对抗知识焦虑,从看懂这条开始
App 下载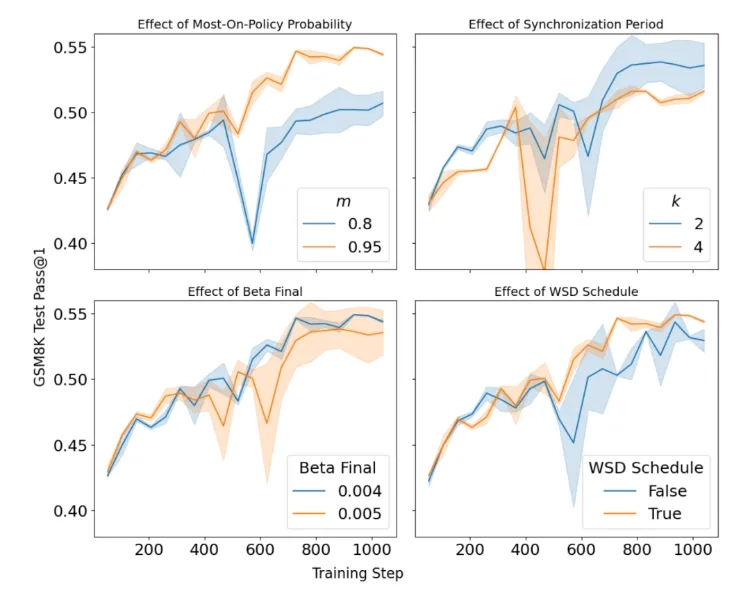
大模型RL后训练提速50倍,采样与学习终于分家
训练提速|强化学习后训练|TBA框架|Yoshua Bengio团队|大语言模型|人工智能
对抗知识焦虑,从看懂这条开始
App 下载训练提速|强化学习后训练|TBA框架|Yoshua Bengio团队|大语言模型|人工智能
想象一下:你在厨房炒菜,锅里的菜已经炒到半熟等着调味,你却必须等超市把新鲜食材送上门才能继续——这就是过去大模型强化学习(RL)后训练的尴尬处境。生成样本的过程像逐字手写一样慢,训练模型的环节却能像批量做饭一样并行推进,为了让样本「够新鲜」,训练只能空等采样完成,集群算力常年跑不满,旧样本更是直接作废。直到Yoshua Bengio团队拿出TBA框架,把这两件事彻底拆成两条流水线,最高让训练速度翻了50倍。这不是简单的加速,而是重新定义了AI学习的基本逻辑。
你可以把过去的RL训练看成是「厨师自己买菜自己炒菜」——买完菜才能下锅,炒完菜再去买下一批,哪怕炒菜的速度比买菜快10倍,也只能跟着买菜的节奏走。TBA的核心改变,就是把「买菜」和「炒菜」分成两个独立团队:Searcher负责「买菜」,也就是用稍旧版本的模型持续生成回答样本,存在自己的小仓库里;Trainer负责「炒菜」,从一个共享的大仓库里随便拿菜就炒,不用等新菜送到。
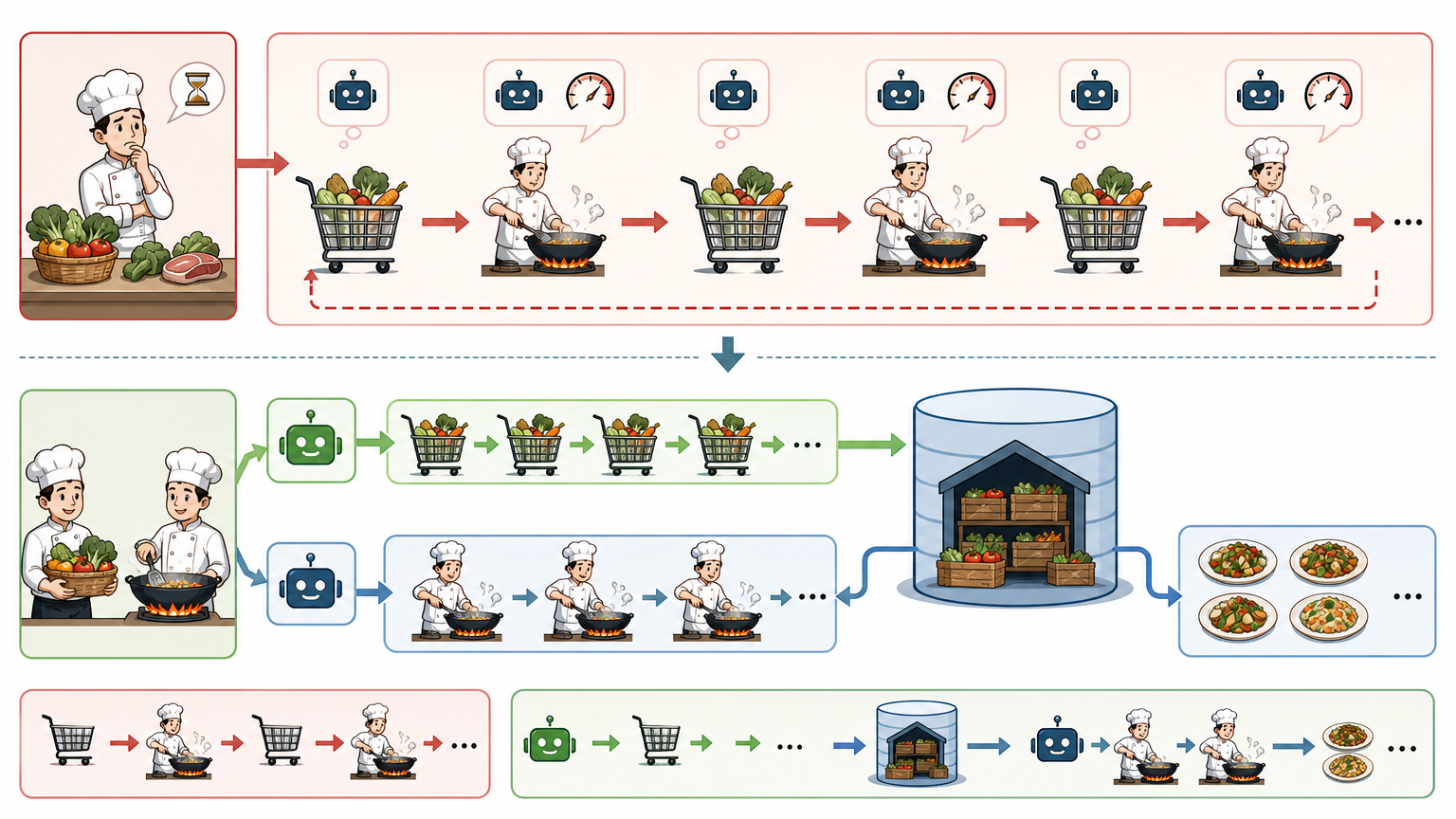
两者只在固定时间点同步:每隔一定步数,Trainer把最新的模型参数同步给Searcher,Searcher把攒的样本全倒进共享仓库。这种设计直接把集群的算力利用率拉满——再也不会出现训练节点空等采样的情况,Searcher可以24小时不停生成,Trainer也能一刻不闲地训练。
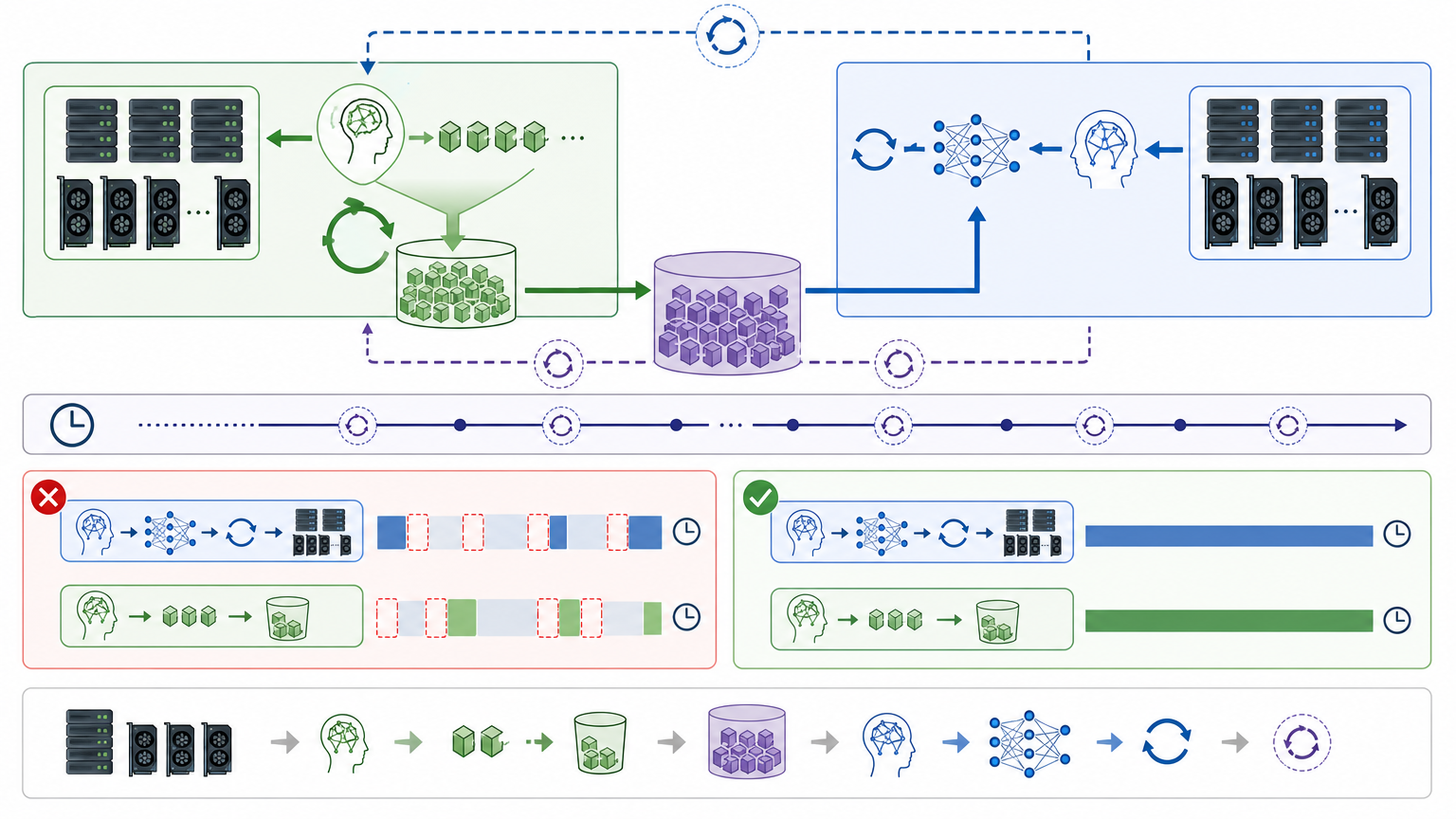
但这里有个关键问题:Searcher用的是旧模型,生成的样本是「旧策略产物」,直接给新模型用会导致训练混乱。这就需要另一个核心技术来兜底。
传统RL方法之所以不敢用旧样本,是因为新模型和旧模型的「解题思路」不一样,硬用旧题训练,会把新模型带偏。TBA解决这个问题的核心,是从GFlowNet里借来的「轨迹平衡」目标。
你可以把模型生成回答的过程看成是走迷宫:从问题出发,每选一个token就是走一步,最后走到答案终点。轨迹平衡的思路是,不管你是用旧模型还是新模型走的迷宫,只要这条路径能从起点走到终点,就有它的学习价值。它不像传统方法那样用复杂的「重要性采样」来修正新旧策略的差异,而是直接对整条路径的概率进行平衡约束,让旧样本能直接参与训练,不用做复杂的修正。
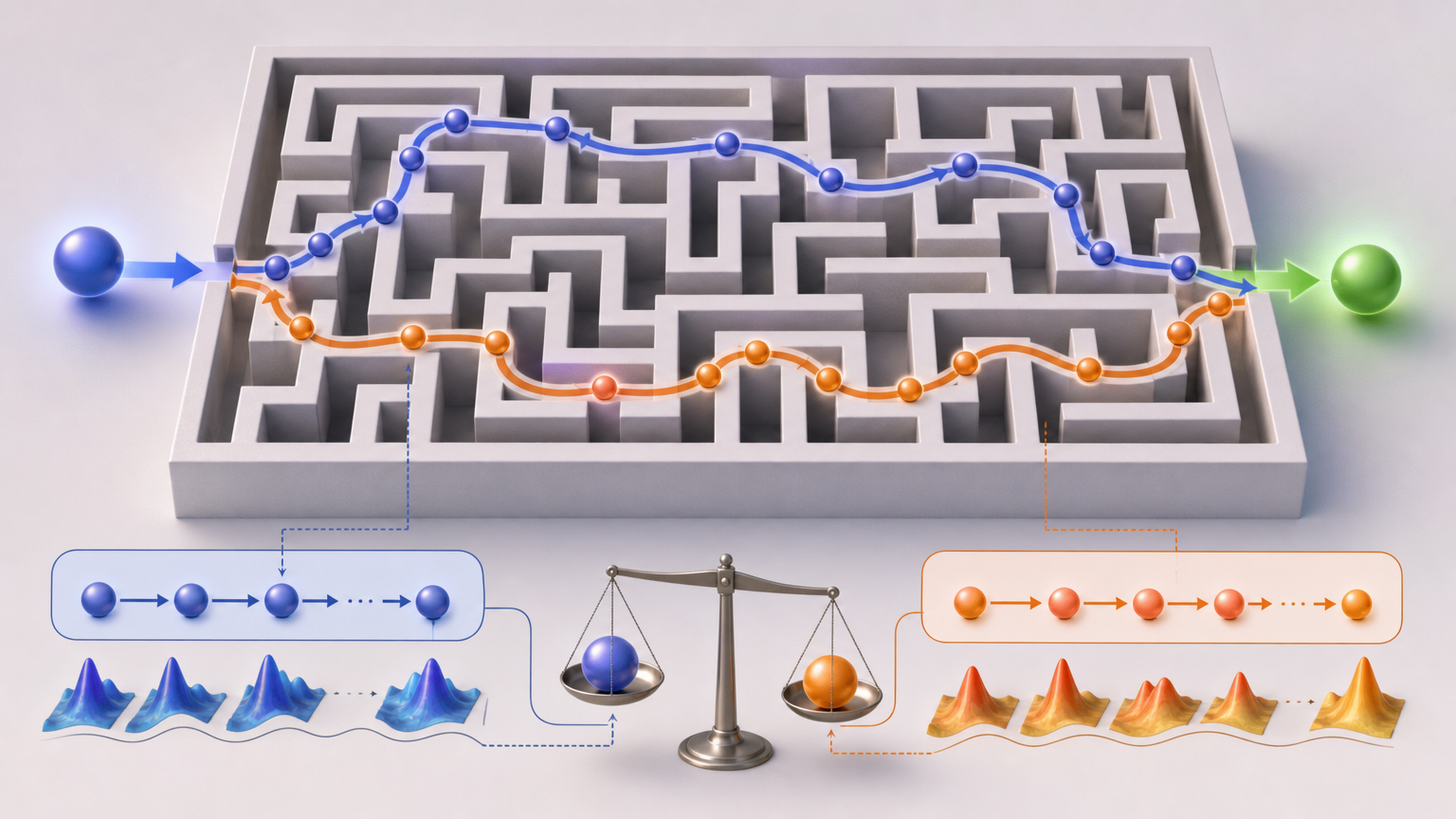
具体到技术上,TBA用了VarGrad TB变体——给同一个问题生成多个回答,用这些回答之间的差异来估计训练目标,既避免了额外训练模型,又降低了训练的方差。实验显示,这种方法处理旧样本的稳定性,远超传统的重要性采样机制。
为了平衡「新鲜样本」和「旧样本」的比例,TBA还设计了一套混合采样策略:用一定概率优先选最新的样本保证训练方向,剩下的概率从历史样本里混合选,既不浪费高质量旧数据,又能保持探索的多样性。
很多加速方法都是以牺牲性能为代价,但TBA在数学推理、偏好微调、自动红队这三类核心任务上,都做到了「更快且更好」。
在GSM8K小学数学推理任务上,用4张A100 GPU训练,TBA比传统的VinePPO快了50倍,准确率还高了1.2%-1.8%;在TL;DR摘要偏好微调任务上,比异步DPO快3.8-5.3倍,同时在「回答质量」和「与人类偏好的对齐度」上达到了更好的平衡;在自动红队任务中,训练速度快了7倍,而且随着采样节点增多,攻击成功率和策略多样性还能持续提升。
即便是在7B规模的大模型和高度「旧策略样本」的极端场景下,TBA的变体也比Dr. GRPO表现得更稳定——后者的训练曲线会出现明显波动,而TBA的曲线始终平滑。
当然TBA也不是完美的:轨迹级别的训练目标会带来更高的梯度方差,需要给每个问题生成更多回答来抵消,这对样本构造和采样策略提出了更高要求。但相比它带来的效率提升,这一点代价几乎可以忽略。
过去我们总觉得,AI学习必须「用最新的题,练最新的招」,就像学生必须做今年的模拟题才能高考一样。TBA的出现打破了这个惯性思维:原来旧题也能练出新本事,只要你换一种评卷方式。
这不仅仅是一次技术优化,而是对AI训练逻辑的一次重组——从「采样等训练」的串行逻辑,变成「采样和学习并行」的异步逻辑,从「旧样本作废」的浪费模式,变成「全样本利用」的高效模式。当大模型的训练越来越依赖大规模采样和稀疏奖励,这种「异步搜索-学习」框架,或许会成为AI自我进化的核心动力。
采样与学习的分家,不是分裂,而是让AI的每一份算力,都用在真正能学到东西的地方。