对抗知识焦虑,从看懂这条开始
App 下载
光学计算迎革命:缩小90%如何引爆AI算力?
摩尔定律|能耗瓶颈|李彦栋|康奈尔大学|光学计算|AI算力|人工智能
对抗知识焦虑,从看懂这条开始
App 下载摩尔定律|能耗瓶颈|李彦栋|康奈尔大学|光学计算|AI算力|人工智能
人工智能的浪潮正以前所未有的速度席卷全球,但在这场智能盛宴的背后,一个巨大的阴影正悄然笼罩——算力的瓶颈与惊人的能耗。训练一个大模型所消耗的电力,足以驱动一辆汽车往返月球数次;支撑我们日常AI应用的数据中心,正变成一座座吞噬能源的巨兽。传统的电子计算,遵循了数十年的摩尔定律,正逼近其物理极限。晶体管越来越小,热量却越来越高,电子在铜线中的奔跑,似乎已力不从心。我们迫切需要一场计算范式的革命。如果,计算的载体不再是电子,而是光呢?
近日,这场革命的号角在美国康奈尔大学被吹响。一个由博士后李彦栋主导的团队,成功为笨重的光学计算机完成了一次颠覆性的“减肥手术”。他们将光学神经网络的物理尺寸缩小了超过90%,某些情况下甚至压缩至传统设计的1%,而其核心的计算性能——推理准确率,几乎毫发无损。这一突破意味着,过去只存在于大型实验室中的光学计算设备,如今有了装进我们口袋的可能。一个能在智能手表上以光速思考的AI助手,一套能赋予汽车匹敌人类视觉的系统,这些科幻场景正加速向我们驶来。
长期以来,光学计算的巨大潜力与其庞大的体积形成了鲜明对比。它天生拥有电子计算难以企及的优势:
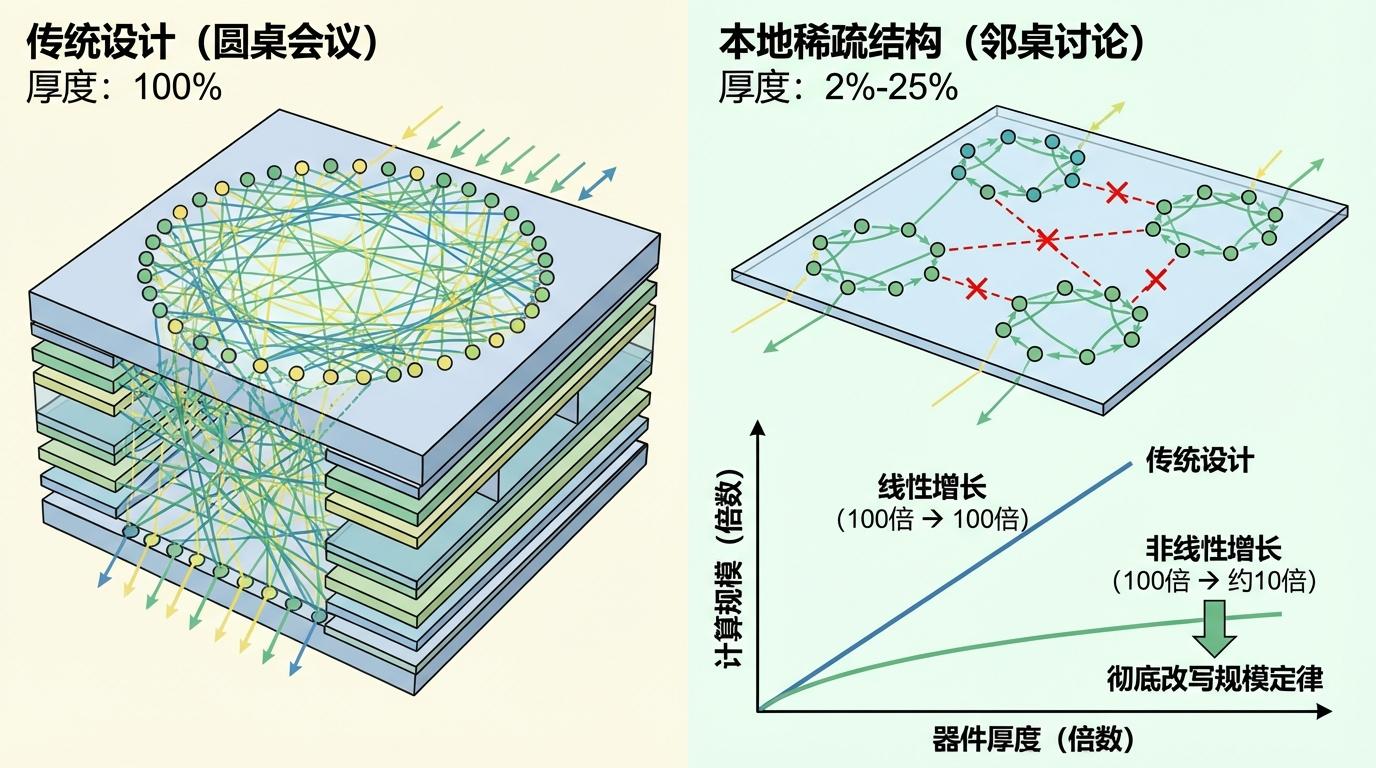
然而,这些优势被一个“肥胖”的诅咒所束缚。光学计算依赖于“非定域性”,即一个输出结果需要综合多个空间位置的输入信息。这就像一场复杂的圆桌会议,每个人都需要听到远处多个人的发言。为了让这些信息通路互不干扰,只能不断增加会议室的“层高”(即器件厚度),导致设备变得又厚又大。
李彦栋的破局灵感,恰恰来自AI领域自身。他注意到,在AI模型优化中,一种名为**“神经网络剪枝”**的技术被广泛应用,它通过剔除冗余的神经元连接,在不影响性能的前提下,大幅缩小模型规模。李彦栋敏锐地意识到,这个思想可以被“翻译”到物理世界:在光学计算中,真正需要“剪掉”的不是虚拟的参数,而是实实在在的物理尺寸。
围绕这一核心思想,李彦栋针对两种主流的光学计算平台,提出了面向物理约束的“剪枝”策略,堪称对光路的一次“精装修”。
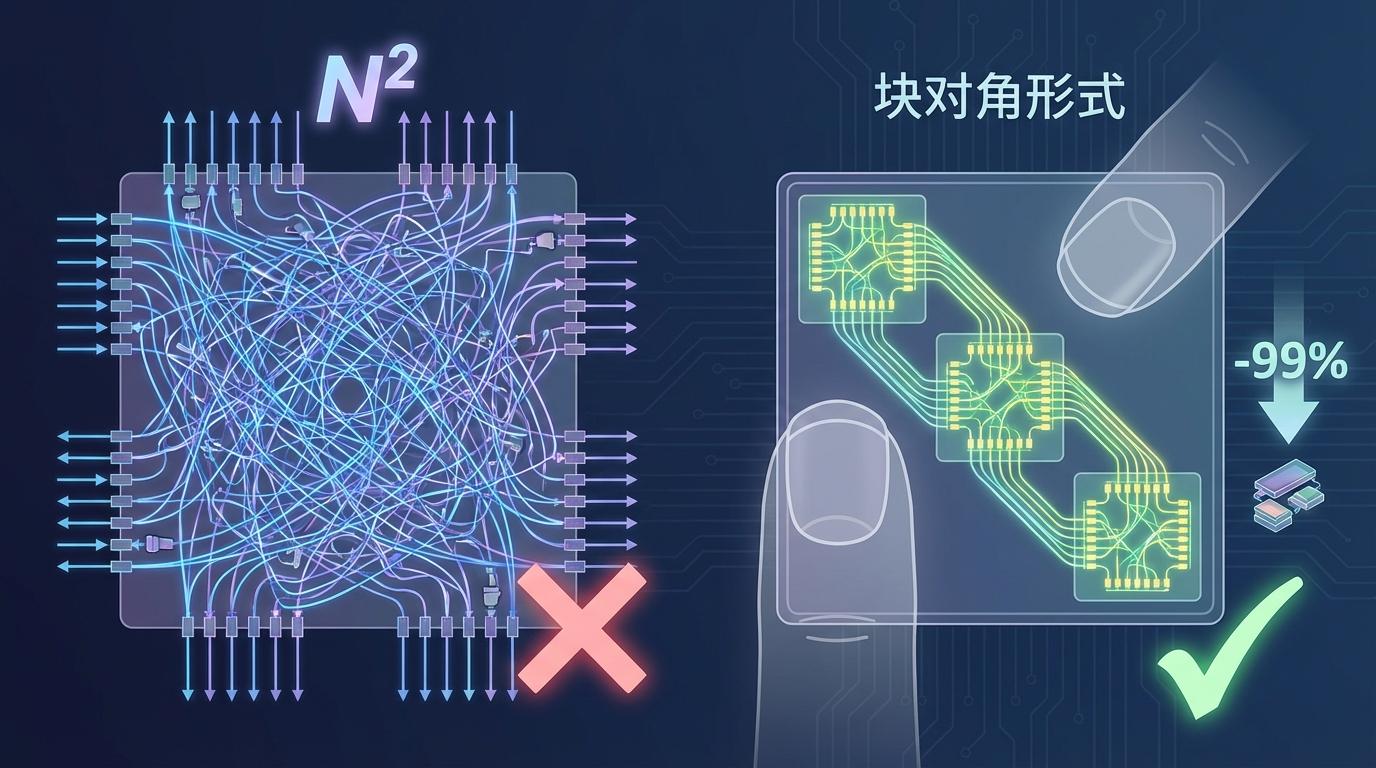
为了验证其有效性,团队将一个小型化的光子芯片模块,成功替换了经典目标检测模型Faster R-CNN中的大规模矩阵运算。结果,超过60%的GPU侧参数被移除,大大减轻了电子计算核心的负担。
康奈尔大学的突破并非孤例,它是一场全球光计算竞赛的缩影。在中国,清华大学戴琼海院士团队研发的“太极”(Taichi)系列光芯片,能效比顶级GPU高出数千倍;上海交通大学陈一彤团队研制的“LightGen”全光芯片,首次实现了大规模语义视觉生成,在指甲盖大小的芯片上集成了超过210万个光学神经元。放眼海外,Lightelligence、Lightmatter等公司已经推出了光电混合计算产品,在特定任务上展现出数百倍于GPU的速度。
这场小型化革命,正将光学计算从实验室的“巨无霸”推向商业化的“引爆点”。市场预测,到2034年,光学计算市场规模有望超过30亿美元。它不再是遥远的未来科技,而是正在重塑AI算力格局的现实力量。
小型化、可扩展的光学神经网络,不是终点,而是通往更深层次问题的起点。李彦栋展望,未来光学计算或许能像今天的量子计算一样,构建起云平台,让全球的开发者都能低门槛地接触和使用这种全新的计算资源,催生出直接适配光学硬件的原生算法。
更激动人心的畅想在于,未来的AI模型或许能够自主“理解”物理规律、任务目标与资源限制,演化为具备完全自动优化能力的智能体。到那时,算法将不再仅仅运行于硬件之上,而是与物理系统协同进化,共同设计出最高效的计算形态。这不仅是硬件的革命,更是对智能本质的一次深刻探索,为万物互联的智能时代,打开了前所未有的想象空间。