对抗知识焦虑,从看懂这条开始
App 下载
给AI装技能包,解决云服务的两大死穴
开发者自动化|推理准确率|token账单|云API适配|智能体技能包|AI智能体|人工智能
对抗知识焦虑,从看懂这条开始
App 下载开发者自动化|推理准确率|token账单|云API适配|智能体技能包|AI智能体|人工智能
一位云服务开发者算了笔账:他维护的智能体项目里,光适配云API的工具函数就写了700多行,每周要花12小时调试参数、更新文档。更糟的是,为了让AI掌握最新的云服务规则,他不得不把1.5万个token的文档塞进模型上下文——结果AI的推理准确率掉了30%,每月的token账单翻了两番。这不是个例:当开发者们忙着用智能体接管云服务自动化时,两个死穴正卡住技术落地的喉咙:要么AI知识过时,要么被冗余信息冲得宕机。直到一种叫「智能体技能包」的方案出现,才给这个死局撕开了口子。
先得搞懂开发者们在跟什么较劲。当你让AI智能体去操作云服务——比如用BigQuery查数据、用Firebase部署应用——它得先掌握两件事:一是云API的调用规则,二是服务的最新功能。过去的解法分两路:要么让开发者写死工具函数,要么用MCP服务器实时拉取文档。
MCP,也就是模型上下文协议,本质是给AI接了个实时知识水龙头——需要什么信息,就从官方文档库里抽。但这个水龙头没装阀门:为了保证AI「懂」,开发者往往把整段文档塞进模型的上下文窗口,直接触发了「上下文膨胀」。你可以把模型的上下文窗口想象成一张办公桌:堆满无关文件时,别说找东西,连笔都插不下。有团队测试发现,当上下文超过1万个token,模型对核心指令的关注度会下降40%,甚至会把API参数搞混,把删除数据的指令发给了备份服务。
而写死工具函数的路更糟:云服务API平均每3个月就会更新一次,每次更新都要重写适配代码。这就像你给每个新出的手机型号都重新做个充电器,不仅重复劳动,还会积累一堆「技术债」——哪天你离职了,接手的人得对着几百行过时代码崩溃。
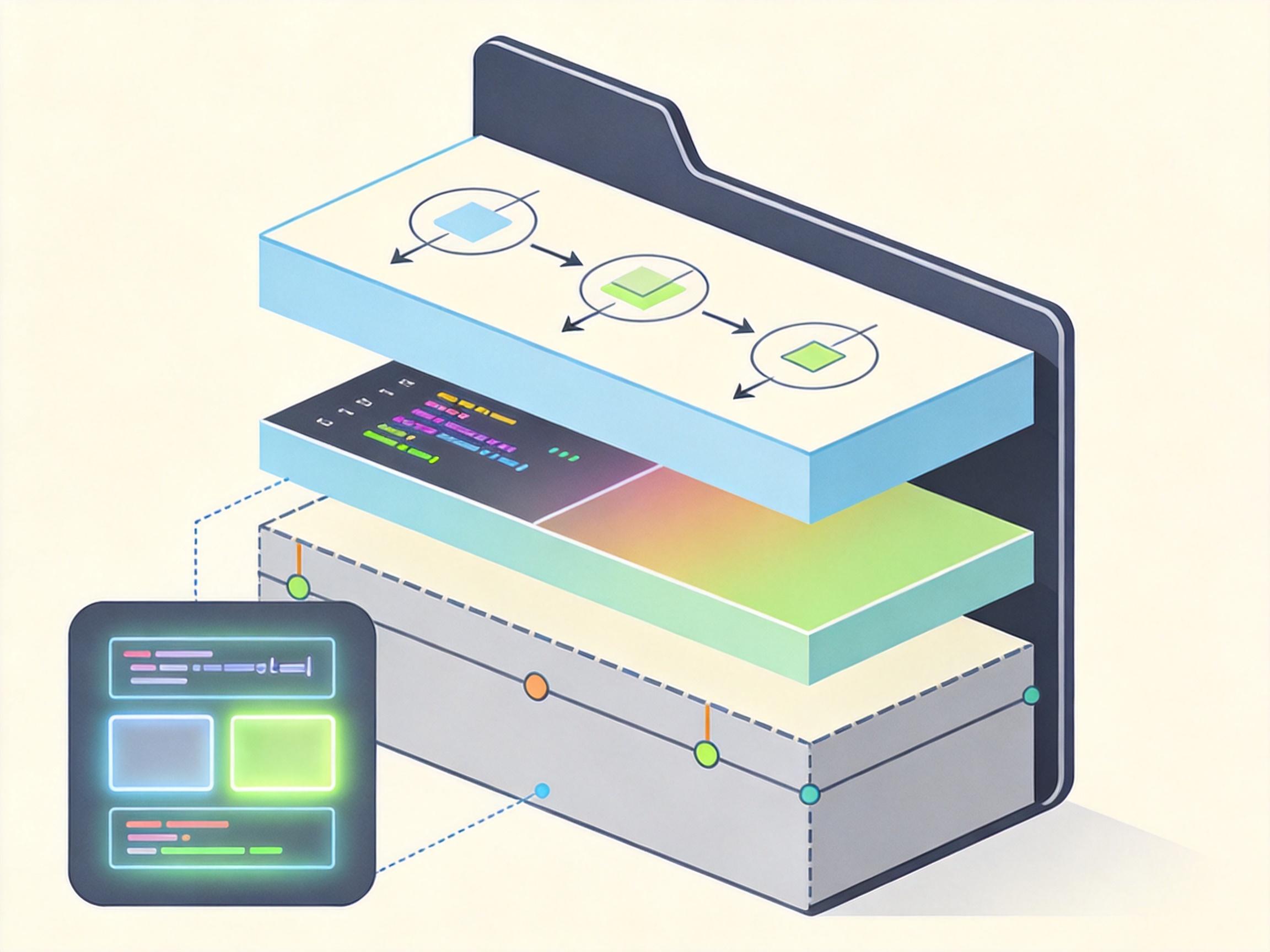
智能体技能包的出现,相当于给AI的大脑装了个模块化抽屉柜。
它的核心逻辑是「渐进式披露」:AI启动时只加载所有技能的元数据——比如「这是BigQuery查询技能」「这是Firebase部署技能」,只有当任务触发时,才打开对应抽屉,取出详细操作指南。你可以把它理解成餐厅的菜单:先看菜名决定点什么,而不是把整本菜谱背下来再吃饭。
每个技能包都是一个Markdown格式的文件夹,里面装着操作步骤、代码示例和边界规则。比如BigQuery技能包会明确写:「查询时必须指定项目ID,禁止调用删除表的API」,还附带经过验证的Python代码片段。更关键的是,这些技能包由官方维护——云API更新了,技能包自动同步,开发者不用再手动改一行代码。
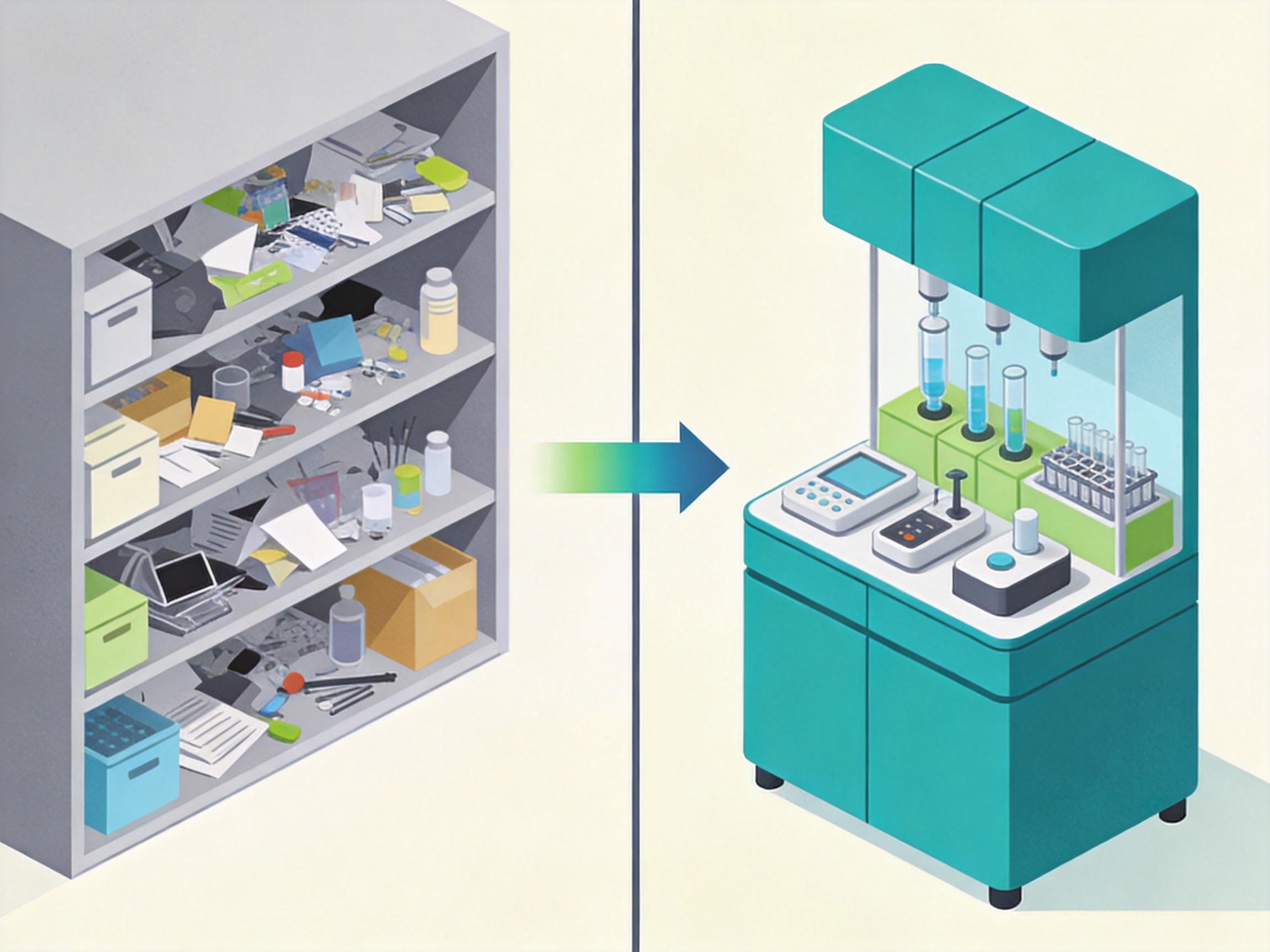
有了技能包,之前需要写700行的工具函数,现在只需要3行代码调用技能模块;上下文里的冗余信息被砍掉了90%,模型的推理准确率回升了27%,token成本直接降了60%。这不是小修小补,是把AI从「什么都装但什么都做不好」的杂货铺,变成了「专精领域随用随取」的专业工作室。
有意思的是,谷歌同时推出了两套技能体系:官方仓库的云服务技能,和AI主管Addy Osmani开源的工程规范技能。
官方技能包解决的是「怎么做对」的问题——比如怎么正确调用BigQuery的API,怎么配置Firebase的安全规则。而Osmani的开源技能包解决的是「怎么做好」的问题——它把谷歌资深工程师的工作流拆成了20个技能:从写代码前先做需求分析,到上线前必须跑安全审计,甚至连代码评审的标准都编码成了技能。当AI要写一段云服务代码时,它会先调用「需求定义技能」明确目标,再调用「BigQuery技能」生成代码,最后用「代码评审技能」自查漏洞——相当于把一个资深工程师的完整工作流程,塞进了AI的大脑。
这种「技术知识+工程纪律」的双重技能组合,让AI从「会干活」变成了「会按专业标准干活」。有企业测试发现,用了双技能体系后,AI生成的云服务代码,需要人工修改的比例从42%降到了8%,部署后的故障发生率直接降了70%。
当我们谈论AI智能体的未来时,很多人会聚焦模型的参数大小、推理速度,但智能体技能包的出现,给了我们另一个视角:真正让AI落地的,从来不是「更强大的大脑」,而是「更有序的知识管理」。
它本质上是把人类的专业经验,拆解成了机器能读懂的模块化指令——既解决了知识过时的问题,又给上下文膨胀踩了刹车。未来的智能体,不会是一个塞满知识的巨型仓库,而是一个能按需取货、遵守规则的高效工坊。
智能体的未来,在技能,不在参数。