对抗知识焦虑,从看懂这条开始
App 下载
给失败找方向,复杂系统的生存逻辑
有方向感的失败|高风险场景|系统失效设计|AI视频喉镜|临床诊疗技术|AI产业应用|医学健康|人工智能
对抗知识焦虑,从看懂这条开始
App 下载有方向感的失败|高风险场景|系统失效设计|AI视频喉镜|临床诊疗技术|AI产业应用|医学健康|人工智能
2024年一台AI视频喉镜在急诊室突然黑屏——屏幕上本该显示的患者声门影像瞬间消失,负责插管的医生却没有丝毫停顿,顺手就把喉镜当成普通工具塞进患者喉咙,精准完成了操作。这不是医生的应急反应有多快,而是这台机器从设计之初,就规划好了自己该怎么‘失败’。
你或许会觉得奇怪:产品设计难道不是要追求‘永不失效’?但在医疗、航空、金融这些高风险领域,‘不失败’早已被证明是不可能的目标。真正的难题从来不是避免失败,而是让失败按预期的方向发生。这背后,是一套被称为‘有方向感的失败’的系统设计逻辑。
复杂系统的失败不是随机崩塌,而是可以被设计的——工程师们用三条轴线,给失败划定了清晰的边界。
第一条轴线是「向目标失败」:系统失效时,会主动退到预设的次优稳定点,保证核心任务不中断。比如人机协作团队里,AI模块会被设计成‘先失效’的角色,一旦出现异常,控制权会自动交还给人类,就像那台视频喉镜,即使AI功能全失,也能变回普通工具继续完成插管。
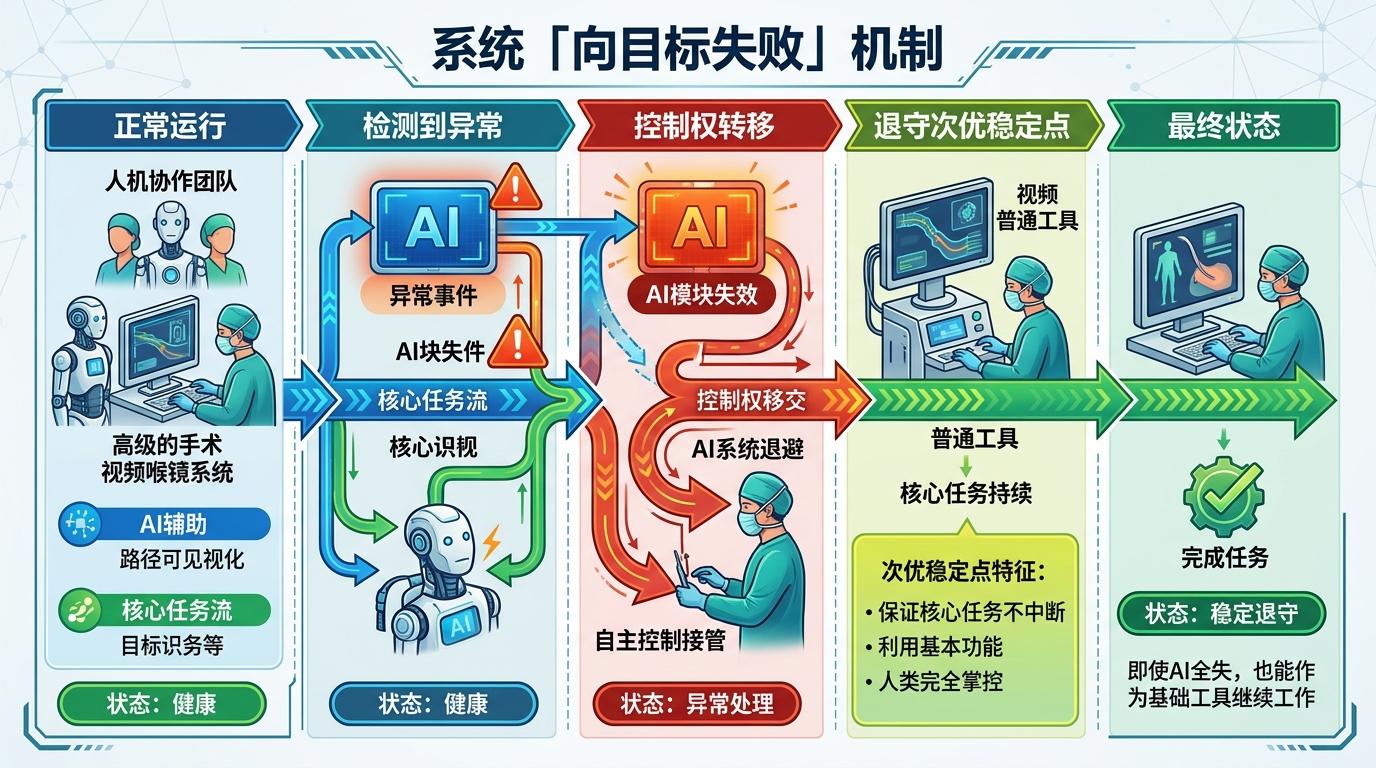
第二条轴线是「远离风险失败」:当系统识别到致命风险时,会主动朝着远离危险的方向‘崩溃’。飞机降落时如果偏离跑道,绝不会强行落地,而是立刻拉起复飞;化工车间的压力阀超过阈值,会直接向安全区域泄压——这不是逃避,是用主动失效避免灾难。
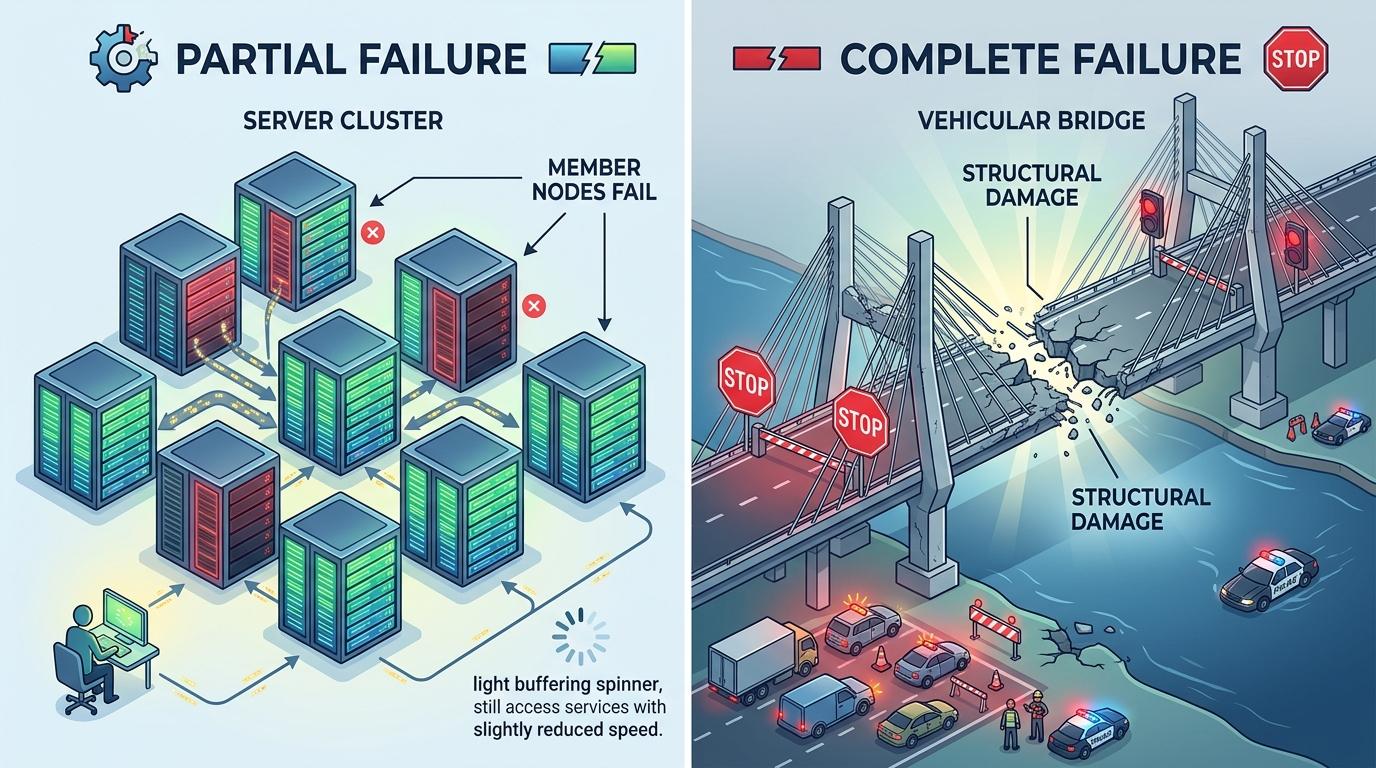
第三条轴线是「部分与完全失败」:系统会根据失效程度,选择是降级运行还是彻底停机。服务器集群某个节点故障,其他节点会自动接管负载,用户只会感觉到轻微卡顿;而如果桥梁在地震中出现结构性损伤,会被直接封闭,绝不允许任何车辆通行——前者是‘部分失效’的优雅降级,后者是‘完全失效’的安全兜底。
这种‘给失败找方向’的思路,其实早有源头。两千年前的斯多葛哲学家塞涅卡提出‘预先思考坏事’——提前设想所有可能的不幸,才能在灾难来临时保持冷静。这套哲学思想,如今被工程师们转化成了一套可操作的工具:FMEA,也就是失效模式与影响分析。
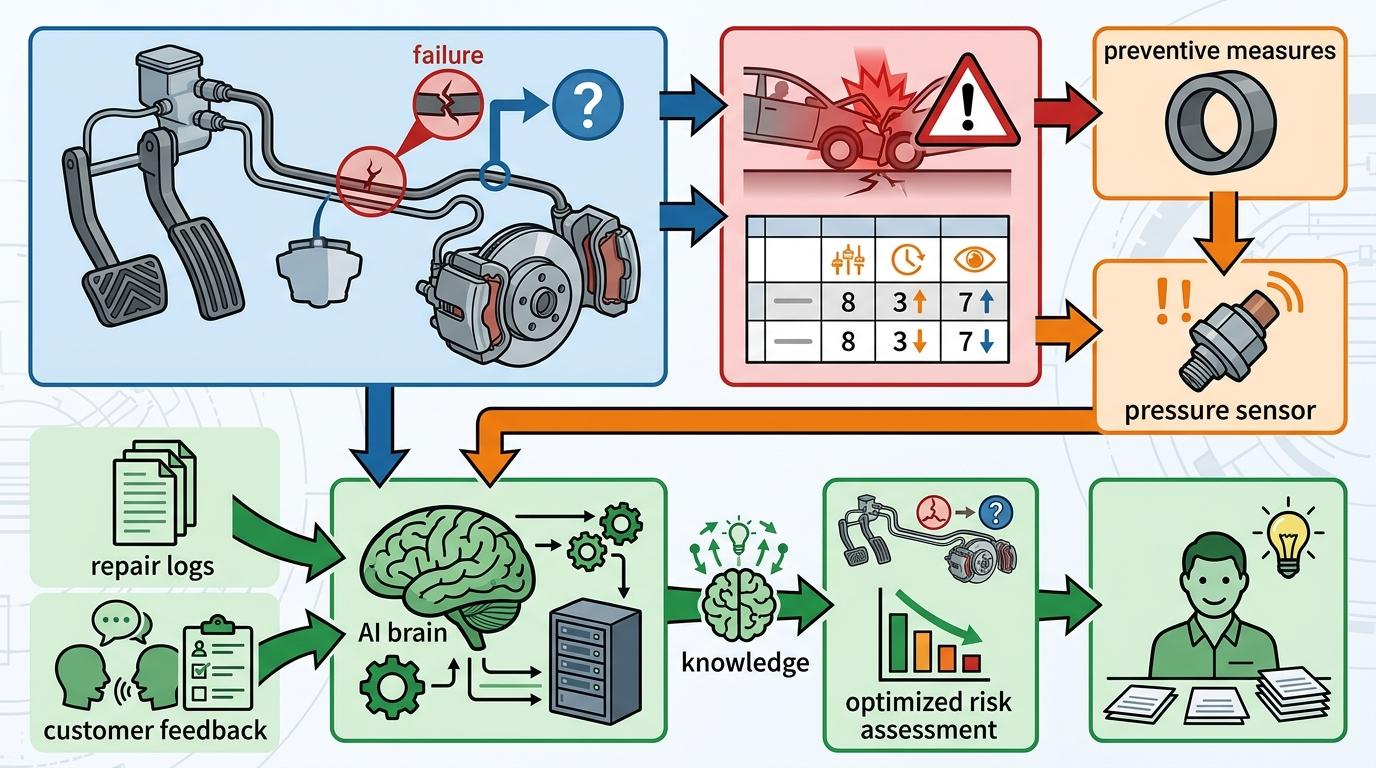
FMEA最早诞生于1949年的美国军方,后来被NASA用于阿波罗计划,现在已经成为汽车、航空、医疗等行业的标准流程。它的核心逻辑很简单:组建跨职能团队,把系统拆解成最小单元,逐个分析每个部件可能的失效模式、会造成的影响,以及如何提前预防或应对。
比如汽车厂商设计刹车系统时,会用FMEA分析:如果刹车油管破裂,会导致什么后果?发生概率有多大?能不能通过增加油管厚度、安装压力传感器来提前预警?每一个潜在的失效点,都对应着一套预设的应对方案。现在,AI技术正在让FMEA变得更高效——大语言模型可以从海量的维修日志、客户反馈里自动提取潜在失效模式,机器学习算法能更精准地评估风险等级,把工程师从繁琐的人工分析里解放出来。
不过FMEA也有局限:它依赖于人类的经验和认知,对于AI系统这种‘黑箱’式的复杂存在,还很难完全覆盖所有潜在的失效模式。这也是为什么‘有方向感的失败’不能只靠技术,还要依赖人机之间的信任和协作。
在人机协作系统里,最容易被忽视的风险不是技术故障,而是信任失衡——人类要么过度依赖AI,把它当成不会出错的‘神’;要么过度怀疑,完全无视它的价值。这两种情况,都会让‘有方向感的失败’设计彻底失效。
2024年的一项研究显示,当AI给出错误的医疗诊断时,经验不足的医生会有超过60%的概率直接采纳,而经验丰富的医生,采纳率只有20%。不是因为后者更不信任AI,而是他们建立了更准确的‘共享心理模型’——清楚知道AI的能力边界,也知道该在什么时候介入。
现在,工程师们正在用动态信任校准技术解决这个问题:通过‘情境多臂老虎机’算法,系统会根据具体任务场景,动态调整AI的权限——当AI置信度高时,自动执行决策;当置信度中等时,提示人类确认;当置信度低时,直接请求人类介入。在医疗诊断、司法风险评估等领域的测试显示,这种动态校准能让人机协作的决策准确率提升10%-38%。
当然,信任校准不是单向的,AI也需要‘理解’人类的意图。比如当人类发出明显错误的指令时,AI应该具备‘智能不服从’的能力——就像导盲犬会拒绝主人过马路的指令一样,在判断到风险时,主动拒绝执行错误指令,这也是‘有方向感的失败’的一部分。
我们总习惯把‘失败’当成反义词,追求‘零故障’‘零误差’,但在复杂系统的世界里,失败是必然的,也是必要的——它不是终点,而是系统自我修复、持续进化的起点。
给失败找方向,本质上是给系统留出生存的弹性。就像急诊室里那台黑屏的喉镜,它的‘失败’不是设计缺陷,而是设计本身——用主动的失效,换来了核心任务的完成;用可控的崩溃,避免了不可挽回的灾难。
失败不可避免,但可以被引导。 这句话适用于每一个复杂系统,也适用于我们面对不确定性的人生:与其害怕失败,不如提前给它找好方向。