
1 个月前
1 个月前
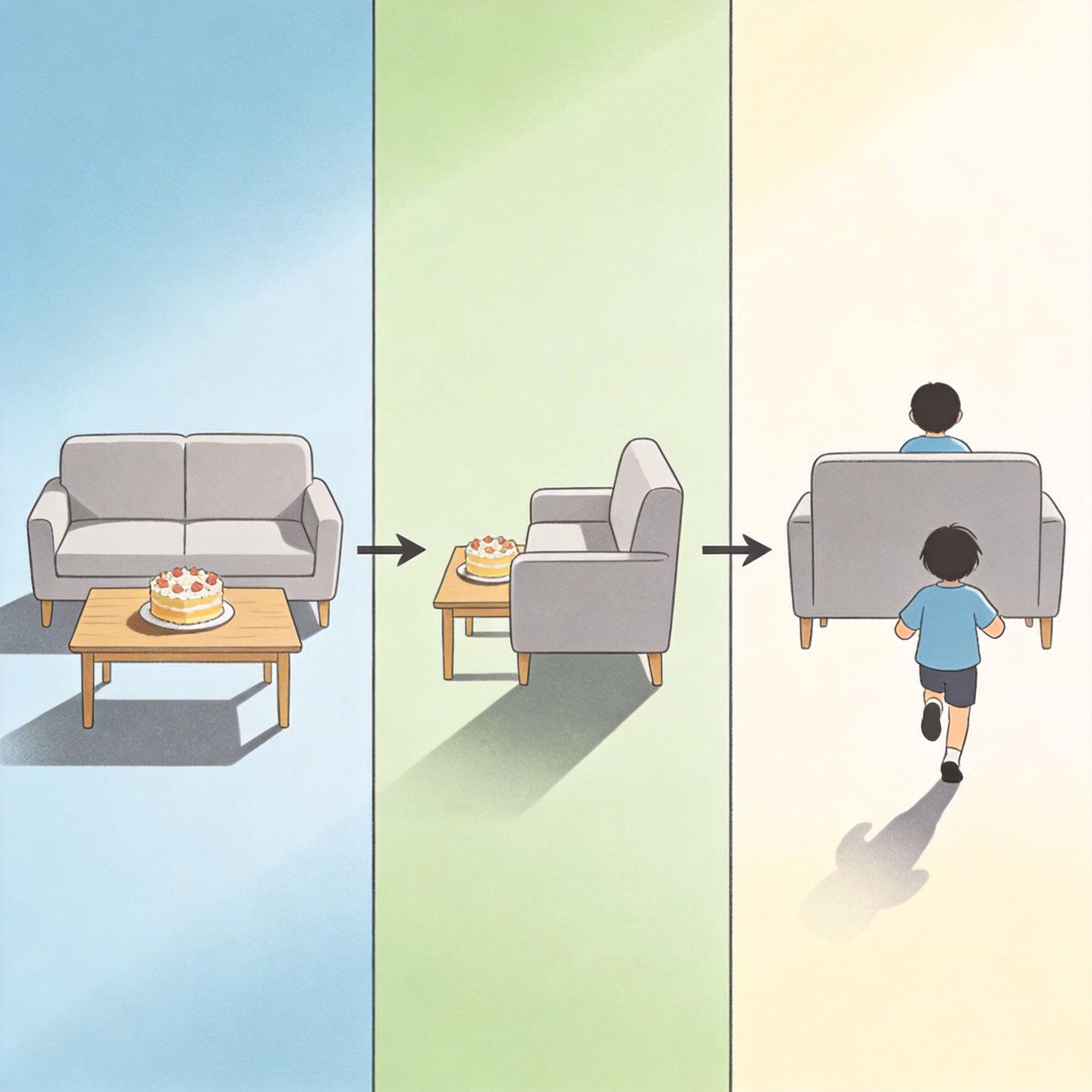
你刚用手机拍完孩子的生日会镜头——客厅的气球、蛋糕上的蜡烛、老人笑出皱纹的脸,全在1080P的画面里。但你总觉得差点什么:那些镜头没拍到的、藏在沙发背后的打闹声,那些从餐桌旁飘过来的奶油香,好像没法被这一段二维视频装下。
现在有技术能把它变成4K全景VR大片。你可以戴着头显站在客厅中央,转头就能看见孩子躲在沙发后面拆礼物,低头能看到脚边蹭来蹭去的猫,甚至能闻到虚拟的奶油甜香——而这一切,只需要你那一段普通的手机视频。
这不是科幻。关键在于,它是怎么把那些“没拍到的部分”补全的?
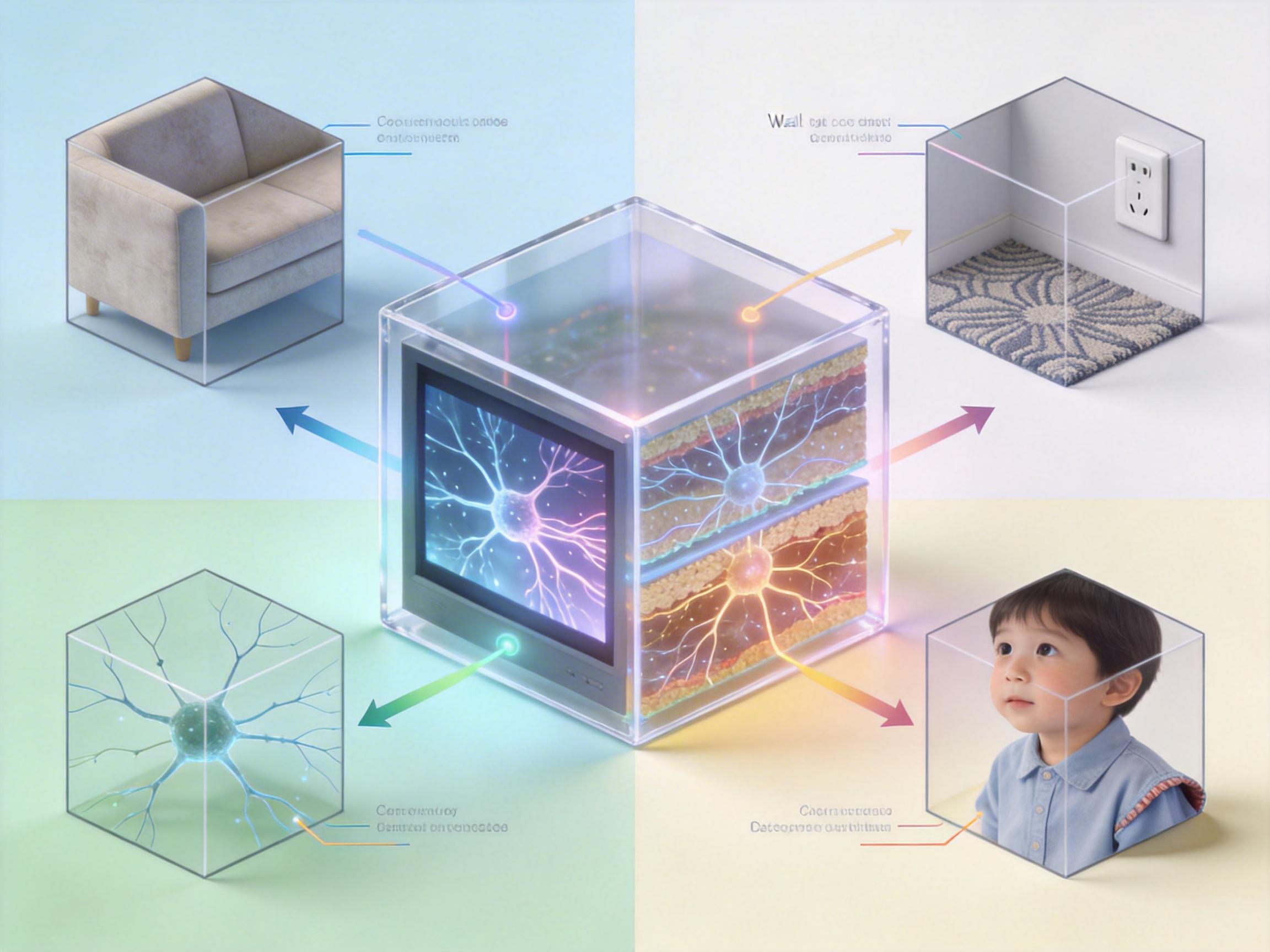
你可以把普通视频的画面,想象成从一个立方体的正前方窗户里看出去的场景——我们平时拍的视频,永远只能看到这一扇窗户里的世界。而VR全景需要的,是这个立方体的六个面,也就是前后左右上下所有方向的画面。
奥塔哥大学的VisualComputingOtago团队,就是用这个“立方体逻辑”解决了补全问题。他们先把输入的普通视频“贴”在立方体的正面,然后用训练好的卷积神经网络,像补拼图一样,根据正面的画面细节,生成出另外五个面的内容——沙发的纹理、地毯的花纹、墙角的插座,甚至是孩子躲在沙发后露出的衣角,都能被精准还原。
不是凭空乱画。
算法会先分析视频里的光影、色彩和物体逻辑:比如从正面看到的沙发是浅灰色,那侧面也不会变成深棕色;蛋糕放在木质餐桌上,那桌底的阴影角度必须和桌面的光照一致。它甚至能记住视频里的动态——孩子从正面跑到沙发后面,算法生成的侧面画面里,会同步出现他跑动的背影。
最关键的是,整个过程不需要额外放大画面,补全的部分和原视频的分辨率完全一致,不会出现模糊或拉伸的伪影。
我认为,这项技术最核心的价值,从来不是“把视频变清晰”,而是彻底打碎了VR内容创作的门槛。
在此之前,要做一段合格的VR全景视频,你需要至少6台同步拍摄的专业相机,一套价格不菲的拼接软件,还要有足够的空间和时间去布置场景——这些门槛把99%的普通人挡在了门外。VR内容市场里,要么是专业团队做的昂贵大片,要么是粗糙的360度风景视频,真正能承载个人情感的内容少得可怜。
现在不一样了。你用手机拍的任何一段日常视频,都能成为VR内容的原材料:孩子的第一次走路、爸妈的金婚纪念日、和朋友在海边的周末,这些充满温度的日常片段,终于能以“沉浸式”的方式被保存下来。你不用再担心“没拍全”,算法会帮你把那些藏在镜头背后的、属于你的独家记忆补全。
更值得关注的是,这不是技术对创作的替代,而是赋能。算法只负责补全“没拍到的空间”,而视频里的情感、故事和温度,依然完完全全属于你。它就像给了你一支能画出“空气”的笔,让你能把那些看不见的情绪,也变成能被看见的画面。
当然,这项技术也不是完美的。
目前的算法还很难处理极端复杂的动态场景——比如你拍了一段拥挤的地铁视频,算法可能会把旁边乘客的脸补成模糊的色块,或者把移动的扶手“粘”在人的身上。这不是技术不够强,而是我们对“真实”的要求,远远超过了算法能理解的边界。
更重要的是,我们还没想清楚,普通人到底需要什么样的VR内容。是把每一段日常都变成全景大片,还是只在那些真正重要的时刻,才用这种方式记录?当我们能轻易把任何视频都变成VR内容时,会不会反而让那些“重要的时刻”变得不再特殊?
我见过有人把自己吃外卖的视频也做成了VR全景,戴着头显坐在虚拟的餐桌前,看着自己低头扒饭的样子——这不是沉浸,这是一种荒诞的孤独。技术给了我们无限的可能性,但我们需要先想清楚,什么样的内容值得被“沉浸”。
当我们谈论VR时,我们总在说“未来”“元宇宙”“虚拟世界”,但这项技术最动人的地方,恰恰是它让我们更贴近“现在”——那些我们以为已经失去的、藏在镜头背后的、属于当下的瞬间,终于能被完整地保存下来。
最好的沉浸,是回到日常。
也许未来某一天,你戴着头显走进虚拟的客厅,看到的不只是一段视频,而是那个下午的阳光、孩子的笑声、甚至是蛋糕上融化的奶油——你伸出手,好像还能摸到孩子柔软的头发。这不是虚拟对现实的替代,而是记忆对时间的反抗。
点击充电,成为大圆镜下一个视频选题!