对抗知识焦虑,从看懂这条开始
App 下载
机器人能预判动作了,却先得了“时间失忆症”
机器人动作理解|动作顺序预测|深度模态混合网络|镜像神经元|多模态视觉|人工智能
对抗知识焦虑,从看懂这条开始
App 下载机器人动作理解|动作顺序预测|深度模态混合网络|镜像神经元|多模态视觉|人工智能
你伸手去够桌上的水杯,刚抬起胳膊,对面的朋友已经下意识地往旁边挪了挪杯子——这是人类刻在大脑里的能力:通过观察片段动作,瞬间预判后续轨迹,甚至读懂背后意图。为了让机器人也学会这种“读心术”,意大利和日本的联合团队盯上了模仿人类镜像神经元的深度学习模型,却撞见了一个哭笑不得的bug:机器人能精准预测动作的每个细节,却完全记不住这些动作的先后顺序。给它看打乱顺序的抬手、抓握、放下,它依然会输出一套完美的流畅动作,像个把电影帧按剧情拼好的剪辑师,哪怕素材本身是乱的。问题出在哪?
团队最初选中的深度模态混合网络(DMBN)是个天生的“潜力股”:它能同时处理视觉图像和机器人关节角度数据,还能像人类看半集剧猜结局一样,直接并行预测未来所有动作,不用像传统模型那样一步步推导、累积误差。但这套看起来完美的架构,却藏着一个致命的设计缺陷——时间信息被当成了可有可无的“附加题”。 你可以把模型的编码过程想象成整理相册:原始DMBN会把“上午9点抬手”“9点01分抓握”这些照片混在一起,只提取“抬手”“抓握”的动作特征,完全忽略照片上的时间戳。它靠记忆中的动作模式来拼接预测,而非理解时间的先后逻辑。 为了确诊这个“失忆症”,团队做了两个狠实验:一是给模型看乱序的动作帧,二是给它看一直停在半空的“冻结动作”。结果毫不意外:乱序输入下,模型依然输出完美的有序动作;冻结输入下,它还在预测手臂会继续移动。更扎心的是,当研究者让模型从编码特征里反推输入的时间点时,它的表现比随机乱猜还差——时间信息根本没被编码进去,直接被过滤了。
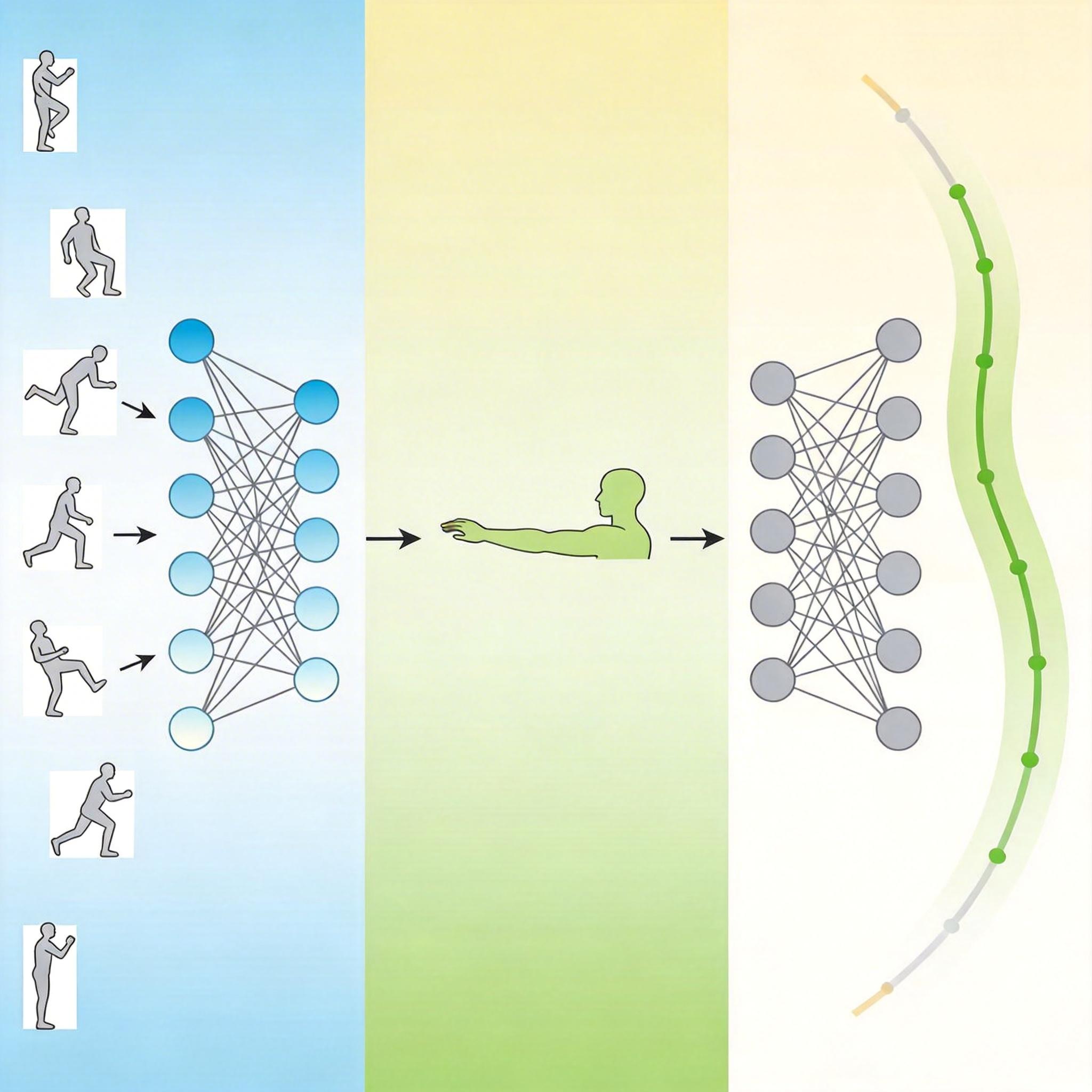
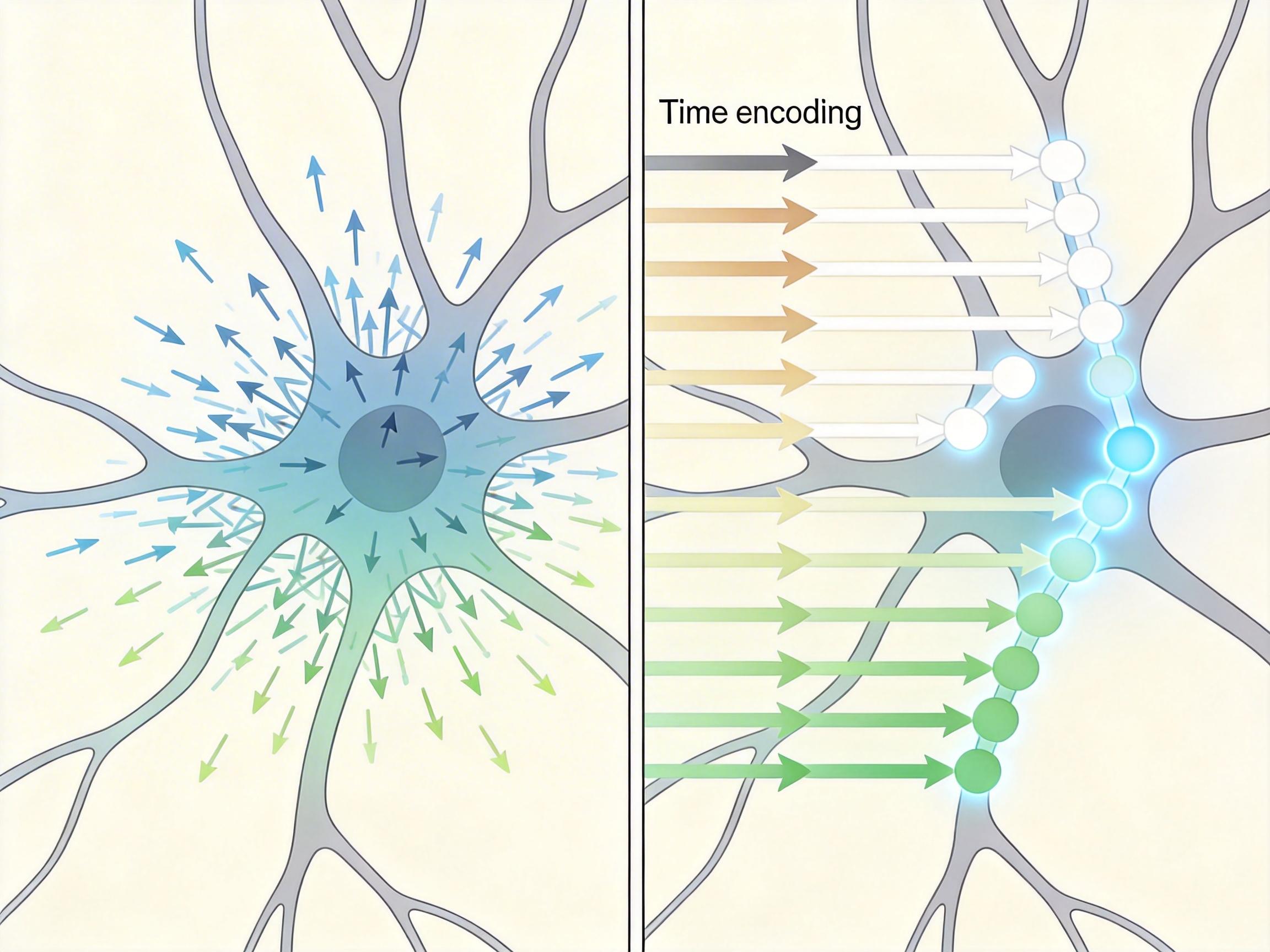
既然时间信息在编码阶段就丢了,那就得把它焊进模型的“记忆”里。团队的目光投向了Transformer——这个靠位置编码解决序列顺序问题的AI霸主。 他们给DMBN加了个极简的补丁:位置时间编码(PTE)。具体来说,就是给每个时间点生成一个独特的“时间水印”,像给相册里的每张照片都盖个带时间戳的钢印,再把这个水印和动作特征融合在一起。编码时,时间水印和动作信息深度绑定;解码时,再通过“减去”未来时间的水印,让模型学会计算时间差,而非只看绝对时间。
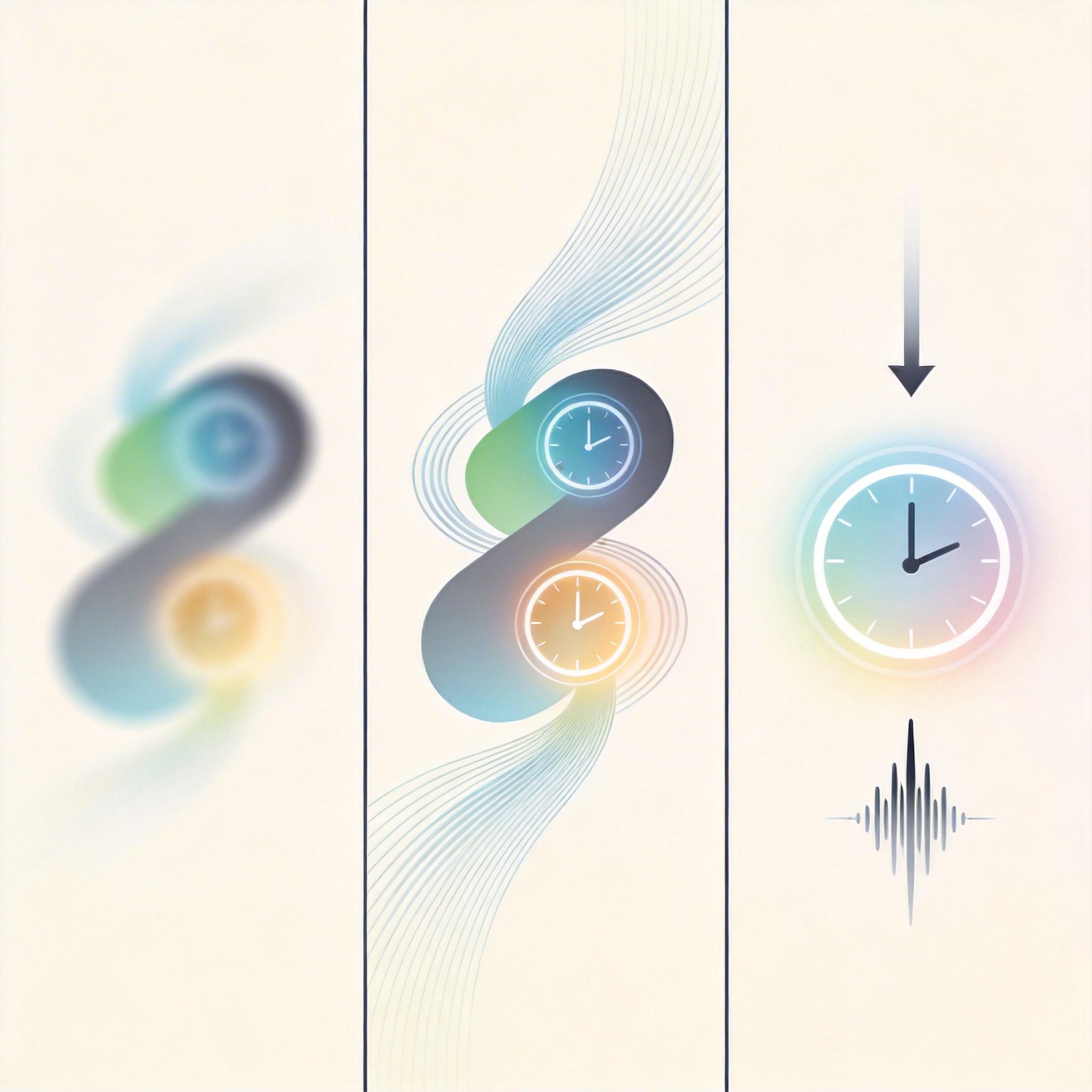
这个改动有多简单?相当于给原本只看画面的剪辑师,配上了精准的场记板。效果却立竿见影:当模型再看乱序动作时,输出终于变得混乱无序,符合输入的逻辑;看冻结动作时,它能准确预测手臂会保持静止。更关键的是,反推时间点的实验显示,模型的时间编码能力提升了几个数量级——它终于能“记住”动作发生的时刻了。
更值得关注的是,这个研究的价值远不止于修复一个模型缺陷,它戳破了AI动作预测领域的一个假象:很多看起来能“理解”动作的模型,其实只是在做高级的模式匹配——它们记住了动作应该是什么样,却没理解动作是怎么随着时间发生的。 这也是为什么很多实验室里表现完美的机器人,一到真实场景就拉胯:真实世界里的动作不会总是按剧本走,人类的抬手可能是要拿杯子,也可能是要挠头,只有理解了时间的动态变化,才能读懂背后的意图。 当然,现在的DMBN-PTE还不算完美:面对乱序输入,它偶尔还是会忍不住输出一些记忆中的“标准动作”,说明对训练数据的依赖还很强。但这一步已经足够关键——从“模式匹配”到“时序理解”,是机器人从“会做动作”到“理解动作”的核心跨越。
我们总说要让机器人像人一样思考,却常常忽略:人类的智能从来不是孤立的片段,而是流动的时间线。我们能预判动作,不是因为记住了每个姿势,而是因为理解了时间如何把姿势串成意图。 这个给机器人“治失忆”的研究,本质上是在给AI补上感知时间的能力——这不是一个酷炫的黑科技,却是让机器人真正融入人类世界的基础。毕竟,能和你同步理解“现在”“接下来”的机器人,才有可能真正懂你。 时间不是附加信息,是智能的骨架。