对抗知识焦虑,从看懂这条开始
App 下载
跨百台MRI设备配准,HACA3+破解影像统一难题
约翰斯·霍普金斯大学|多发性硬化|域偏移|MRI配准|HACA3+算法|计算科学|临床诊疗技术|数理基础|医学健康
对抗知识焦虑,从看懂这条开始
App 下载约翰斯·霍普金斯大学|多发性硬化|域偏移|MRI配准|HACA3+算法|计算科学|临床诊疗技术|数理基础|医学健康
同一位多发性硬化患者,在A医院的MRI显示脑萎缩稳定,到B医院复查却被判定为病情进展——不是病情真的恶化,只是两台不同品牌的MRI扫描仪,把同一处脑组织扫出了天差地别的亮度和对比度。这种被称为「域偏移」的设备差异,是多中心临床研究的噩梦:它会让AI诊断模型在A医院准确率90%,到B医院直接跌到60%,也会让十年随访的脑体积数据彻底失去参考价值。直到约翰斯·霍普金斯大学团队的HACA3+算法出现——它让132台不同品牌、场强的MRI,终于能拍出「同一种语言」的图像。
你可以把MRI图像想象成一份加了滤镜、沾了污渍的解剖图:解剖结构是核心的线条,对比度是滤镜风格,伪影是纸上的污渍。传统配准算法要么硬拉亮度对比度,结果把解剖结构拉变形;要么只去污渍,却管不了滤镜差异。 HACA3+的核心是一套「解剖-对比-伪影三重解耦编码器」——三个独立的AI模型分别干三件事:一个专门提取和设备无关的解剖结构特征,就像把图里的线条单独抠出来;一个捕捉不同扫描序列的对比度风格,比如是暖色调还是冷色调;第三个识别伪影的严重程度,给污渍打个分数。
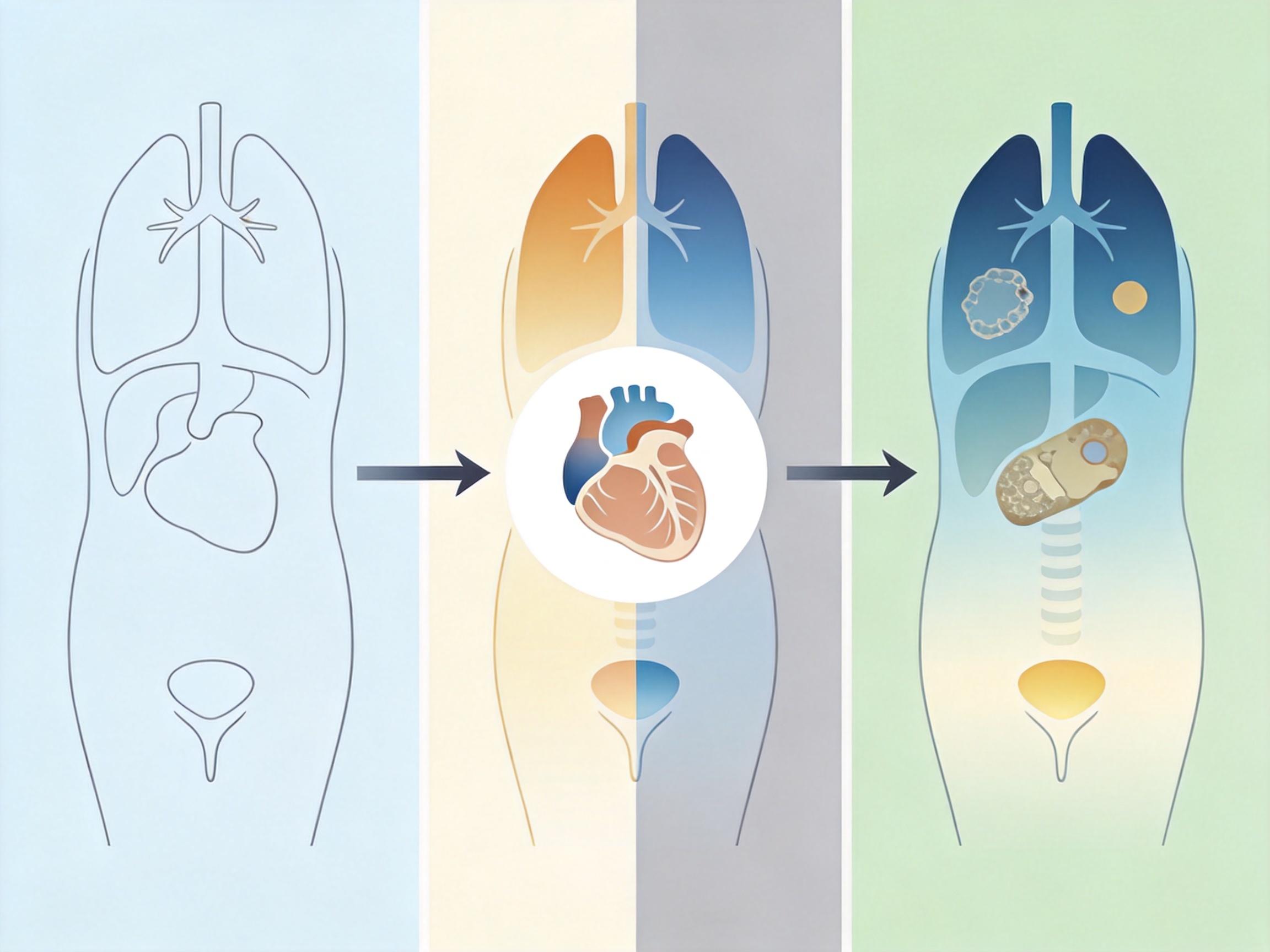
这不是简单的拆分,而是用对比学习让模型明白:不同滤镜下的同一根线条,本质是同一个东西。它会把同一患者不同对比度的图像当成正样本,把不同患者的图像当成负样本,在特征空间里让正样本靠得更近,负样本离得更远。最终,你可以任意组合解剖线条和滤镜风格,生成一张没有污渍、风格统一的标准图像——就像给所有MRI设备装了同一个「标准镜头」。
HACA3的初代版本已经能解决小范围的设备差异,但一到真实临床的「设备丛林」就失灵——毕竟它只在21台扫描仪上训练过。HACA3+的升级,本质是把模型从「小镇青年」培养成「世界公民」。 第一个升级是给伪影编码器装了「精细刻度」。初代模型只能区分「有伪影」和「没伪影」,HACA3+用三元组损失让模型学会给伪影打分:把一张清晰图、轻微伪影图、严重伪影图放在一起,让模型明白三者的轻重顺序。这样它遇到轻微运动模糊和严重鬼影时,能拿出不同的处理策略,而不是一概而论。 第二个升级是给模型加了「空间注意力眼睛」。临床中常遇到患者太胖,MRI只扫到了大脑下半部分的情况,初代模型只会对着缺失的颅顶区域瞎补。HACA3+会先把所有源图像的缺失区域标记出来,然后只从有完整信息的图像里借数据补全——绝对不会无中生有。
最根本的升级是「见过世面」:训练数据从21台扫描仪暴增到132台,覆盖64个站点、996名受试者,从1.5T的老机器到3T的新设备,从健康人到多发性硬化、脑外伤患者,它见过了几乎所有临床能遇到的「奇葩情况」。
算法好不好,得用「旅行受试者」的金标准来测——就是让同一个人背着MRI兼容的装备,去不同医院的不同扫描仪上反复扫描,完全排除个体差异,只看设备差异被消除的程度。 HACA3+过了三道关:第一道是14名患者跑9个站点的TREAT-MS数据集,它处理后的图像,结构相似性指数(SSIM)和峰值信噪比(PSNR)和初代持平,证明升级没丢基础性能;第二道是5名患者跨3-4台设备的MASiVar数据集,它把脑区体积的变异系数从0.04降到0.02,意味着跨设备的测量误差直接减半;最狠的是第三道:让同一个健康人扫遍116台不同扫描仪的FTHP数据集——这相当于让模型直接面对「设备联合国」,结果它依然能把不同设备扫出的大脑,校准到几乎一模一样的程度。 当然它也有局限:目前还只处理2D切片,没用到3D的完整空间信息;遇到极端罕见的伪影组合,还是可能失灵;对儿童、肿瘤患者这类特殊人群的表现,也还需要验证。
当我们谈论医学AI的「泛化能力」时,本质上是在问:这个模型能不能走出实验室,走进千差万别的真实临床?HACA3+给出的答案是,与其在算法上钻牛角尖,不如先让模型见够世面——毕竟临床里的设备差异,比实验室里的模拟场景复杂一万倍。 它的开源代码和预训练权重,给所有做医学影像的研究者铺了一条路:不用再从零开始对付设备差异,直接站在能兼容132台扫描仪的基础上往前走。数据的广度,才是AI临床落地的底气。未来的医学AI,或许不需要最精妙的算法,但一定需要见过最多「世面」的模型。