对抗知识焦虑,从看懂这条开始
App 下载
LeCUN放弃像素重建,AI开始真正理解世界
ThinkJEPA|LeWorldModel|V-JEPA 2.1|JEPA架构|Yann LeCun|大语言模型|人工智能
对抗知识焦虑,从看懂这条开始
App 下载ThinkJEPA|LeWorldModel|V-JEPA 2.1|JEPA架构|Yann LeCun|大语言模型|人工智能
当GPT还在为生成多余的手指道歉时,Yann LeCun的团队已经悄悄换了赛道——他们让AI彻底放弃了还原像素的执念。2026年3月,三篇JEPA架构的论文接连发布:V-JEPA 2.1能在完全陌生的环境里指挥机器人抓举物品,LeWorldModel用1500万参数实现了比大模型快48倍的规划速度,ThinkJEPA甚至能结合语义逻辑完成长周期动作推演。这不是简单的模型升级,而是AI从「复刻像素」到「理解规律」的关键转身。为什么放弃像素重建就能让AI突破物理常识的瓶颈?
你可以把传统生成模型想象成一个只会抄作业的学生——它能精准复刻每一个字,却完全不懂题目的意思。像素重建任务要求AI把图像或视频的每一个像素都还原出来,这就像让学生抄下试卷上的所有标点符号,哪怕是印刷的墨点。
现实世界的信息量里,90%都是无关紧要的噪声:树叶的晃动、光照的明暗、镜头的灰尘。AI耗费大量算力去还原这些细节,反而错过了真正重要的规律——比如杯子会因为重力下落,门会因为被推动而打开。LeCun团队的JEPA架构,就是要让AI从抄作业的学生,变成能推导公式的研究者。
JEPA的核心逻辑很简单:它不预测像素,而是预测像素背后的「抽象特征」。就像你看一场球赛,不需要记住每一个观众的脸,只要能追踪球的轨迹和球员的战术动作就行。在JEPA的隐空间里,一杯咖啡的特征不是棕色的像素点,而是「可以被拿起的容器」「装有液体」「会因为倾斜而流出」这些抽象属性。
如果说JEPA的第一步是让AI看懂世界,那第二步就是让AI学会「做计划」——这要归功于动作变量的引入。
早期的JEPA模型只能预测静态或动态的视觉特征,就像一个只会看电影的观众,能说出下一个镜头会出现什么,但不知道怎么改变剧情。而ACT-JEPA和V-JEPA 2.1引入了动作序列变量后,AI终于从观众变成了编剧:它不仅能预测「如果推杯子,杯子会移动」,还能规划出「先伸手,再握住杯柄,最后平移到桌面另一侧」的完整动作链。
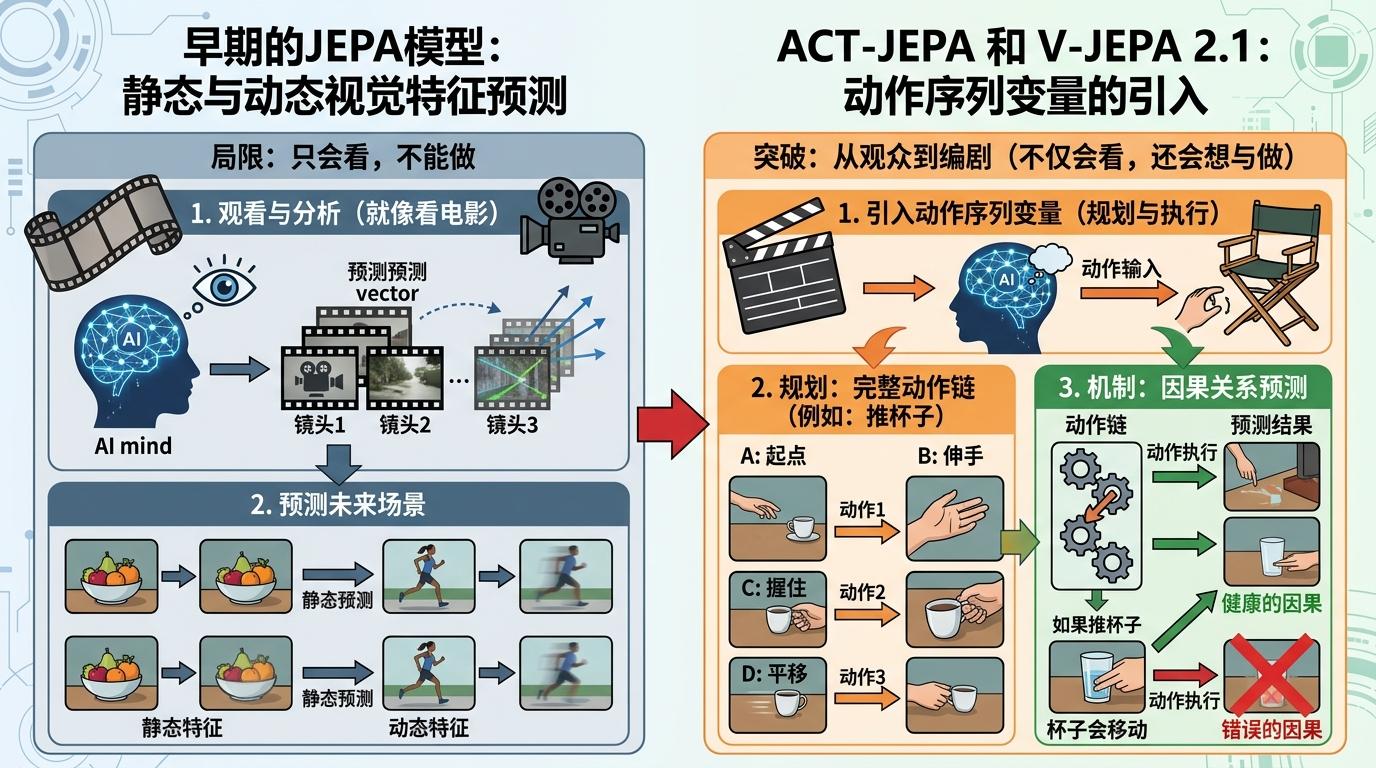
这种端到端的规划能力有多厉害?V-JEPA 2.1只需要62小时的机器人视频数据微调,就能在完全陌生的环境里完成抓举、移动、放置物品的任务,成功率达到65%-80%。对比之下,传统的机器人学习往往需要在特定环境里反复试错,稍有场景变化就会失效。

更关键的是效率提升:LeWorldModel用1500万参数实现了比传统大模型快48倍的规划速度,单张GPU几小时就能完成训练。这意味着AI终于能像人类一样,在脑子里快速推演各种可能性,而不是在现实世界里一次次试错。
JEPA架构的突破让人兴奋,但它离真正的通用智能还有三道坎。
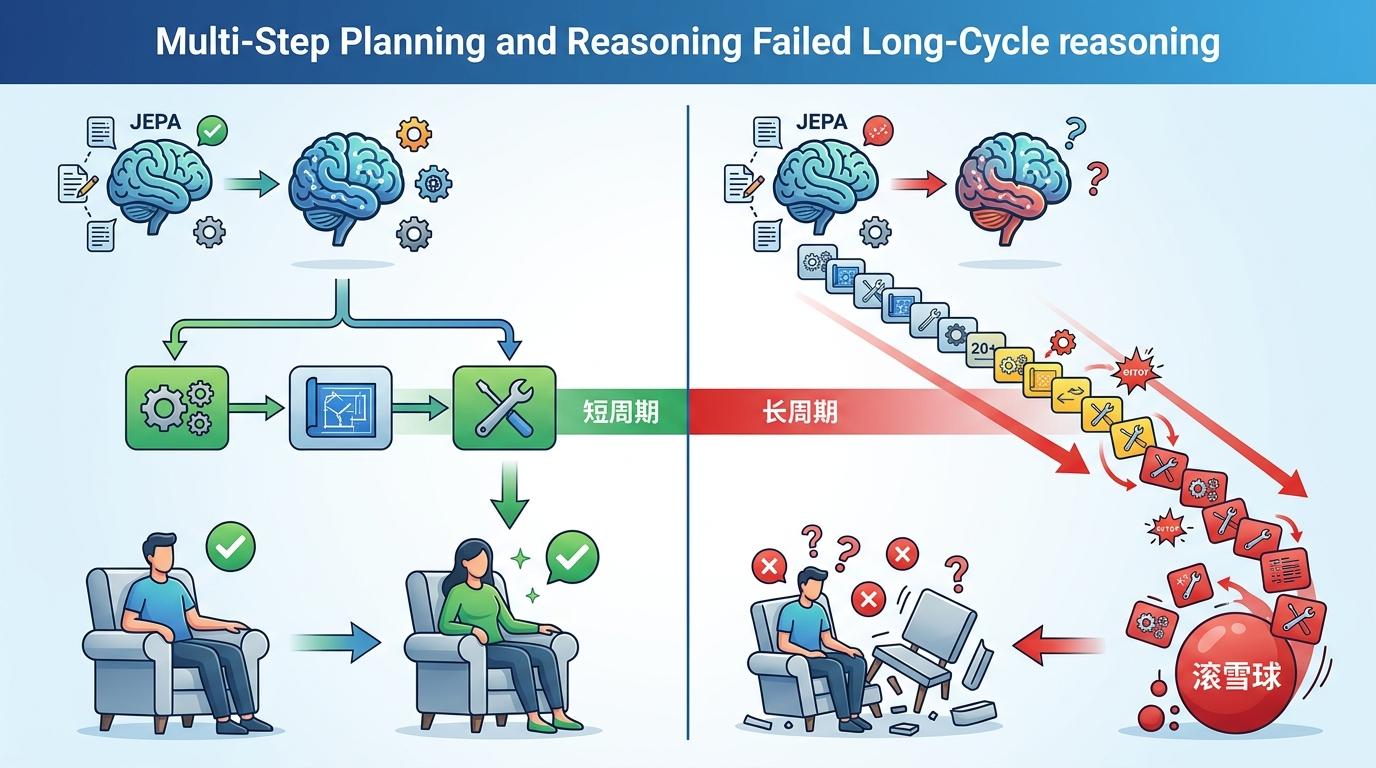
第一道坎是长周期推理。目前的JEPA模型能完成几步到十几步的动作规划,但面对需要几十步甚至上百步的复杂任务——比如组装一台家具,误差就会像滚雪球一样累积。就像你能算出1+1=2,但让你心算100位数的乘法,很容易出错。
第二道坎是数据泛化。JEPA模型虽然能在陌生环境里工作,但它的泛化能力依然依赖于训练数据的多样性。如果训练数据里没有出现过「带把手的陶罐」,它可能就不知道怎么抓举。这就像一个只见过杯子的人,第一次看到陶罐时,需要花时间适应它的形状。
第三道坎是因果理解。JEPA模型能学会「推杯子会导致杯子移动」,但它不一定理解「为什么」——它只是从数据里学到了这个关联,而不是真正理解重力和摩擦力的作用。这就像一个孩子知道按开关会开灯,但不知道电是怎么流动的。
当AI不再执着于复刻像素,它终于开始触摸到智能的本质——不是对细节的精确还原,而是对规律的抽象理解。JEPA架构的意义,不在于它让AI完成了多少具体任务,而在于它为AI指出了一条更接近人类认知的道路。
未来的AI,可能不需要记住每一片树叶的形状,但它会知道树叶会因为风而晃动;它不需要还原每一个像素的颜色,但它会知道火焰是热的,冰是冷的。智能的本质,从来不是复刻,而是理解。
这或许就是LeCun团队坚持的意义:他们不想让AI成为一个只会抄作业的学生,而是要让它成为能探索世界规律的研究者。