对抗知识焦虑,从看懂这条开始
App 下载
扩散模型视频超分提速50倍,一步生成不丢画质
快手团队|香港大学|分布匹配蒸馏|视频超分辨率|扩散模型|AIGC|人工智能
对抗知识焦虑,从看懂这条开始
App 下载快手团队|香港大学|分布匹配蒸馏|视频超分辨率|扩散模型|AIGC|人工智能
当你翻出十年前用旧手机拍的旅行视频,想把模糊的画面修复成高清版本时,多半会遇到同一个尴尬:AI修复的画质确实细腻自然,但生成21帧1080P视频要等40多秒——慢到足以让你失去耐心。这正是扩散模型做视频超分的死穴:它像一位慢工出细活的画家,要反复迭代几十步才能画出逼真细节,计算量大到离谱。但现在,香港大学、华中科技大学和快手团队的研究者,把这个‘慢画家’改造成了‘速涂大师’:同样修复21帧1080P视频,只需要0.84秒,速度提升50倍,画质还能打平甚至超越原模型。他们是怎么做到的?
要理解这个提速的核心,得先搞懂「分布匹配蒸馏(DMD)」——这是当前扩散模型加速的主流思路,你可以把它看作一场特殊的师徒教学:传统的蒸馏是让学生一步步模仿老师的作画步骤,而DMD只要求学生最终画出来的‘画风’,也就是图像的数据分布,和老师一模一样。
但直接把这套方法用到视频超分上,会立刻踩进三个大坑:一是学生一开始画的东西和老师的画风天差地别,训练时梯度剧烈震荡,根本学不进去;二是被冻住的老师模型,对学生画的‘半成品’可能给出错误指导,把学生带偏;三是学生最多只能学到老师的水平,永远突破不了老师的天花板。
DUO-VSR的第一步,就是用「渐进式引导蒸馏」解决训练不稳定的问题。他们没让学生直接挑战老师的最终作品,而是先让学生临摹老师作画的中间步骤,从多步生成慢慢过渡到单步生成,先练出一个能稳定画出及格线作品的‘入门学生’。这就像让新手先学画线条和色块,而不是直接临摹梵高的星空。
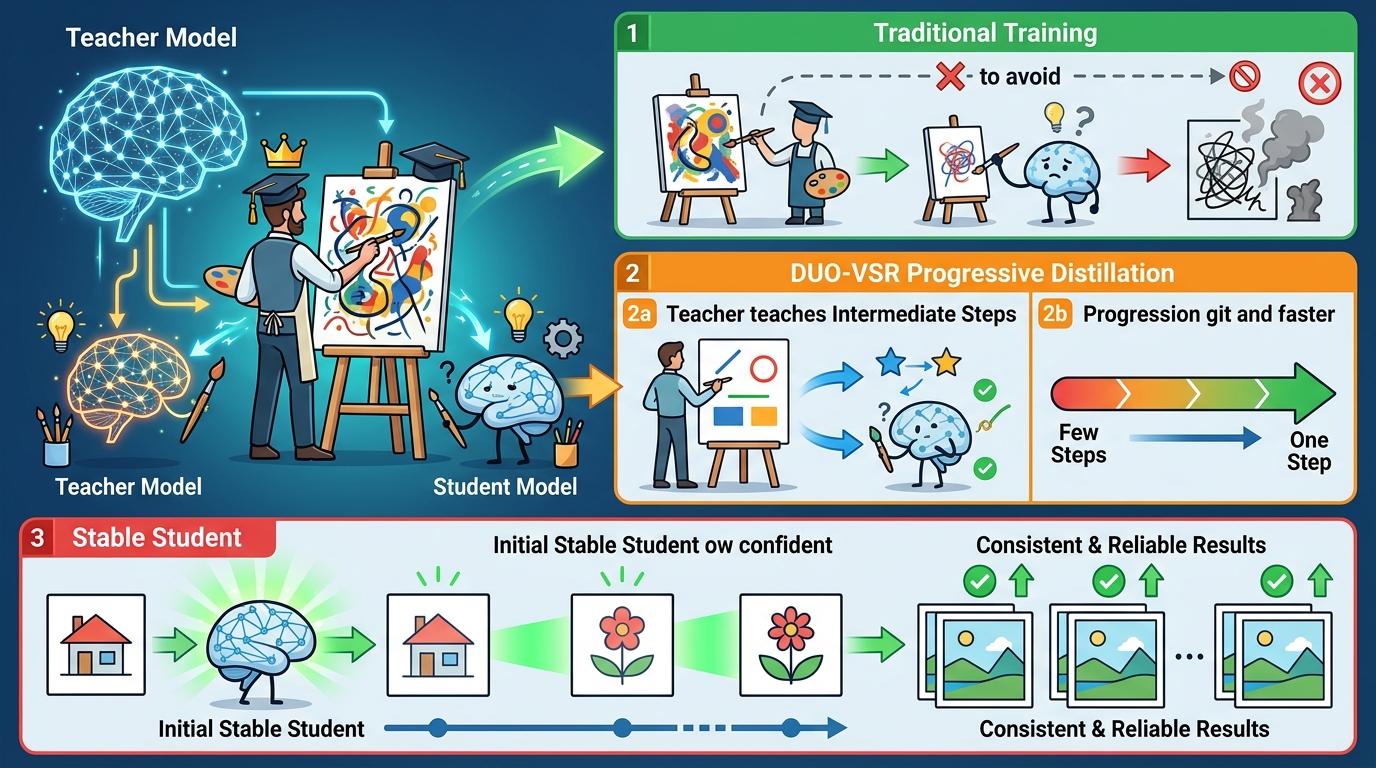
真正的突破,来自他们提出的「双流蒸馏」——给DMD配上了一个叫RFS-GAN的‘纠偏教练’,两条路线同时指导学生学习。
DMD流负责打基础:它盯着学生的最终作品,确保整体画风和老师一致,相当于给学生定了个不能跑偏的基本盘。而RFS-GAN流则负责补短板:它引入了一个特殊的判别器,这个判别器不直接看整张画,而是拿着老师作画时的‘草稿’(也就是老师模型内部的真/假分数特征)来做对比——它把加了噪声的真实高清视频当‘真迹’,把学生的作品当‘仿品’,让学生在和判别器的对抗中,学会画出更接近真实世界的细节。
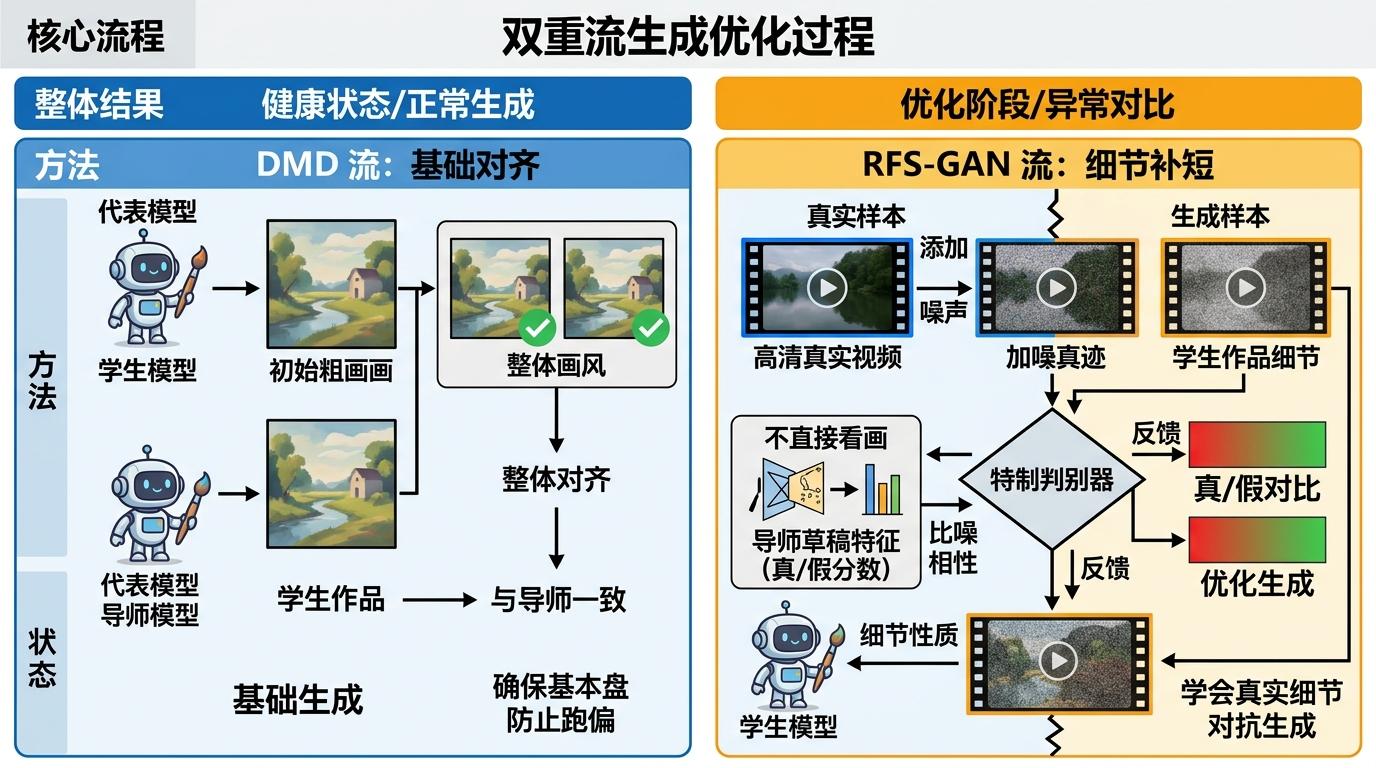
这个设计的妙处在于三点:一是它用真实视频打破了老师模型的天花板,让学生能学到比老师更好的技巧;二是当DMD流的老师给出错误指导时,GAN流能及时把学生拉回正轨;三是它直接复用了老师模型的内部特征,不用额外训练庞大的新网络,效率极高。训练时,两条流交替工作:先让学生结合DMD和GAN的反馈调整画风,再更新判别器的标准,形成一个互相促进的闭环。
用数据说话的话,在处理21帧1080P视频时,DUO-VSR的单步推理时间仅0.84秒,比需要50步的原模型快了50多倍;在视频感知质量指标DOVER上,它在多个数据集上都拿到了第一或第二的成绩,帧间稳定性指标E*warp也做到了最低——意味着修复后的视频不会出现闪烁和抖动。
解决了速度和画质的硬指标,DUO-VSR还补上了最后一块短板:主观观感。毕竟,画质好坏不止看数据,还要符合人类的审美。
他们用第二阶段训练好的模型,给同一段低清视频生成多个高清版本,再用视频质量评估模型给这些版本打分排序,形成一个‘哪个更好看’的偏好数据集。最后用直接偏好优化(DPO)技术微调模型,让它更倾向于生成人类觉得好看的画面——比如更自然的肤色、更舒服的色彩对比度。实验显示,经过这一步微调后,用户对视频的主观满意度提升了10%以上。
当然,这套方法也不是完美的:它高度依赖初始老师模型的质量,训练时需要83万对高质量视频数据,整个三阶段蒸馏流程也得消耗大量计算资源。但不可否认的是,它找到了一条在速度和画质之间平衡的可行路径——这正是当前AI视频技术最需要的东西。
从需要几十步迭代的‘慢画家’,到一步生成的‘速涂大师’,DUO-VSR的本质,是用更聪明的训练策略,把扩散模型的能力‘压缩’到了一个轻量高效的框架里。它没有追求‘颠覆性’的突破,而是在现有技术的基础上,把‘平衡’做到了极致——这恰恰是能真正落地到我们生活中的技术该有的样子。
快与好,从来不是二选一的题。 当AI视频修复能在一秒内完成,我们手机里那些模糊的旧视频,那些被遗忘的生活片段,才能真正重新变得清晰鲜活。