对抗知识焦虑,从看懂这条开始
App 下载
内存涨5倍倒逼出的技术:手机能跑60B大模型
内存价格|模型压缩|手机端AI|清华大学|面壁智能|大语言模型|人工智能
对抗知识焦虑,从看懂这条开始
App 下载内存价格|模型压缩|手机端AI|清华大学|面壁智能|大语言模型|人工智能
2026年的手机用户可能很快会发现,你的手机突然“聪明”了不止一点——它能离线帮你写完整的工作方案,能实时把眼前的外文路牌翻译成方言,甚至能精准预判你下一个想打开的APP。这不是科幻:面壁智能联合清华大学发布的一款新模型,让手机运行600亿参数大模型从空想变成了可能。
而这一切的起点,不是什么技术突破的灵光一闪,而是今年以来已经涨了5倍的内存价格。当手机厂商不得不压缩内存成本时,AI从业者们反而找到了一条更高效的路:把原本占满服务器内存的大模型,“挤”进手机那点有限的存储空间里。
你可以把大模型想象成一本厚厚的百科全书,全精度模型就像是原版精装书,每一个字都印得清清楚楚,占满了整个书架。而极低比特量化技术,就是把这本书做成了极致压缩的口袋本——不是删减内容,而是用更高效的排版和字体,在几乎不丢信息的前提下,把体积缩小到原来的1/6。
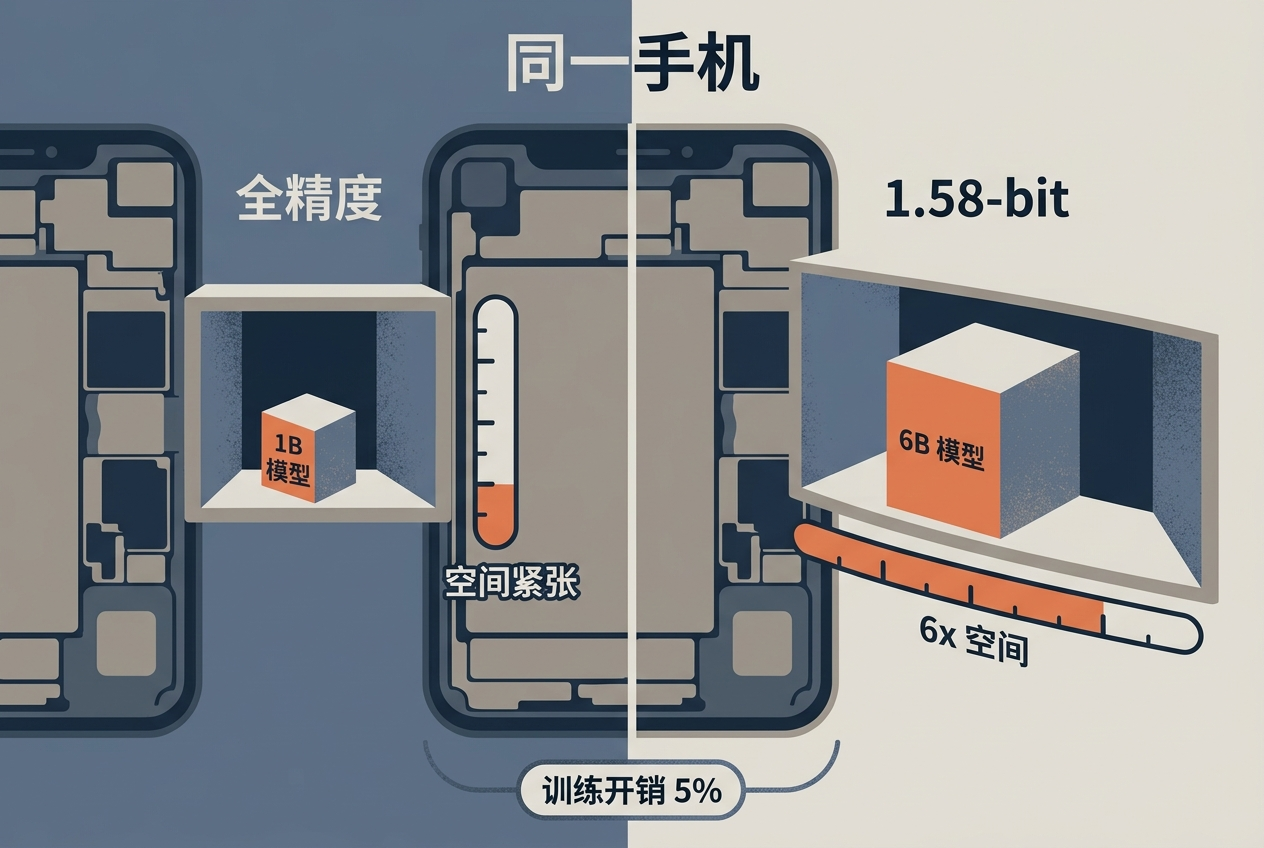
这次推出的1.58-bit三值量化模型,就是把模型里的每一个参数,从原来需要16个二进制位表示的浮点数,压缩成只需要{-1,0,1}三个值的三进制数,相当于每个参数只用到了1.58个二进制位。打个更通俗的比方:原来存一个参数需要16个格子,现在只需要2个格子就够了,剩下的空间还能再装5个同样的参数。
但压缩可不是简单的“打包”。为了不让模型因为压缩变“傻”,研究者们用了两套关键技术:量化感知训练(QAT)和大模型蒸馏。前者是在训练模型的时候就模拟压缩后的状态,让模型提前适应“压缩环境”;后者则是让小模型“抄作业”——把全精度大模型的知识,一点点“教”给压缩后的小模型。最终,新模型的能力保留率能稳定在90%到97.2%之间,相当于把百科全书压缩成口袋本后,你依然能查到9成以上的关键信息。
其实早在2024年下半年,行业里就达成了一个共识:未来手机上一定会跑大模型。但那时候大家的关注点还停留在“能不能跑”——只要能把模型塞进手机,哪怕只能做简单的问答,都算是突破。
但内存价格的暴涨,把行业的关注点直接拉到了“怎么高效跑”上。2026年以来内存价格涨了5倍,手机厂商不得不控制成本,这意味着留给模型的存储空间变得更紧张了。就像你本来想在手机里装一部高清电影,结果只能装一部压缩后的标清版,还得保证画质不能太差。
这次的1.58-bit模型,就是在这种压力下的产物。它和同尺寸的全精度模型相比,推理时能释放约6倍的显存空间。换句话说,原来只能装10亿参数模型的手机,现在能装下60亿参数的大模型。而且它的训练开销只有5%,相当于你花了几乎同样的时间,却做出了6倍小的模型。
更重要的是,这是国内首次在国产算力平台上实现的端到端极低比特量化训练。研发团队只用了三周时间,就完成了对华为昇腾平台的适配,这意味着我们不用再依赖国外的算力平台,就能做出高效的压缩模型。
当然,极低比特量化技术也不是完美的。模型参数越小、位宽越低,能存储的知识就越少,而且能力下降不是线性的,而是可能出现“断档式”下滑。比如0.5B的小模型,能力保留率只有90.1%,而8B的大模型能保留95.7%的能力。这就像你把一本1000页的百科全书压缩成100页,可能会漏掉一些不太常用的知识。
研究者们也在想办法解决这个问题:比如用更精细的课程学习体系,让模型先学基础再学复杂知识;或者针对性地补全基础能力,就像给压缩后的口袋本,再配上一本关键知识点的小册子。
而且现在的技术还只是停留在1.58-bit,未来还有可能向更低的比特位发展,比如1-bit甚至更低。但这也意味着更大的挑战:如何在极致压缩的情况下,依然保持模型的能力。就像你要把一本百科全书压缩成一张明信片,还得保证别人能看懂上面的内容。
当内存价格的暴涨给行业带来压力时,反而催生了更高效的技术。这似乎是科技发展的一个常态:当一条路走不通的时候,往往会逼出一条新的路。
极低比特量化技术的意义,不仅仅是让手机能跑更大的模型,更是让AI从云端走向了端侧,真正走进了我们的日常生活。未来,我们可能不需要依赖网络,就能在手机上享受到大模型的智能服务;我们的智能家居、智能手表,甚至是智能汽车,都能运行自己的大模型,变得更加聪明。
压缩的是模型,释放的是智能的边界。 当AI不再被局限在服务器的机房里,而是能装进口袋里的时候,真正的智能时代,才刚刚开始。