对抗知识焦虑,从看懂这条开始
App 下载
AI不再只会看图,它开始用图像思考了
老电影剧照|国内AI团队|自我修正|图像推理|多模态视觉|人工智能
对抗知识焦虑,从看懂这条开始
App 下载老电影剧照|国内AI团队|自我修正|图像推理|多模态视觉|人工智能
你上传一张模糊的老电影剧照,AI不仅能说出这是《肖申克的救赎》里安迪逃出监狱的雨夜,还会追问你:“你是在聊希望的隐喻吗?”甚至当它一开始数错了图里的铁丝网数量,会立刻纠正:“抱歉,我数错了,应该是7根——刚才把雨丝当成了铁丝。”
这不是科幻场景,而是国内某AI团队最新的内测功能。过去AI看图像,顶多是“看图说话”,把视觉信号转成文字描述;现在它能把图像当成思考的素材,像人一样推理、质疑、自我修正。这背后,是多模态大模型从“感知”到“认知”的关键一跃——而这一步,终于让AI离真正的“理解”更近了一步。
你可以把早期的多模态模型想象成两个各干各活的工人:一个负责看图像(视觉编码器),把画面拆成一个个特征向量;另一个负责读文字(语言模型),把句子拆成一个个语义单元。最后两个人把各自的成果往一起一凑,就算完成了“融合”。这种“分工合作”的模式,就像让一个画家和一个诗人一起写剧本,两个人各说各话,根本搭不上逻辑。
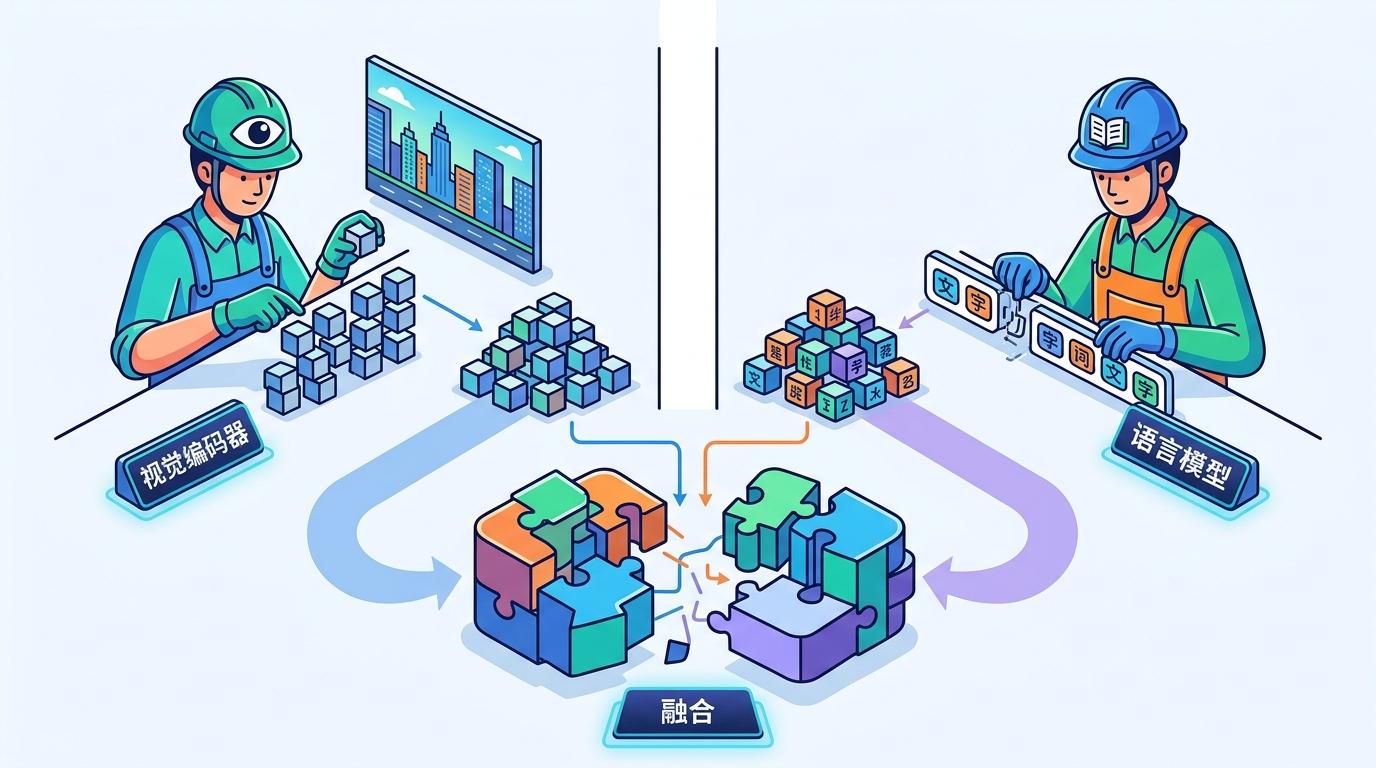
Transformer架构的出现改变了一切。它的自注意力机制就像给两个工人装了对讲机,让视觉和语言模块能实时对话——视觉编码器看到雨夜的闪电,会立刻告诉语言模型“这是紧张的信号”;语言模型读到“希望”这个词,会反过来提醒视觉编码器“注意看安迪脸上的微光”。
现在的顶尖模型,比如GPT-4o、DeepSeek V4,干脆把两个模块彻底整合成了一个统一的Transformer架构。图像不再是事后拼接的附件,而是和文字一样,变成了模型推理链条里的核心原料。就像你思考时会同时调动视觉记忆和语言逻辑,AI现在也能“用图像思考”。
真正让AI“会思考”的,不是它能看懂图像,而是它能像人一样“试错”。
比如你给AI看一张“大象站在茶杯里”的合成图,早期模型只会机械描述:“一只大象站在茶杯里。”但现在的模型会先提出假设:“这应该是一张合成图——大象的比例和茶杯不符。”然后它会验证这个假设:“茶杯的直径大约是10厘米,而大象的肩高至少3米,比例差了300倍。”最后得出结论:“这是通过图像编辑软件合成的创意图片,用来表达反差感。”
这种“假设-验证-修正”的逻辑,来自多模态链式思维(MCoT)技术。它就像给AI装了个“思考草稿本”,让它把推理步骤一步步写下来,而不是直接蹦出答案。如果中间哪一步错了,比如把雨丝当成铁丝网,它能顺着草稿本往回找,发现错误后立刻修正。
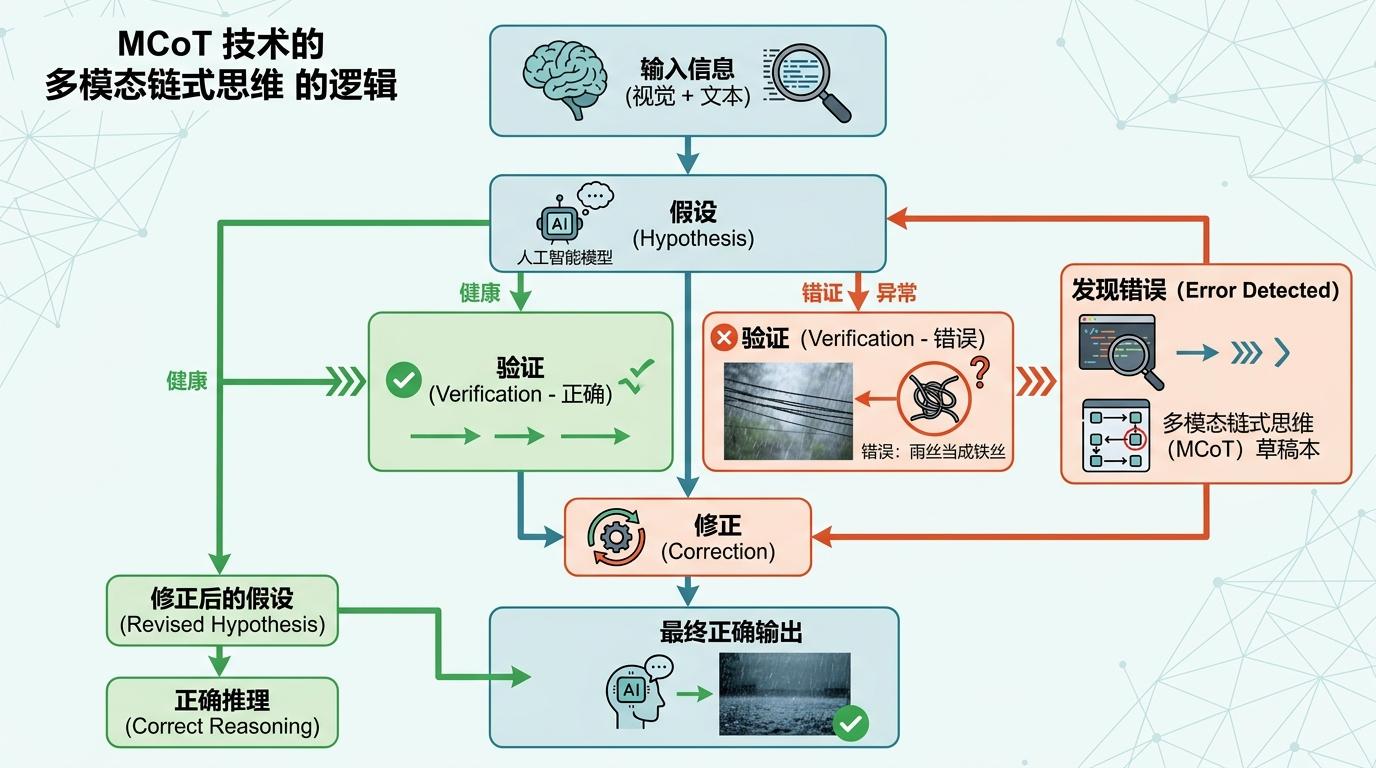
清华大学的一项研究显示,给多模态模型加上自我纠错机制后,它在视觉推理任务中的准确率能提升13%——这相当于一个学生从70分跳到83分,已经是质的飞跃。
但现在的AI,还远没到“无所不能”的地步。它的“思考”,还存在三个致命的短板。
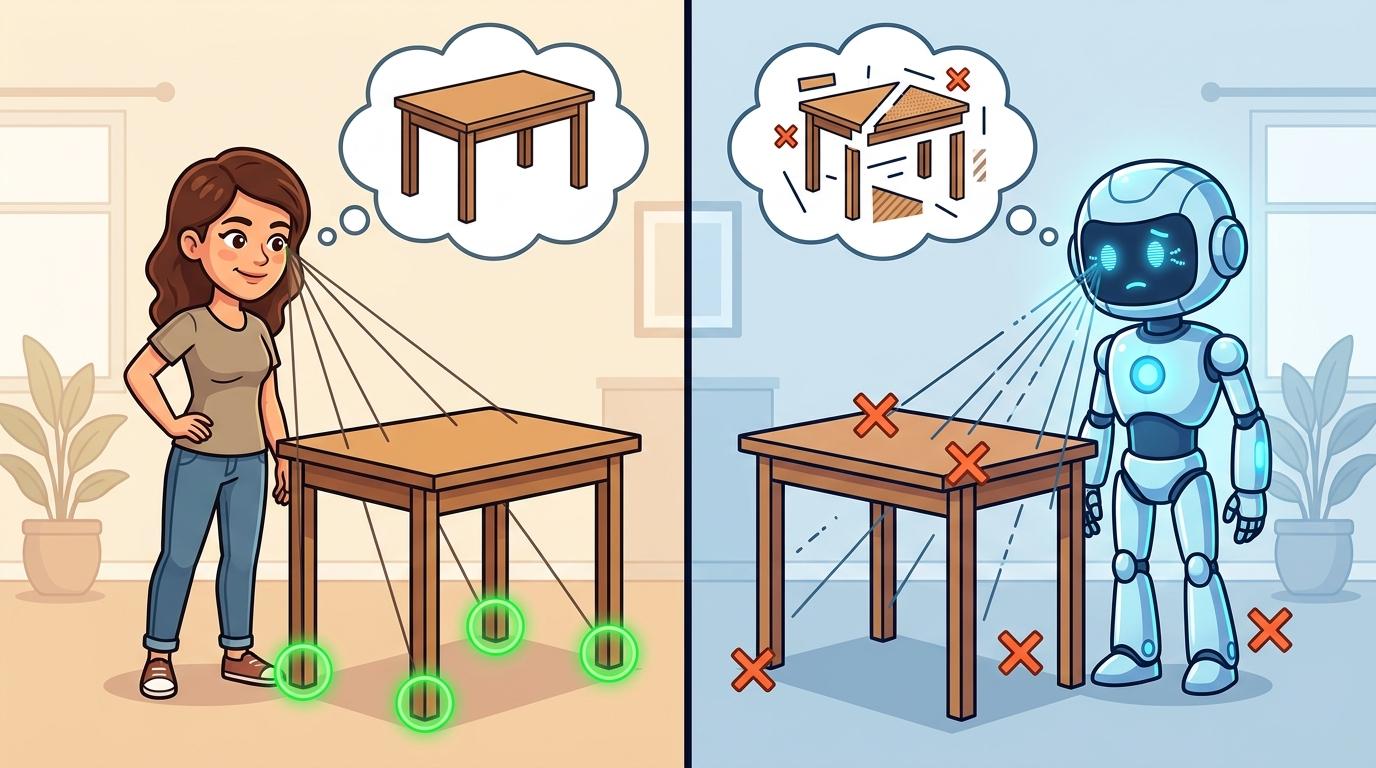
第一个坎是“空间理解差”。你给AI看一张从侧面拍的桌子,它能认出是桌子,但如果问它“桌子的四条腿在哪里”,它大概率会指错——因为它看不懂三维空间,只能根据二维图像的纹理和形状瞎猜。有研究测试了23个顶尖多模态模型,发现它们连基本的角度、大小都认不准,准确率还不如一个小学生。
第二个坎是“模态冲突”。如果图像里有错误信息,比如把猫的脸P到狗的身上,AI会被彻底搞晕:它的视觉模块看到猫脸,语言模块却记得狗的身体,最后可能会输出一句“一只猫身狗脸的动物”——完全不知道这是一张合成图。
第三个坎是“没长记性”。你现在给AI看一张你的照片,告诉它这是“张三”,过10分钟再给它看同一张照片,它可能已经忘了这是谁。它没有长时记忆,每次思考都是从零开始,根本做不到“举一反三”。
当AI开始“用图像思考”,我们突然发现,人类的智能原来如此复杂——我们能一眼认出照片里的朋友,能从一张画里读出情绪,能在脑海里想象出三维的桌子,这些“理所当然”的能力,竟然是AI最难跨越的鸿沟。
多模态AI的进步,从来不是为了造出一个“无所不能的机器”,而是为了帮我们看清:人类的智能,到底藏在哪些我们从未留意的细节里。
看懂图像只是开始,理解世界才是目标。