对抗知识焦虑,从看懂这条开始
App 下载
低带宽也能看高清视频?交大团队搞懂了关键
高清视频传输|低码率传输|视频压缩|Diff-SIT技术|上海交通大学|AI产业应用|人工智能
你一定遇过这种糟心时刻:地铁里刷直播,画面卡成马赛克;山区打视频电话,亲人的脸糊成一团;为了省流量,被迫把1080P调成“流畅”画质——结果连演员的表情都看不清。过去我们默认,低带宽和高清视频是天生的敌人,要么省流量牺牲画质,要么耗流量追求清晰。但上海交通大学的团队最近拿出的Diff-SIT技术,让这个默认规则失效了:在每像素仅0.03比特的极低码率下,它既能把视频体积压缩到极致,又能让画面细节清晰、动作流畅。这到底是怎么做到的?
先省流:只传“骨架”和“动作指令”
要搞懂Diff-SIT的巧思,得先明白传统视频压缩为什么在低码率下会糊。过去的压缩技术,要么把每一帧都“磨皮”到模糊来省数据,要么用生成模型逐帧补细节,但要么慢得离谱,要么补出来的细节在帧之间“跳来跳去”,导致动作卡顿。
Diff-SIT的第一个核心模块STEM,相当于给视频做了一次“极简主义编辑”:它把视频每3帧分成一组,只给中间那帧(骨干帧)做完整的高质量编码,这是视频的“骨架”——保证画面的核心结构清晰;而剩下的帧(MV帧),它连完整画面都不传输,只传一组“动作指令”:光流。
你可以把光流想象成给骨干帧的每个像素点标上箭头,告诉解码端“这个像素要往左移3格,那个要往上移2格”。解码端拿到这些箭头,直接“扭动”骨干帧就能还原出其他帧的大致轮廓。关键在于,每个MV帧只参考最近的那个骨干帧,绝不搞“帧参考帧再参考帧”的长链——这样就避免了误差像滚雪球一样越积越大,哪怕是粗糙的还原,也能保证动作的基本连贯。
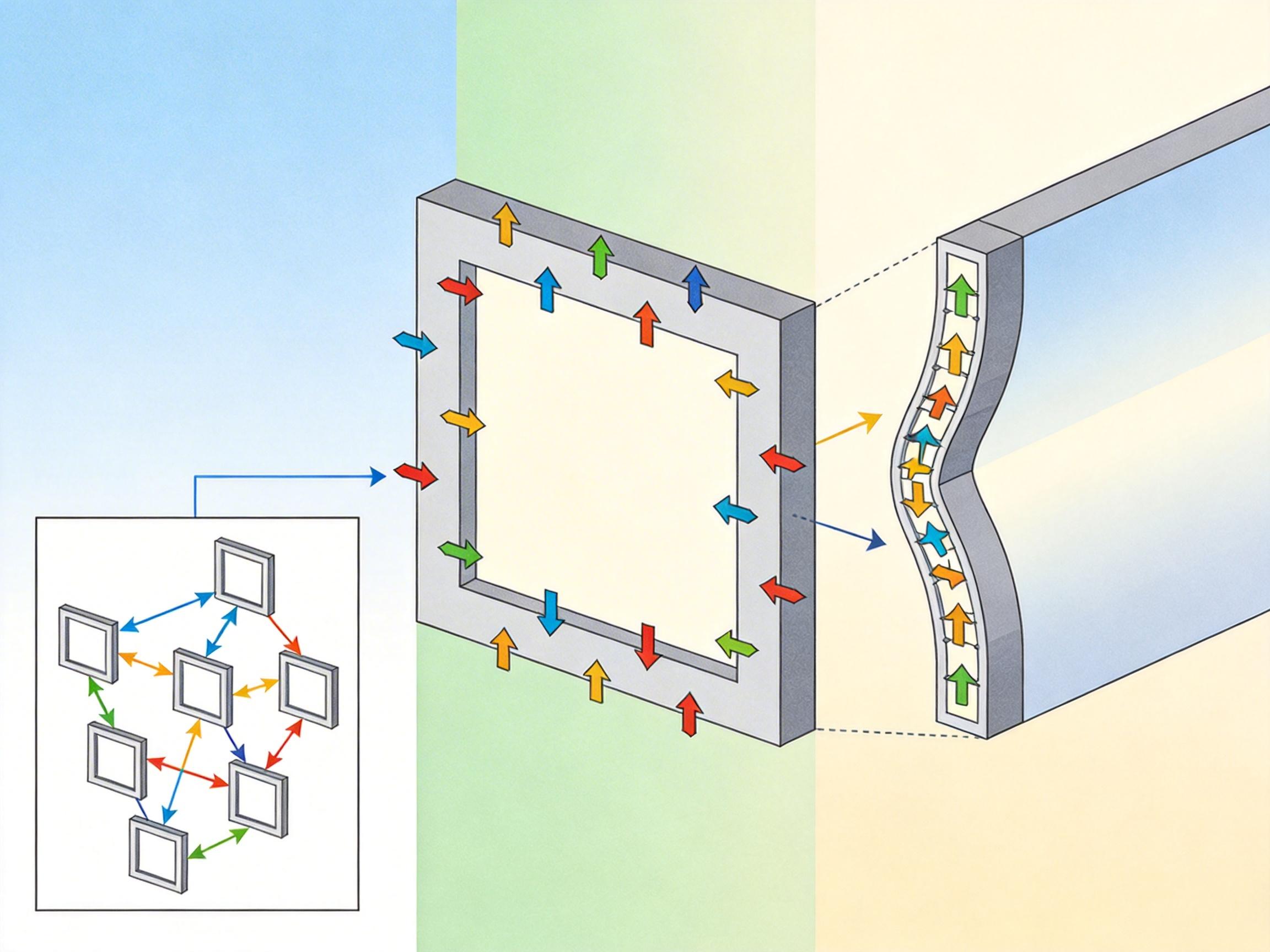
这种策略直接砍掉了大部分冗余数据:骨干帧只占总帧数的三分之一,MV帧只传光流,码率一下就降了20%以上。
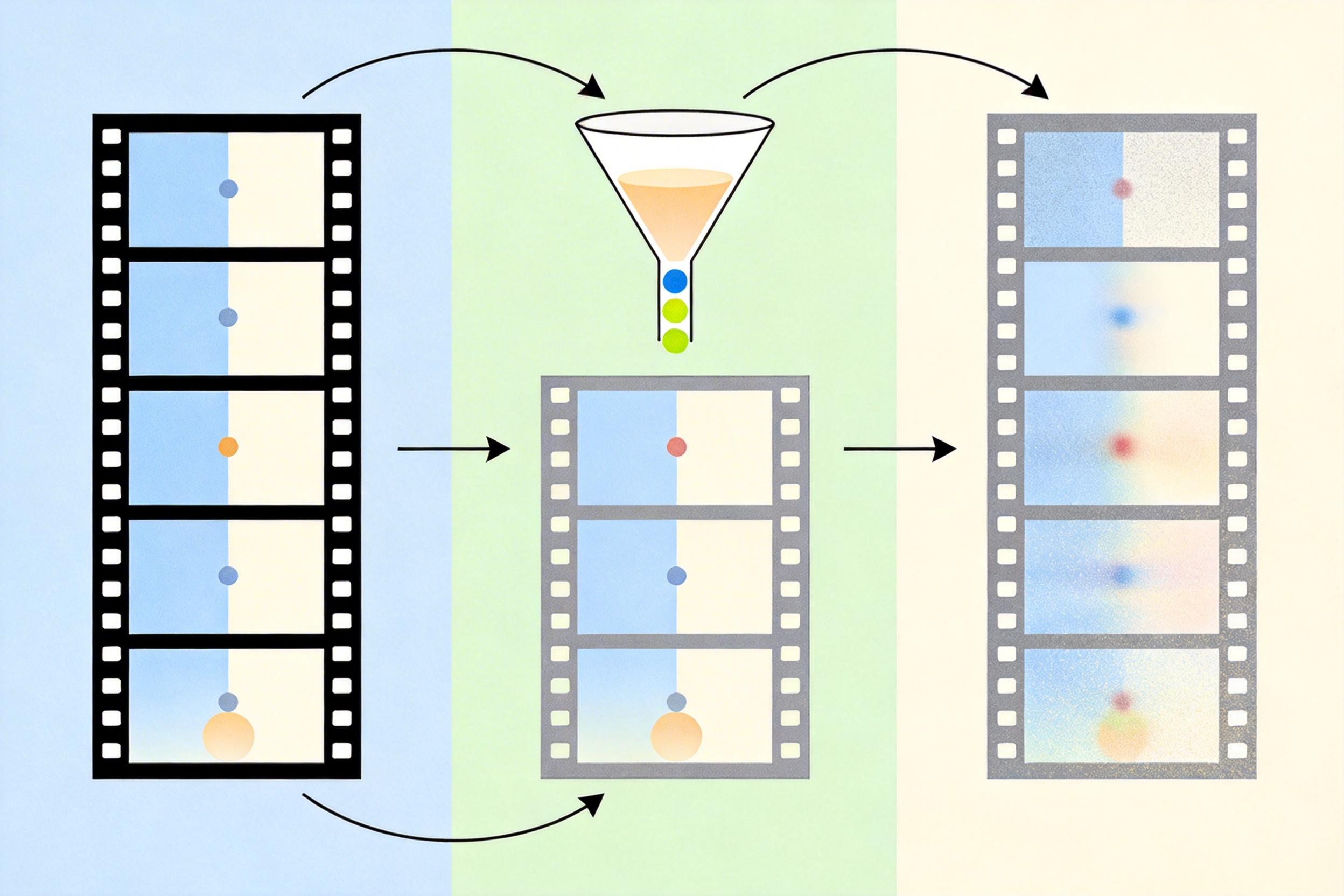
再补细节:一次“精修”搞定所有帧
有了粗糙的“半成品”视频,接下来要解决的就是“怎么快速补细节”。传统的扩散模型生成画面,得像剥洋葱一样几十次迭代去噪,慢到根本没法用在实时场景里。Diff-SIT的第二个核心模块ODFTE,就解决了这个效率问题。
它的思路很简单:既然STEM已经给出了视频的骨架和动作,那根本不需要“从无到有”生成画面,只需要“精修”就行。研究者发现,只要把扩散模型固定在一个合适的噪声时间步,只做一次去噪操作,就能把粗糙画面里的细节补全,还能让帧与帧之间的动作更流畅。这一下就把生成速度提升了几十倍。
更聪明的是“帧类型嵌入器”的设计:它会给每帧打上标签——“我是骨干帧”“我是MV帧”。扩散模型看到标签后,会自动调整修复策略:对本来就清晰的骨干帧,只做轻微的纹理增强;对靠光流扭动出来的MV帧,就全力补细节、校正扭曲。这种“因材施教”的修复,让整个视频的质量一下子拉满了。
实验数据最有说服力:在感知质量指标LPIPS和DISTS上,Diff-SIT全面超过了传统编码器和其他生成式压缩方法;在衡量动作流畅度的Ewarp指标上,它的表现更是甩了同类方法一条街。
但它离我们的手机还有点远
不过,Diff-SIT也不是完美的。它目前最大的短板,就是“太吃算力”。ODFTE模块用到的是1.3B参数的视频扩散大模型,哪怕是一次去噪,也得靠高性能GPU才能跑起来——想直接装在手机、智能手表这些边缘设备上,现在还不现实。
更值得关注的是,它的“单跳光流”策略在遇到极端场景时会失效:如果画面里有快速旋转的物体,或者突然出现的遮挡,光流估计就会出错,还原出来的画面可能会变形。而且,生成式模型天生的“幻觉”问题也没解决——它补出来的细节,有时候可能和原始视频不一样,这对医学影像、安防监控这种要求绝对准确的场景来说,还是个隐患。
但这些问题,更像是前进路上的“待优化项”,而非致命缺陷。它真正的价值,是给生成式视频压缩指了一条明路:不用在“省流”和“画质”里二选一,把传统压缩的“运动补偿”思路和AI生成的“细节修复”能力结合起来,就能两头兼顾。
当我们还在为“低带宽看不了高清”发愁时,Diff-SIT已经证明,这件事的破局点从来不是“要不要牺牲”,而是“怎么聪明地分配资源”——把宝贵的码率用在关键帧上,再用AI的力量补全细节。
未来也许不用太久,我们在地铁的弱信号里、在偏远山区的基站下,都能流畅地看高清视频;云游戏的延迟会更低,远程会议的画面会更清晰。更重要的是,这件事让我们看到:AI不是用来“颠覆”传统技术的,而是用来“补全”传统技术的短板的。
省流不糊帧,AI补全最后一公里。