对抗知识焦虑,从看懂这条开始
App 下载
小模型靠它比肩GPT-4o,还省40%Token
模型兼容性|Token消耗|AI技能插件|上海交大团队|SkVM虚拟机|大语言模型|人工智能
对抗知识焦虑,从看懂这条开始
App 下载模型兼容性|Token消耗|AI技能插件|上海交大团队|SkVM虚拟机|大语言模型|人工智能
想象一下:你花大价钱买的顶级大模型,处理起复杂任务还不如一个装了「外挂」的小模型——而且这个「外挂」能让你少花近一半的Token钱,速度还能飙到原来的50倍。这不是科幻,是上海交大团队刚拿出的SkVM:一个专门给AI技能「做翻译」的虚拟机。它解决了一个让所有AI开发者头疼的问题:同一个技能,换个模型就失灵,甚至越用越慢、越用越贵。为什么小模型装上它能逆袭?这得从AI技能的「水土不服」说起。
你可以把AI技能(Skill)理解成给大模型用的「插件」——比如让它写代码、做数据分析、自动处理邮件的预设流程。但现在的问题是,这些「插件」就像只适配特定手机的APP:在GPT-4上跑得顺风顺水,换到30亿参数的小模型上就直接罢工;就算能用,也可能让Token消耗暴涨451%,任务成功率却纹丝不动。
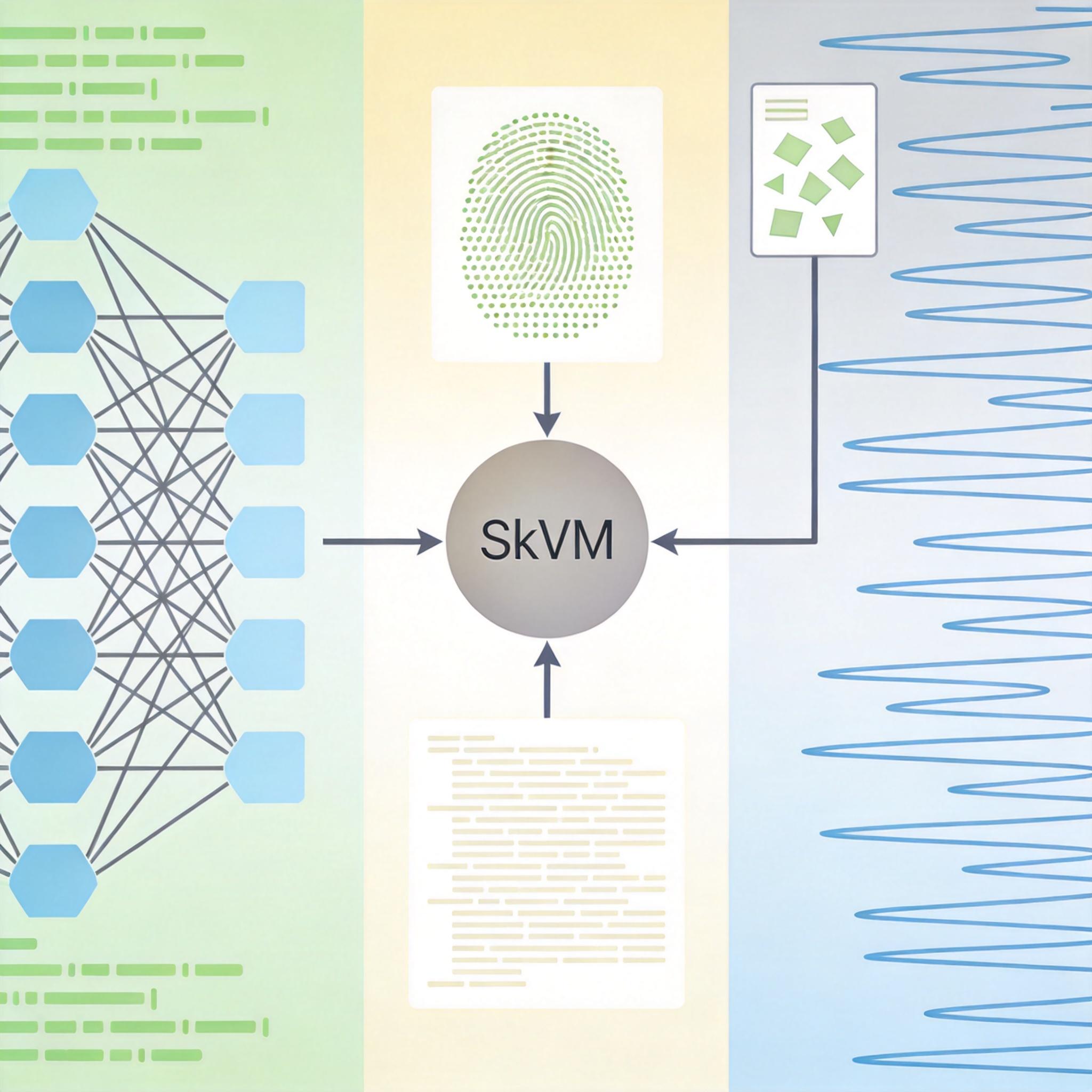
上海交大的团队翻遍了11.8万个技能后,得出了一组扎心的数据:15%的任务用了技能反而更差,87%的任务至少在一个模型上毫无提升。核心原因藏在「语义鸿沟」里——技能是用自然语言写的「软代码」,但不同模型的理解能力、运行环境就像不同品牌的「异构处理器」,有的能看懂复杂指令,有的连相对路径都解析不了。
更麻烦的是环境依赖:技能里要求用某个Python包,你的电脑没装,大模型就会反复试错,把Token像废纸一样烧掉。这就像你给厨师递了一份食谱,却没告诉他厨房里没有盐——他只能一次次出来问你,菜当然炒不好。
SkVM的思路,是给AI技能建一个像Java虚拟机(JVM)一样的「翻译层」——技能是「源代码」,不同模型是「异构处理器」,虚拟机负责把代码翻译成每个处理器都能看懂的指令,实现「一次编写,处处高效运行」。
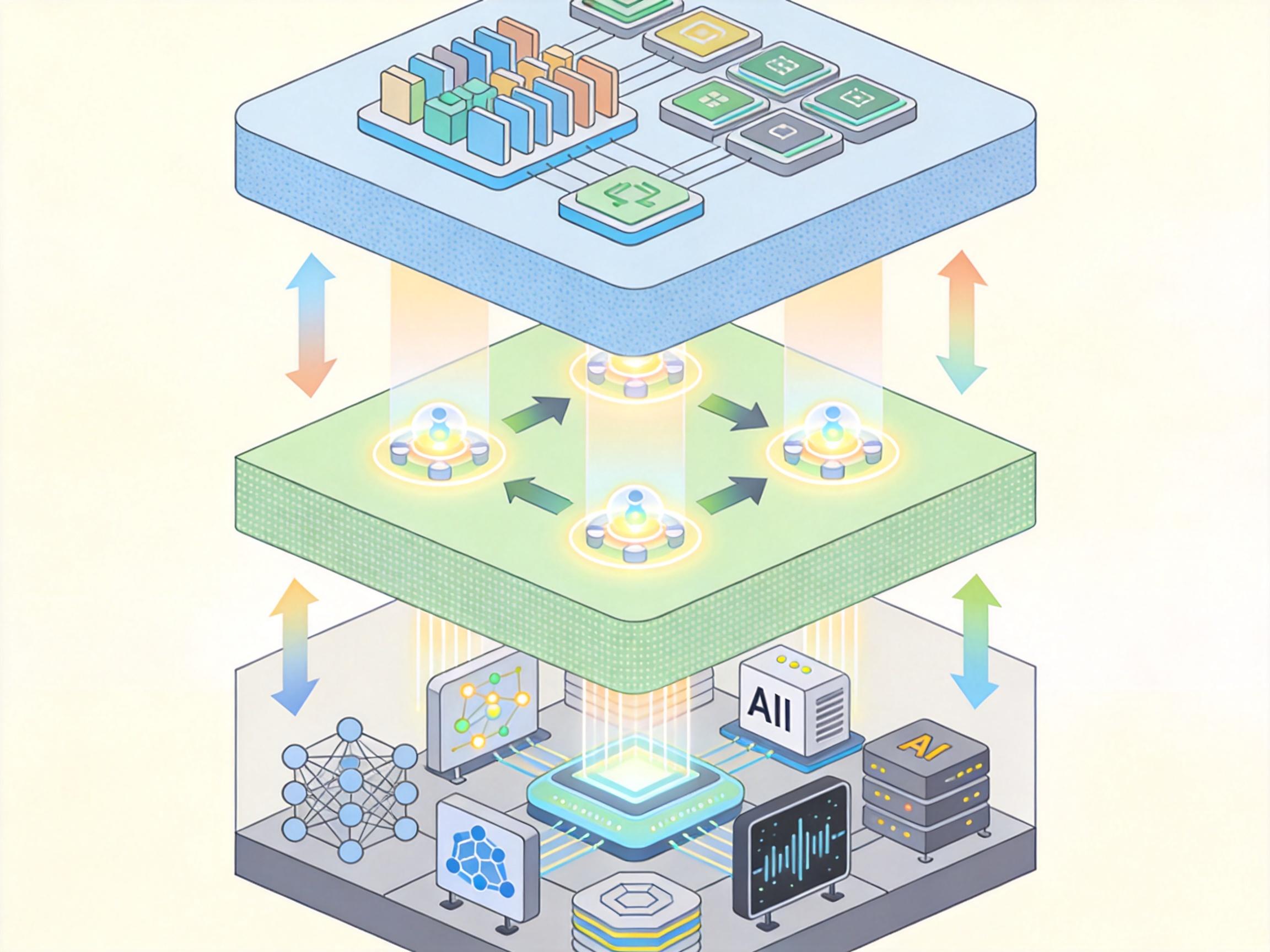
它的核心是两步:先「摸底」,再「适配」。
第一步是**AOT预编译**——在安装技能时,先给你的大模型做个「能力跑分」:团队提炼了26种「原子能力」,比如工具调用、指令遵循、格式对齐,像测CPU性能一样给模型的每个能力打分,生成一份精确的「能力画像」。接着分析技能需要哪些能力,如果模型的能力不够,就自动修改技能:比如把相对路径改成绝对路径,降低对模型「脚本解析」能力的要求;自动提取技能需要的Python包,生成一键安装脚本,让大模型不用再反复试错。
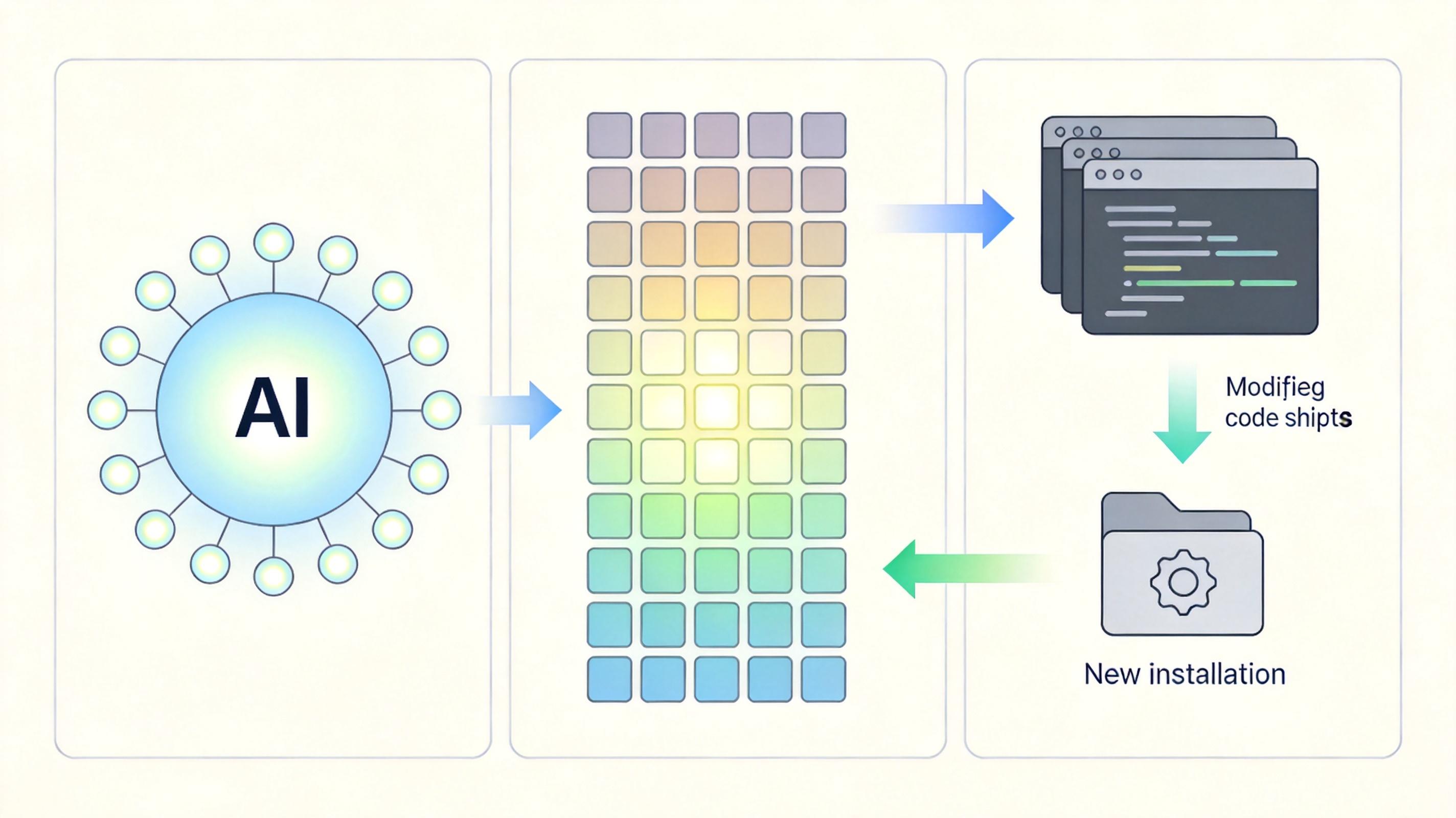
第二步是JIT运行时优化——就像老师根据学生的实时表现调整教学方法。比如技能里的代码模板每次运行都要让大模型重新生成,SkVM会记住这个模板的「指纹」,连续匹配成功几次后,就直接固化成可执行代码,下次运行直接调用,不用再麻烦大模型,这一下就能让速度提升19到50倍。如果运行中出了错,它还会自动收集错误日志,重新优化技能,避免再犯同样的错。
说个直观的对比:30亿参数的小模型Qwen,装上SkVM后,任务完成率能比肩顶级模型Opus4.6,Token消耗还能少40%。
SkVM的意义,不止是让小模型逆袭,更在于它给AI技能建立了一套「工业化标准」。在此之前,AI技能就像手工作坊里的零件——每个都要单独适配模型,成本高、效率低;有了SkVM,技能就成了标准化的工业零件,能在任何「机器」上高效运转。
当然,它也不是完美的。比如现在的26种「原子能力」虽然覆盖了95%的技能,但面对一些极其复杂的技能,还没法完全自动分解;预编译的过程需要20分钟左右,适合反复使用的技能,单次快速执行的场景还有优化空间;而且大模型本身的「非确定性」——同样的输入可能输出不同结果,偶尔还是会让SkVM的优化打折扣。
但不可否认的是,它给AI技能的生态打开了新的可能性:未来开发者不用再为每个模型单独写技能,小模型也能用上复杂技能,AI应用的开发成本会更低,效率会更高。就像当年Java虚拟机让跨平台编程成为现实,SkVM可能会让AI技能的「一次编写,处处可用」从口号变成现实。
当我们还在比拼大模型的参数规模时,SkVM把注意力拉回了「效率」这个更本质的问题上——让小模型发挥大作用,让每一个Token都花在刀刃上。这可能是AI从「炫技」走向「实用」的关键一步:不是追求更大的模型,而是让现有的模型能力得到更充分的利用。
好的AI,不是参数最大的那个,而是适配最好的那个。未来的AI生态,或许会像现在的软件生态一样:虚拟机成为底层基础设施,标准化的技能像APP一样被灵活调用,而开发者的重心,会从「训练模型」转向「用好模型」。