对抗知识焦虑,从看懂这条开始
App 下载
AI能看懂数学题图片,却算不出正确答案
AI推理错误|MATH500数据集|视而不思|阿里安全|浙江大学|多模态视觉|人工智能
对抗知识焦虑,从看懂这条开始
App 下载AI推理错误|MATH500数据集|视而不思|阿里安全|浙江大学|多模态视觉|人工智能
给AI出一道小学数学题:如果输入纯文字,它能秒算出正确答案;但把同样的题目转成高清图片再输入,它能精准识别图里的每一个数字和符号,最后却给出一个错得离谱的结果。
浙江大学和阿里安全的研究团队把这种诡异的现象命名为“视而不思”——模型的“眼睛”没问题,“脑子”却在视觉输入时突然“罢工”。更关键的是,他们在MATH500数据集的受控实验里发现,70%左右的失败案例都不是因为看错了,而是纯粹的推理错误。这就像一个学生能认出试卷上的所有字,却完全不会解题。为什么视觉输入会成为AI推理的“隐形障碍”?
要搞懂这个问题,得先拆解AI的“大脑结构”——这次出问题的是多模态MoE模型,简单说就是把AI拆成了好多个“专业专家”,比如专门处理视觉的“图像专家”、专门算数学的“推理专家”,还有一个“路由器”负责给不同的输入分配对应的专家。这种设计本来是为了高效分工:看图片找图像专家,做推理找数学专家。
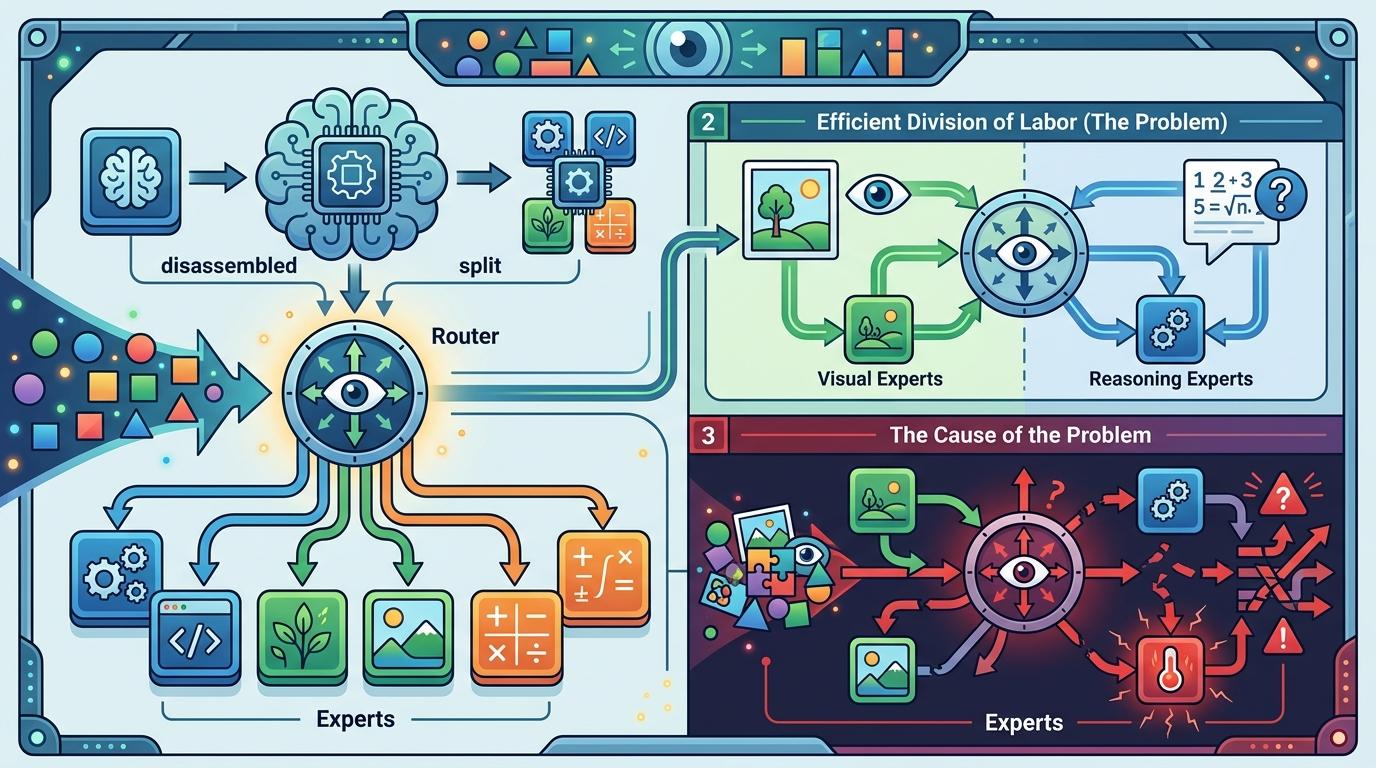
研究团队先排除了最直观的猜想:是不是图片和文字的语义没对齐?他们做了个跨模态干预实验,把纯文字里的数字“灵魂”注入图片的数字“外壳”,结果发现模型中间层的语义共享成功率超过90%——也就是说,AI完全知道图片里的数字和文字里的是一回事。
真正的问题出在“路由器”上。他们用基尼系数分析专家的特化程度,发现了一个清晰的层级分工:图像专家集中在模型的早期和末尾层,负责处理视觉编码和输出准备;而数学推理专家全挤在中间层,正好是跨模态语义共享的核心区域。更要命的是,这两类专家在中间层几乎没有重叠。
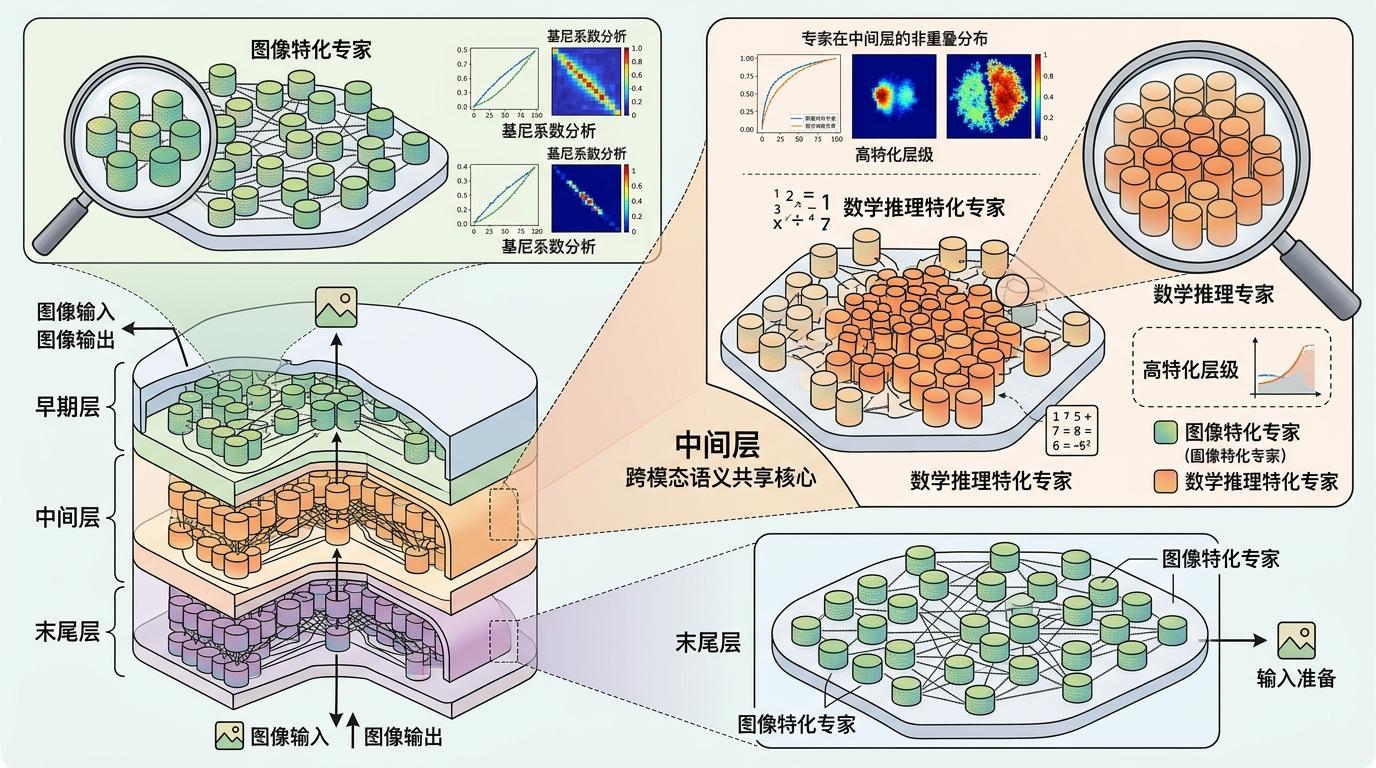
当AI处理图片版的数学题时,“路由器”会先把信号分给早期的图像专家——这本来没问题,但视觉信息带来的干扰,会让路由器在中间层“分心”:本该分配给推理专家的计算资源,被错误地分给了和推理无关的专家。
研究团队用Jensen-Shannon散度量化了同一道题的文字版和图片版在专家激活上的差异,结果呈现出一个明显的U型曲线:早期和末尾层的分歧本来就大,但中间层的分歧和视觉输入的复杂度直接挂钩——图片越复杂,中间层的路由分歧就越大,对应的推理准确率就越低。比如三个视觉复杂度递增的版本,推理准确率分别是89.0%、88.2%、87.4%,而纯文字版本的准确率是92.8%。
这就是他们提出的“路由分心假说”:视觉模态本身不会损害AI的推理能力,但会干扰路由器的分配决策,让AI找不到真正能解题的那个“专家”。说直白点,就是考试时找错了同桌抄答案。
找到了问题根源,解决方法就很直接:给路由器“提个醒”,让它别忘了激活推理专家。研究团队设计了两种干预方式:软干预是给推理专家的激活权重加个“buff”,硬干预是直接强制路由器选择推理专家。
实验结果很明确:软干预在所有模型和任务里都实现了稳定提升,平均准确率提高1.5%,在复杂的MathVerse任务上最高提升了3.17%;而硬干预的效果不稳定,甚至在有些模型上起了反作用。更关键的是,随机给无关专家加buff的对照组几乎没有提升,这说明性能提升确实来自于激活了正确的专家,而不是简单的扰动。
当然,这种方法也有局限:它只对“看得懂但不会算”的场景有效,如果任务本身需要先从复杂图片里提取信息,比如从一堆场景图里找数字,那路由引导的作用就很有限。而且专家识别对任务类型很敏感,用基础算术的专家去解决几何题,不仅没用还可能拖后腿。
这次研究最有意思的地方,是它戳破了一个关于AI的错觉:我们总觉得多模态模型能“像人一样”同时处理视觉和语言信息,但实际上,AI的“看”和“想”可能是两条完全独立的流水线,稍微有点干扰就会脱节。
“路由分心”只是AI推理失败的一个切面,未来我们还得搞清楚,空间关系、几何图形这些复杂视觉概念的语义对齐到底有多难,路由分歧和推理性能之间的精确因果链到底是什么。但至少现在,我们找到了一个能让AI“集中注意力”的小技巧——有时候,让AI好好思考的关键,只是帮它找对那个会解题的“专家”。
看得清,更要找对路。