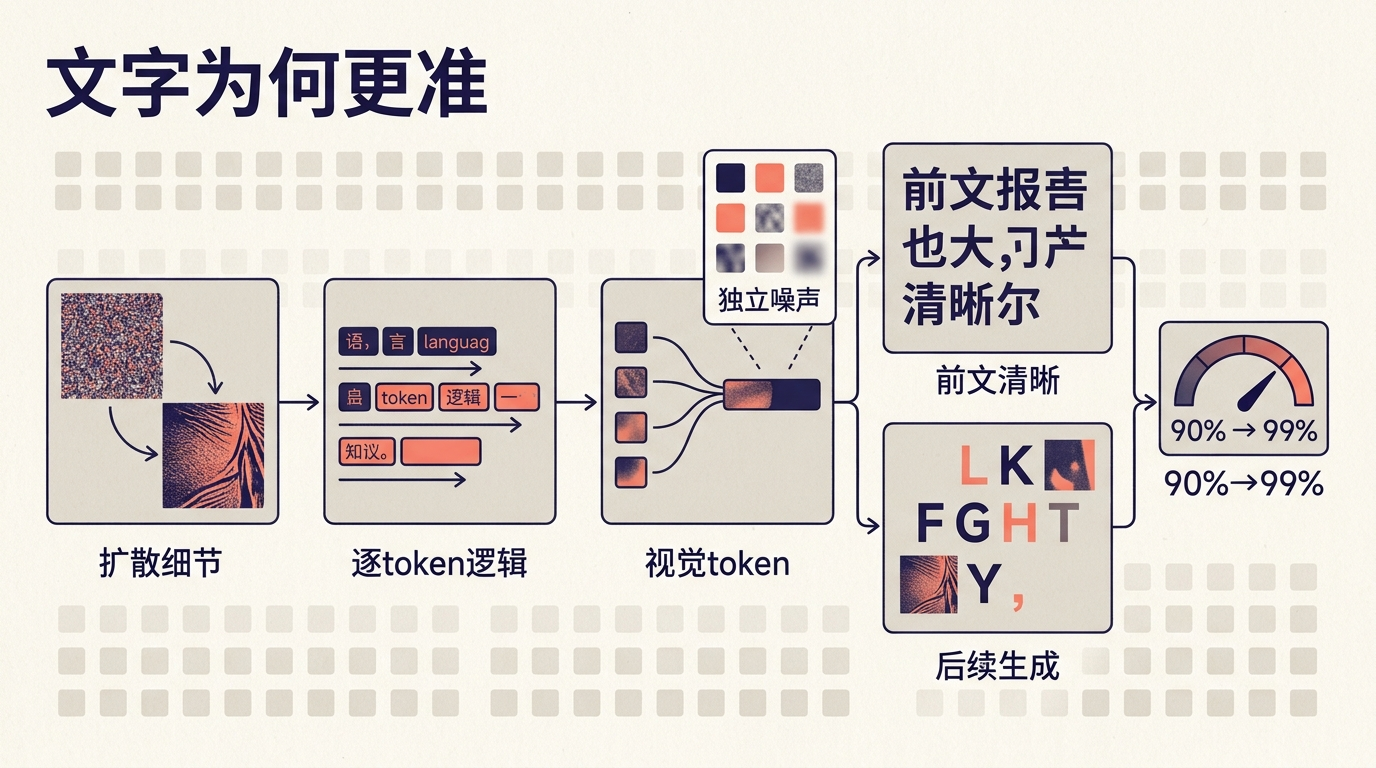
过去的AI生图模型,本质上是在玩“像素拼图游戏”——把文字当成和树叶、云朵一样的视觉元素,用扩散模型从噪声里还原出“看起来像字”的像素块。这种方法的天花板很明显:它不知道自己画的是什么字,只是模仿文字的视觉形状,一旦遇到复杂字体、小尺寸或多语言混排,就容易露馅。
GPT Image2推翻了这个逻辑。它把图像和文字拆成了统一的“视觉token”,用类似大语言模型的自回归方式生成——就像人写文章时,每一个字都要符合上下文逻辑,模型生成每一个视觉token时,也会参考全局的语义和布局。你可以把这个过程想象成:以前的AI是照着字帖描红,现在的AI是先读懂文章意思,再自己把字写出来。
核心的技术支撑,是陈博远在MIT读博时提出的Diffusion Forcing训练范式。简单来说,就是把扩散模型处理视觉细节的能力,和语言模型逐token生成的逻辑能力结合起来:每个视觉token拥有独立的噪声水平,模型在生成时,既保留了前文内容的清晰度,又能根据语义逻辑生成后续的文字和图像元素。这种架构直接把文字渲染的准确率从90%拉到了99%,也让AI第一次真正“理解”了它生成的文字。
26岁的陈博远,是GPT Image2核心研发团队的负责人,也是Sora视频生成团队的成员。很少有人知道,十年前他还是个连Python语法都不懂的高中生。
2016年,16岁的陈博远在江苏省天一中学读高二,因为参加机器人竞赛和科研夏令营,遇到了改变他人生的引路人——Google DeepMind的资深研究员夏斐。在夏斐的引导下,这个连编程都不会的高中生一头扎进了AI世界。之后的十年里,他从天一中学人工智能社社长,到伯克利AI实验室的科研助手,再到MIT的博士,最后加入OpenAI成为核心研究者,只用了十年就走完了别人可能需要二十年的路。
他在MIT的博士论文《Diffusion Forcing》,成了GPT Image2架构的核心理论基础。在OpenAI的13人团队里,他带着一群平均年龄不到30岁的研究者,用十个月时间完成了从GPT Image1.5到GPT Image2的架构重构。发布会后他在知乎自嘲“国内媒体没发现只有我是国人”,这句玩笑的背后,是华人学者在全球AI领域越来越重要的话语权——这支13人团队里,华人超过一半,他们的背后是一张从无锡到伯克利再到MIT的学术传帮带网络。
GPT Image2的文字渲染能力,在一系列极限测试中得到了验证。陈博远在发布前特意做了一张“彩蛋图”:在一幅多层嵌套的漫画里,加入了中韩孟三种语言的文字,还在海报右下角生成了极小的中文——小到几乎需要放大镜才能看清,但每个字都清晰可辨。更惊人的是“米粒刻字”测试:在4K分辨率的图像里,一颗米粒上的文字笔画分明,没有任何模糊或变形。

这些测试不是炫技,而是直接指向了AI生图的应用边界。过去的AI生图只能用来生成艺术插画或概念图,因为文字不准确,无法直接用于广告、UI设计、技术文档等需要精准文字的场景。但GPT Image2的出现,让AI生图第一次真正具备了工业级应用的能力:广告公司可以直接用它生成多语言海报,设计师可以用它生成精准的UI原型,甚至可以生成带有复杂公式和文字的科学图表。
当然,它也不是完美的。在处理超长文本、手写体或三维透视文字时,它的准确率还是会下降;生成极高分辨率图像时,速度和成本的权衡依然存在。但这些问题,已经是技术优化的范畴,而非底层逻辑的缺陷。
GPT Image2的意义,不止于AI终于能写对字了。它标志着AI生图从“视觉模拟”进入了“语义理解”的新阶段——以前的AI是用眼睛看世界,现在的AI是用脑子理解世界。
这也是陈博远一直强调的“世界模型”理念:AI不应该只是生成像素,更应该理解像素背后的语义、逻辑和物理规律。这种理念,正在推动AI从“狭义工具”向“通用智能”靠近。
看懂世界,才能写好世界的语言。 当AI开始理解它所生成的内容时,我们离真正的通用人工智能,又近了一步。