对抗知识焦虑,从看懂这条开始
App 下载
20亿参数小模型,干赢了百亿级大模型
视觉语言理解|机械臂操作|空间感知基准测试|20亿参数小模型|多模态视觉|人工智能
对抗知识焦虑,从看懂这条开始
App 下载视觉语言理解|机械臂操作|空间感知基准测试|20亿参数小模型|多模态视觉|人工智能
当你对着家里的机器人说“把沙发底下左边的拖鞋拿过来”,它能精准完成的概率有多大?过去,要实现这种兼顾空间理解、物体识别和动作规划的复杂任务,得靠百亿参数的大模型撑着,还得连在云端服务器上。但最近,一支国内团队拿出了让人意外的成果:一个只有20亿激活参数的小模型,在22项空间感知、具身操作的基准测试里,16项跑赢了同尺寸竞品,甚至在真实机械臂的精密插件任务里,成功率冲到了95%。它是怎么把大模型的“聪明劲”,压缩进这么小的身躯里的?
你可以把传统的多模态AI想象成一个“一心二用”的人:既要处理视觉信息,又要理解语言指令,两套任务抢着用同一组“思考资源”,结果往往顾此失彼——要么看东西不够细,要么说话逻辑乱。
这个团队的解决思路很直接:给视觉和语言各配一套独立的“思考模块”,也就是Mixture-of-Transformers(MoT)架构。简单说,就是把AI里负责核心计算的关键参数复制一份,原始的专门处理语言,复制的专门处理视觉。
但真实的机制比这更精确:视觉分支用双向注意力,像人看图片时会上下左右扫视全局,专门强化对空间结构和细节的捕捉;语言分支保持单向注意力,专注处理指令的逻辑链。同时,每张图像的信息后面会加一个“视觉潜在令牌”,相当于给图像写了个浓缩摘要,让语言模块能快速抓住视觉信息的核心,不用在海量像素里瞎找。
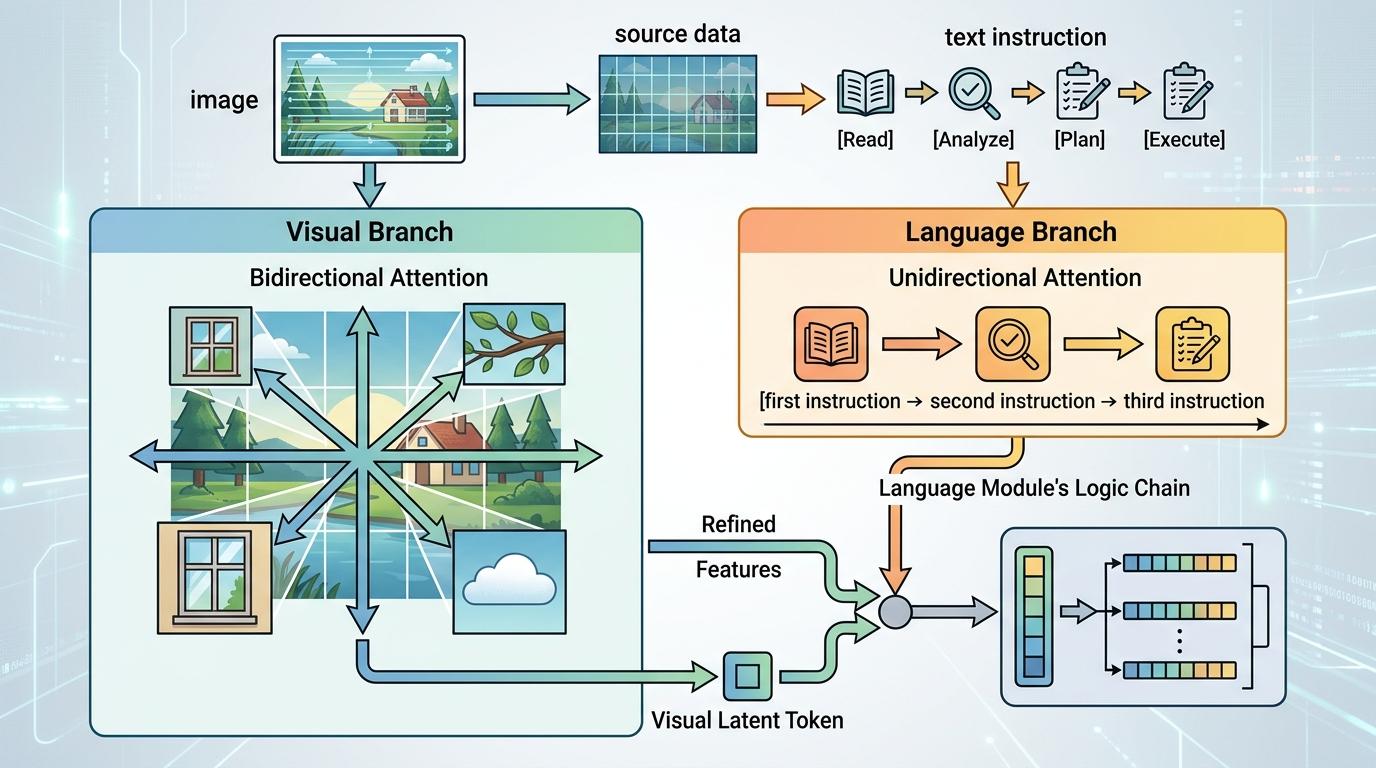
这个设计的妙处在于,没怎么增加计算负担,却给视觉任务多腾出了一倍的“脑容量”。测试显示,这个小模型的视觉感知能力,直接对标了总参数翻倍的传统模型。
光有硬件架构还不够,小模型怎么能拥有大模型的“聪明劲”?这里的关键是“策略上蒸馏”——和传统的“抄答案”式蒸馏完全不同。
你可以把传统蒸馏理解成:让小模型(学生)直接背大模型(老师)给出的最终答案,比如“沙发底下左边”。但这种方法学不到老师的思考过程,遇到没见过的场景就容易懵。
而策略上蒸馏,是让学生模仿老师的整个解题思路:老师会把“找拖鞋”的思考过程拆成几步——先定位沙发,再判断“左边”的方位,然后识别拖鞋的形状,最后规划抓取路径。学生要学的不是最终的“左边”两个字,而是老师怎么一步步推理出这个结论的。
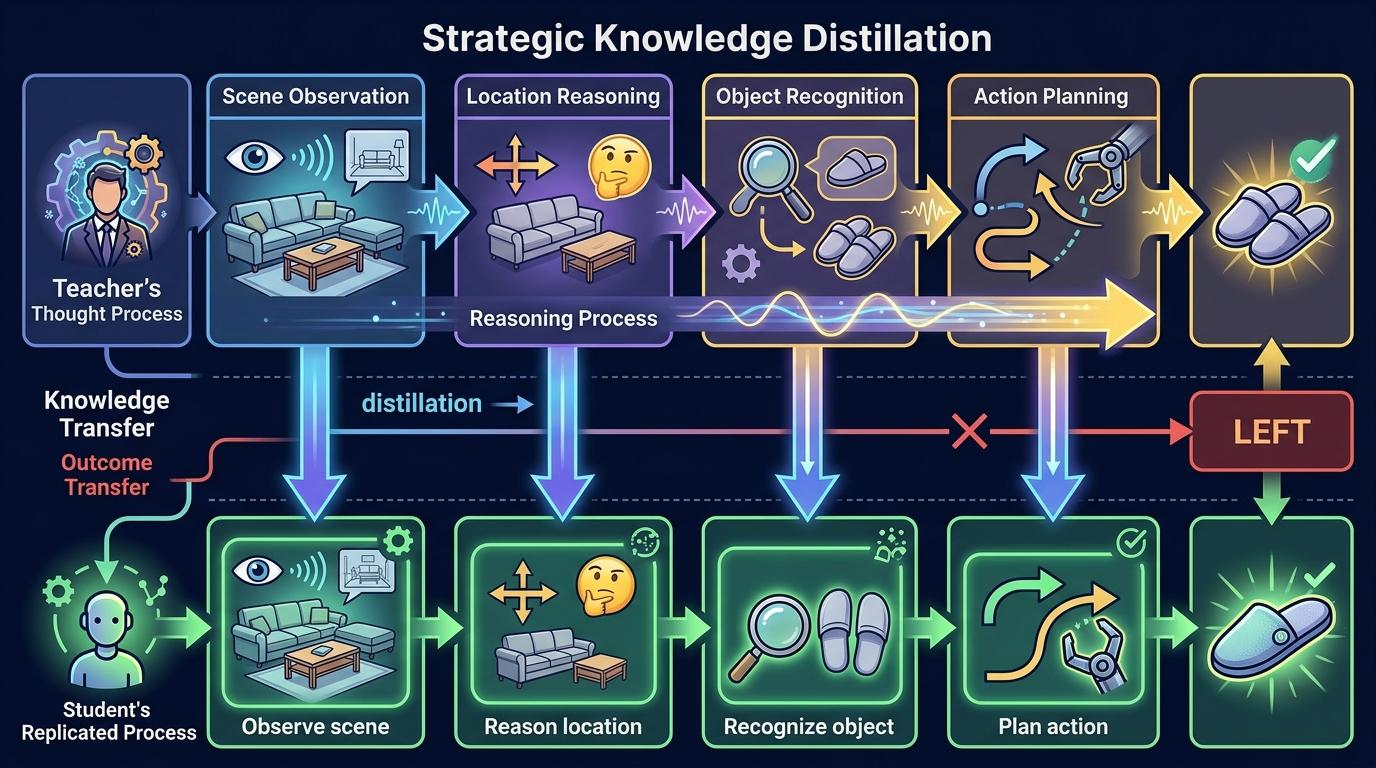
具体操作起来,就是让大模型在推理时生成完整的思考链,小模型学习这个动态的决策分布,而不是静态的答案。比如大模型会考虑“沙发会不会挡住拖鞋?光线暗的地方怎么识别?”这些中间问题,小模型也要跟着学会权衡这些变量。
这种方法的效率极高:在数学推理任务中,用传统蒸馏要练40万条样本才能达到60%准确率,而策略上蒸馏只用7.7万条样本,准确率就冲到了70%,计算成本还不到前者的十分之一。
当然,这个小模型的能力还没到能直接当家庭管家的地步。在受控的实验室环境里它表现亮眼,但真实世界的复杂程度远超基准测试:光线突然变暗、拖鞋被杂物挡住、沙发被挪动了位置……这些“意外”都会给它带来挑战。
比如在户外场景测试中,传感器容易被雨雾干扰,地面的小水坑可能被当成障碍物;长时间运行后,机械臂的微小磨损会影响抓取精度;更关键的是,它还缺乏对物理世界的“常识”——比如知道拖鞋是软的,不能用太大力抓,知道沙发是重的,不能随便推。
而且,它的训练数据里虽然有1亿条样本,但大多是结构化的实验室数据,真实家庭里的“长尾场景”还是覆盖不足。比如“把餐桌上的半杯水拿到茶几上”,它得先判断哪杯水是“半满”的,还要考虑怎么拿才不会洒,这些细节还需要更多真实场景的训练。

从云端的百亿大模型,到边缘设备上的20亿小模型,这次突破的意义,不止是刷了几个测试榜单。它第一次让我们看到,大模型的智能不一定非要靠“堆参数”才能落地,通过架构创新和高效的知识迁移,小模型也能拥有处理复杂物理任务的能力。
更值得关注的是,这给具身智能的产业化落地打开了一扇门——以后家里的机器人、工厂里的机械臂,不用再依赖昂贵的云端服务器,靠自身的小模型就能完成大部分任务,延迟更低,隐私性也更好。
智能的本质不是参数多少,而是能否解决真实问题。当AI终于能从“纸上谈兵”的数字世界,走进充满烟火气的物理空间,我们离真正的“智能生活”,又近了一步。