对抗知识焦虑,从看懂这条开始
App 下载
AI不会自学?人类婴儿给了科学家新答案
婴儿模仿机制|自主学习|加州大学伯克利分校|纽约大学|Meta|大语言模型|人工智能
对抗知识焦虑,从看懂这条开始
App 下载婴儿模仿机制|自主学习|加州大学伯克利分校|纽约大学|Meta|大语言模型|人工智能
你给家里的扫地机器人下达“整理玩具”的指令,它却只会原地打转——这不是科幻电影的玩笑,是当前AI的真实困境。我们训练出能通过司法考试、生成逼真画作的AI,却造不出一个能像11个月大婴儿那样,看一眼就学会模仿收拾玩具的机器。2026年春天,Meta、纽约大学和加州大学伯克利分校的联合研究捅破了这层窗户纸:当前AI的“阿喀琉斯之踵”,是根本不会自主学习。而破解答案,藏在人类婴儿与生俱来的学习机制里。
现在的AI更像被提前灌满知识的罐头——训练时靠工程师投喂标注好的海量数据,部署后就彻底“冻住”了学习能力。想让它学新技能?得重新收集数据、调整模型、再走一遍繁琐的训练流水线,就像把成年的巨婴送回摇篮重新喂养。
而人类婴儿的学习是动态的:他们会盯着大人的动作观察规律,会动手试错摸索玩法,会在遇到瓶颈时停下来“思考”,还能灵活切换这些模式。这种自主、持续、多模式交织的能力,才是智能的核心。论文里把这种能力拆解成了两大基础系统:负责被动观察、从数据里提炼规律的System A,和负责主动试错、通过反馈优化行为的System B。
但当前AI的问题是,这两个系统长期“各玩各的”:自监督学习的模型能看懂世界,却不知道怎么动手;强化学习的机器人能行动,却要靠百万次试错才能学会简单动作,样本效率低到离谱。
论文提出的A-B-M架构,就是要给这两个“各干各的”系统加个总指挥——System M,也就是元控制系统。它就像大脑里的“执行功能”,能实时监控A和B的状态:当A的预测误差变大,说明遇到了新东西,就指挥B去主动探索;当B的奖励停滞不前,就调动A的观察数据帮它优化策略。
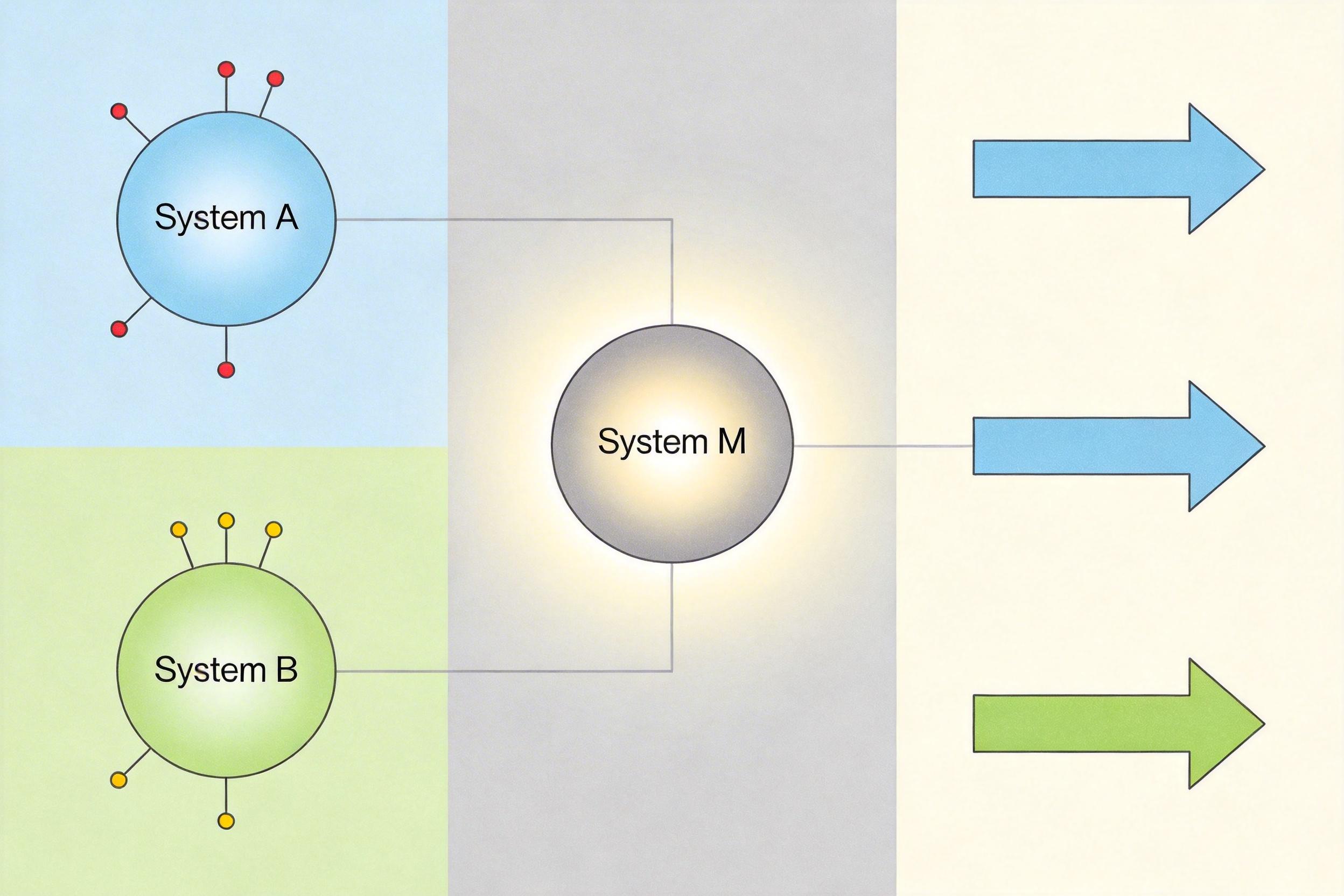
你可以把这个过程想象成学做饭:System A是你看菜谱、记步骤的记忆,System B是你动手翻炒、调味的动作,而System M就是那个随时调整的“直觉”——尝一口发现盐放少了,就提醒你加一点;看到菜谱里的步骤和实际操作不符,就帮你灵活调整。
更关键的是,这个架构不是靠人类预设好规则,而是靠“进化-发育”的双层优化来驱动。进化层负责通过算法迭代,筛选出“天生善于学习”的初始架构;发育层则让智能体在和环境的交互中,像人类婴儿一样逐步积累经验、优化能力。这就像大自然通过亿万年进化出人类的大脑结构,再让每个个体在成长中学会学习。
Meta开发的Shachi框架已经初步验证了这个思路:把LLM拆成配置、记忆、工具和推理引擎四个模块,让智能体能在不同任务间自主切换策略,甚至能模拟人类的经济行为和社会交互,表现出了前所未有的灵活性。
这个架构的设想很美好,但落地还有三座大山要翻。首先是计算成本:进化层的架构筛选需要模拟海量智能体的生命周期,计算量远超当前大模型的预训练,只有顶尖机构能负担得起。其次是元控制系统的稳定性:怎么让M准确判断A和B的状态,怎么平衡观察和行动的资源分配,目前还没有成熟的解决方案。最后是伦理风险:当AI能自主学习、自我进化时,怎么保证它的行为符合人类的价值观,怎么避免它“学坏”或者失控?
更现实的挑战是样本效率的问题。现在的强化学习机器人学走路要摔几百万次,而人类婴儿只需要几次尝试就能找到平衡。论文里提到的“世界模型”思路——让AI在“脑内”模拟环境进行试错,虽然能减少真实世界的样本消耗,但模拟环境和真实世界的差距,始终是难以逾越的鸿沟。
这篇论文没有给出一个能直接落地的模型,更像一份指向未来的“思想纲领”。它提醒我们,AI的未来不是靠堆参数、堆数据,而是要回到智能的本质——像人类一样,学会自主学习、持续成长。
当我们把目光从大模型的参数规模转向认知科学的底层逻辑时,或许会发现,真正的通用智能,从来都不是“灌”出来的,而是“学”出来的。智能的本质,是学习如何学习。
未来的某一天,当机器人能像婴儿一样,看一眼就学会新技能,能在复杂的真实环境里自主适应,我们或许会意识到,这一切的起点,是我们终于愿意低下头,向那个只会爬、只会哭的小婴儿,偷师学习。