对抗知识焦虑,从看懂这条开始
App 下载
大模型不用全参数干活,推理反而更强了
模型架构|长文本推理|参数激活|混合专家模型|大语言模型|人工智能
对抗知识焦虑,从看懂这条开始
App 下载模型架构|长文本推理|参数激活|混合专家模型|大语言模型|人工智能
当你让AI解一道高中生物竞赛题,或是梳理一份20万字的合同,它的“大脑”其实没必要全功率运转——就像你算买菜账时不会动用微积分知识。最近有团队用一套新架构,让AI只调用21亿参数,就能在长文本推理、复杂问题解决上超过不少国内同类模型,而它的总参数其实高达2950亿。这种“藏着大部分能力只露一手”的操作,靠的就是混合专家模型(MoE)——一种让AI像公司团队一样分工干活的技术。为什么只激活小部分参数反而能提升效率?这背后藏着大模型突破性能瓶颈的关键逻辑。
你可以把混合专家模型想象成一个没有老板的项目组:总共有上百名“专家”,但接到任务时,只会选出最擅长的2-8个来处理,其他人全程待命。这里的“专家”是一个个独立的小型神经网络,有的专门算数学题,有的擅长解析长文本,有的对代码敏感——它们在训练中会自然形成“专业偏向”,比如有的专家总能精准抓住合同里的风险条款,有的对物理公式的推导格外熟练。
而路由器就是负责派活的“调度员”,它会给每个输入的信息片段打标签,再根据标签把任务分给对应专家。比如输入一段代码,路由器就会激活擅长编程的专家;输入一道几何题,就会调动数学推理专家。和传统大模型每次都要唤醒所有参数不同,混合专家模型每次只激活10%甚至更少的参数,计算成本直接砍到原来的几分之一。
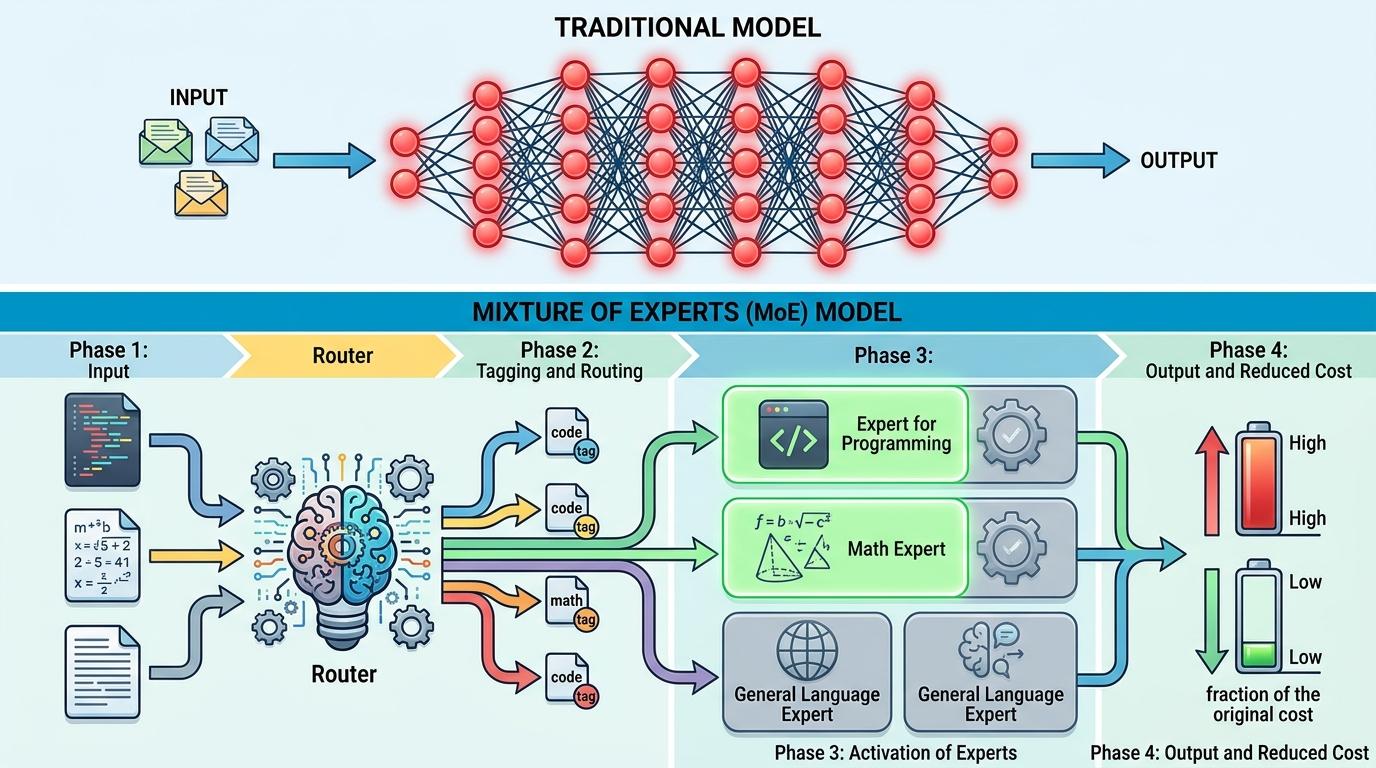
但真实的机制比这个类比更精确:每个“专家”其实是Transformer架构里的前馈网络层,路由器则是一个带可学习参数的小型网络,它会计算每个专家处理当前任务的匹配度,再通过Top-K选择选出最合适的几个,最后把这些专家的输出结果加权合并,得到最终答案。
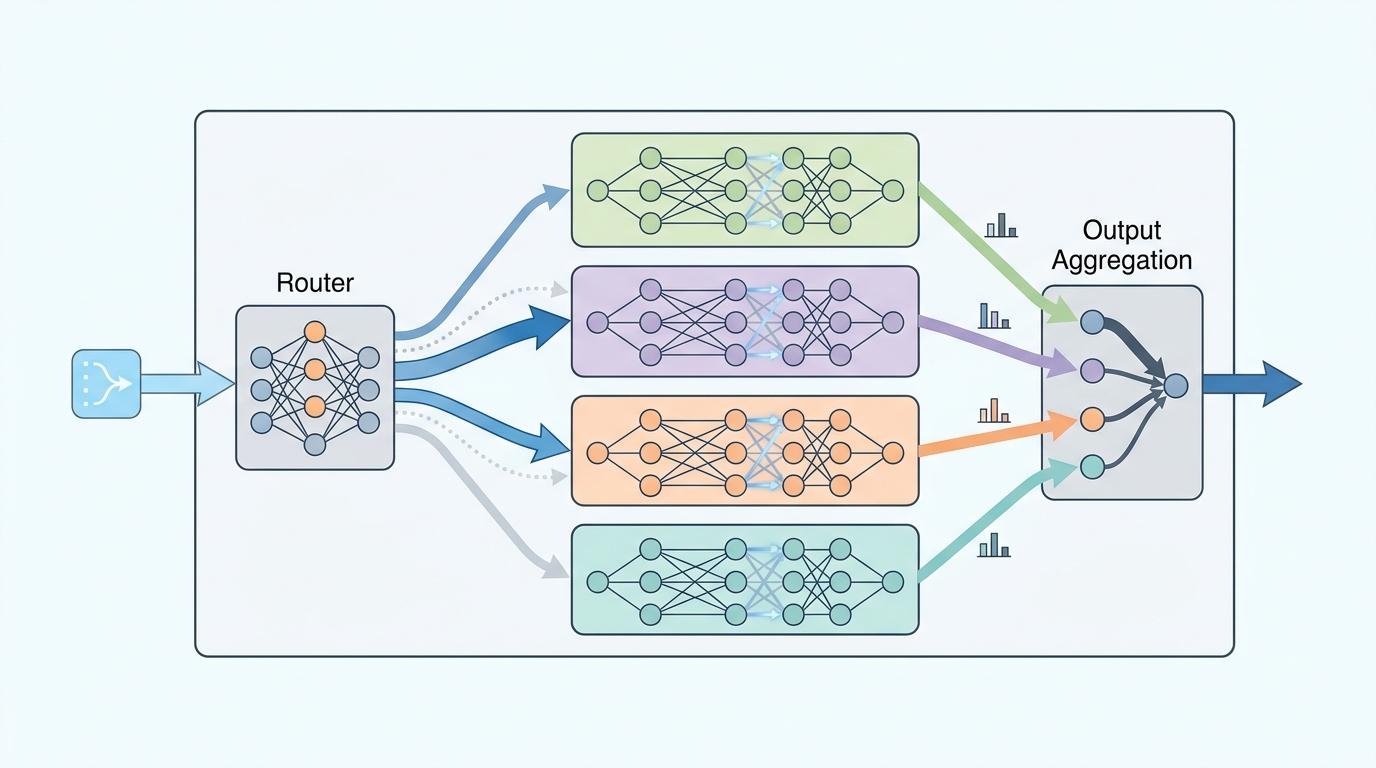
这种分工模式最大的优势,是解决了大模型发展的核心矛盾:既要提升能力,又要控制成本。传统密集模型想提升性能,只能不断堆参数,但参数越大,训练和推理的成本就越高,甚至会出现“参数再多也不涨性能”的瓶颈。而混合专家模型可以在不增加单次计算量的前提下,无限扩充总参数——就像公司可以不断招新专家,但每个项目还是只需要几个人。
更关键的是,科学家发现混合专家模型里藏着一群“认知专家”——它们专门负责AI的“思考过程”。通过统计专家激活和推理标记词的关联度,研究人员可以找出那些在AI“深度思考”时最活跃的专家,只要在推理时稍微强化这些专家的权重,就能让AI的推理准确率提升10%以上,同时还能减少冗余输出,让思考过程更高效。
比如在处理256K长度的长文本时,传统模型可能会因为信息过载而忽略关键细节,混合专家模型则能调动专门处理长上下文的专家,像梳理线头一样把零散信息串联起来。在长文本推理测试中,这种架构的模型已经能超过不少以长上下文为卖点的同类产品。
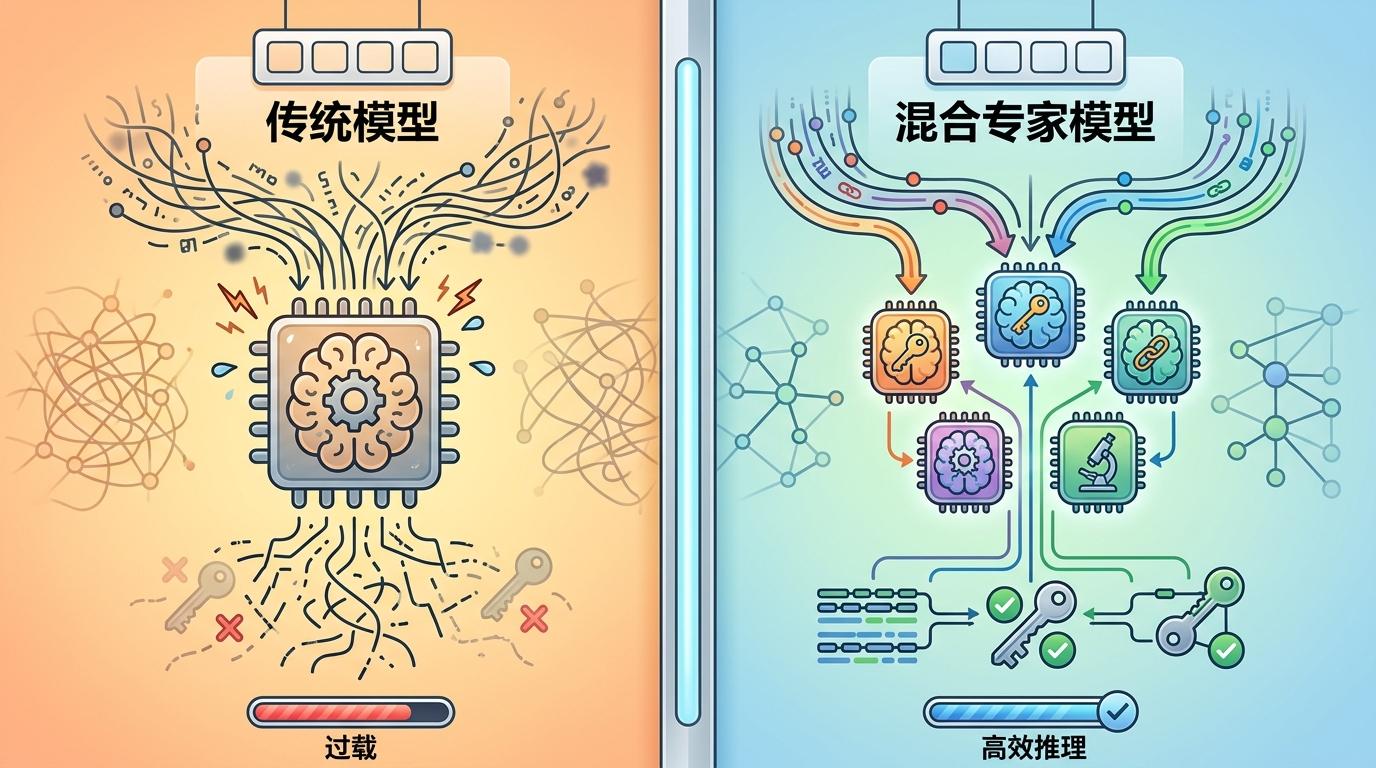
混合专家模型的优势很明显,但它也不是完美的技术方案。第一道坎是“调度员”的能力:如果路由器派活不准,把数学题分给了代码专家,就会直接影响结果质量。而且训练时还得防止“路由崩溃”——也就是所有任务都集中在少数几个专家身上,导致其他专家闲置,模型失去多样性。
第二道坎是训练的稳定性。因为专家是稀疏激活的,每个专家接收到的训练数据都比密集模型少,容易出现过拟合。而且不同专家的训练进度不一致,也会影响整体模型的协同能力。为了平衡这一点,研究人员不得不加入各种辅助损失函数,让专家们的工作量尽量均匀。
第三道坎是部署的复杂度。混合专家模型需要把不同专家分配到不同的GPU上,这就对硬件通信效率提出了极高要求——如果专家之间的信息传递太慢,反而会拖慢推理速度。目前只有少数高端硬件平台能完美适配这种架构的大规模部署。
当我们还在惊叹大模型的参数规模时,混合专家模型已经悄悄把方向从“堆参数”转向了“提效率”。它让我们意识到,AI的智能程度,从来不是由参数多少决定的,而是看能不能把合适的能力用在合适的地方。
未来的大模型,可能会像一个拥有无数隐形专家的超级团队,平时只露出冰山一角,遇到难题时才会调出对应的高手。少激活,多精准,才是AI效率革命的核心。而那些藏在模型里的“认知专家”,或许会成为未来AI拥有真正“思考能力”的关键起点。