对抗知识焦虑,从看懂这条开始
App 下载
AI终于能“指着图像思考”,效率提7000倍
观众计数|计算资源效率|图像定位|视觉原语技术|DeepSeek团队|多模态视觉|人工智能
对抗知识焦虑,从看懂这条开始
App 下载观众计数|计算资源效率|图像定位|视觉原语技术|DeepSeek团队|多模态视觉|人工智能
给AI看一张挤满人的演唱会照片,问“有多少个戴红帽子的观众”——过去它可能要么数错,要么答非所问地说“这是一场热闹的演出”。但现在,有模型能像你我一样,用“手指”点着每个红帽子数:“1、2、3……一共17个”,还能把每个帽子的位置坐标精准列出来。更夸张的是,处理同一张800×800的图片,它需要的计算资源只有GPT-5.4的1/7000。这不是科幻场景,而是DeepSeek团队推出的“视觉原语”技术实现的突破。为什么这个“指着思考”的能力,会成为多模态AI的关键转折点?
过去的多模态AI就像个记性不好的观察者:刚说“左边的猫在睡觉”,下一句就把右边的狗当成了那只猫——这就是行业里说的“引用缺口”:语言描述在推理链中会漂移,没法稳定指代同一个视觉对象。

你可以把这个问题类比成一群人讨论一张地图:有人说“东边的山”,有人说“靠海的山”,到最后没人能确定说的是同一座。而视觉原语,就是给AI递了一支能在地图上画圈的笔——它把点坐标和边界框当成和文字一样的“思考单元”,推理时边说边“指”:“我看到一只猫
这个设计直接把推理链和图像空间牢牢绑定,从根源上避免了“指东说西”的逻辑混乱。在计数任务中,它的准确率能达到89.2%,比GPT-5.4高出12.6个百分点;迷宫导航这类拓扑推理任务,准确率更是领先近17个百分点。
视觉原语能落地的核心,是极端的视觉Token压缩技术——这相当于把一本几百页的书,提炼成只有90个关键词的摘要,还不丢核心信息。
传统模型处理一张800×800的图片,会先切成几千个小方块(Token),每个方块都要占用计算资源。而DeepSeek的流程是:先用自研的视觉编码器把图像切成基础方块,再通过3×3空间合并把方块数量压缩到原来的1/9,最后用稀疏注意力机制只保留和推理相关的关键方块。最终一张图只需要约90个KV缓存条目,而Claude Sonnet 4.6需要870个,Gemini-3-Flash需要1100个,压缩比达到7056倍。
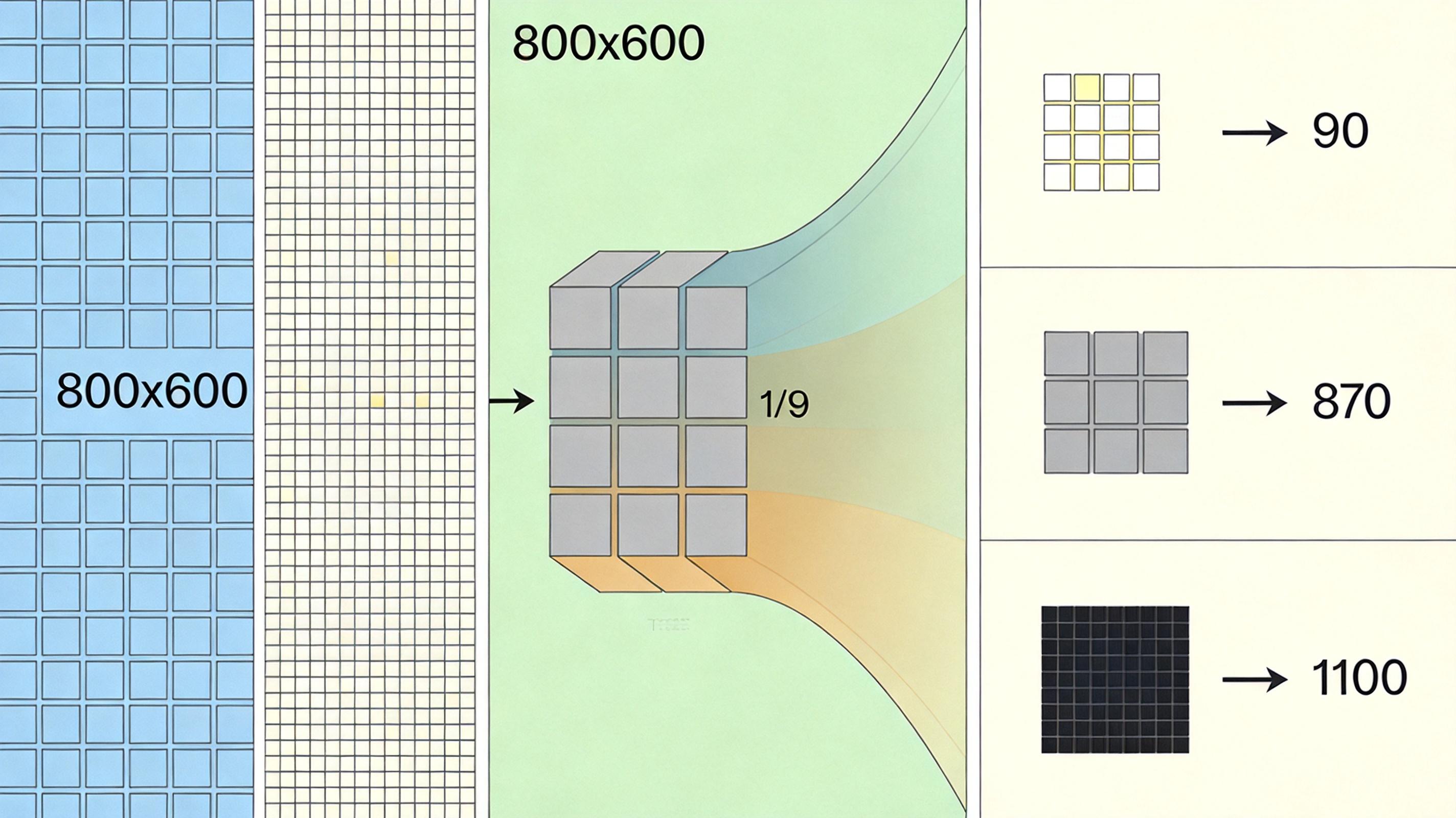
这种压缩不是简单的“丢信息”,而是精准的“留核心”:和推理无关的背景、冗余像素都被过滤,只留下能支撑计数、空间判断的关键坐标和边界框。直接结果就是推理延迟降低20%-30%,计算成本大幅下降,却能在空间推理任务上对标GPT-5.4。
当然,这项技术目前还有局限:它需要用户输入触发词才能启用视觉原语,还做不到自主判断何时该“指”;为了压缩Token,图像分辨率被限制,处理医学影像这类需要细粒度观察的场景时精度会打折扣。
要让AI熟练用视觉原语思考,训练数据和任务设计得“对症下药”。团队没有用常见的合成数据,而是采集了近10万条真实图像的语音描述——让标注者用60-90秒口述图像细节,再转成文本,最终筛选出3.17万条高质量数据,生成了4000多万训练样本。
他们设计的训练任务像一场“空间思维闯关游戏”:从基础的计数,到判断“猫在狗的左边还是上边”的空间推理,再到走迷宫、追路径的拓扑推理。比如迷宫导航任务,模型要在完全陌生的迷宫布局里,用坐标点标记出从入口到出口的路径,考验的是对空间连通性的理解。
这种训练让AI的“空间感”不再是靠统计规律蒙答案,而是真正建立起视觉对象和语言描述的对应关系。在处理长文档时,这项技术还能把表格、图表转成压缩的视觉Token,比传统文本处理效率高10倍以上,解码精度能达到97%。
当我们讨论AI的“理解能力”时,总习惯盯着它能不能说出复杂的句子,能不能生成逼真的图片,却常常忽略最基础的一点:它能不能像人一样,把“看到的”和“想到的”精准绑定。
视觉原语的意义,不是让AI“看得更清楚”,而是让它“想得更明白”——用最朴素的坐标和边界框,给AI的推理链钉上了不会漂移的锚点。未来的AI不需要记住所有像素,但必须能精准抓住每个关键信息的位置。
看得清是基础,盯得住才是智能。